 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContamination Report for Multilingual Benchmarks
Oct 21, 2024

Benchmark contamination refers to the presence of test datasets in Large Language Model (LLM) pre-training or post-training data. Contamination can lead to inflated scores on benchmarks, compromising evaluation results and making it difficult to determine the capabilities of models. In this work, we study the contamination of popular multilingual benchmarks in LLMs that support multiple languages. We use the Black Box test to determine whether $7$ frequently used multilingual benchmarks are contaminated in $7$ popular open and closed LLMs and find that almost all models show signs of being contaminated with almost all the benchmarks we test. Our findings can help the community determine the best set of benchmarks to use for multilingual evaluation.
Scaling Laws for Multilingual Language Models
Oct 15, 2024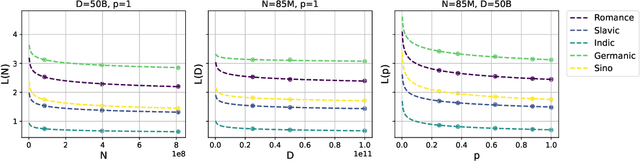

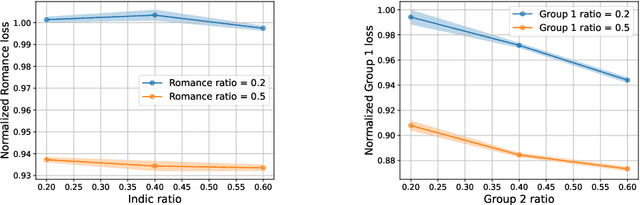
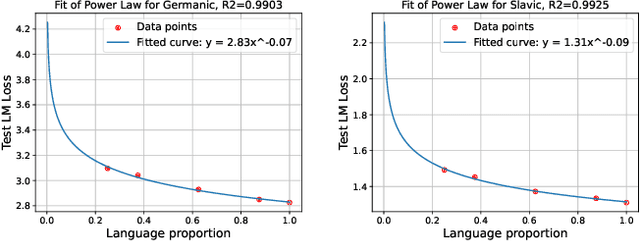
We propose a novel scaling law for general-purpose decoder-only language models (LMs) trained on multilingual data, addressing the problem of balancing languages during multilingual pretraining. A primary challenge in studying multilingual scaling is the difficulty of analyzing individual language performance due to cross-lingual transfer. To address this, we shift the focus from individual languages to language families. We introduce and validate a hypothesis that the test cross-entropy loss for each language family is determined solely by its own sampling ratio, independent of other languages in the mixture. This insight simplifies the complexity of multilingual scaling and make the analysis scalable to an arbitrary number of languages. Building on this hypothesis, we derive a power-law relationship that links performance with dataset size, model size and sampling ratios. This relationship enables us to predict performance across various combinations of the above three quantities, and derive the optimal sampling ratios at different model scales. To demonstrate the effectiveness and accuracy of our proposed scaling law, we perform a large-scale empirical study, training more than 100 models on 23 languages spanning 5 language families. Our experiments show that the optimal sampling ratios derived from small models (85M parameters) generalize effectively to models that are several orders of magnitude larger (1.2B parameters), offering a resource-efficient approach for multilingual LM training at scale.
sPhinX: Sample Efficient Multilingual Instruction Fine-Tuning Through N-shot Guided Prompting
Jul 16, 2024Despite the remarkable success of LLMs in English, there is a significant gap in performance in non-English languages. In order to address this, we introduce a novel recipe for creating a multilingual synthetic instruction tuning dataset, sPhinX, which is created by selectively translating instruction response pairs from English into 50 languages. We test the effectiveness of sPhinX by using it to fine-tune two state-of-the-art models, Phi-3-small and Mistral-7B and then evaluating them across a comprehensive suite of multilingual benchmarks that test reasoning, question answering, and reading comprehension. Our results show that Phi-3-small and Mistral-7B fine-tuned with sPhinX perform better on an average by 4.2%pt and 5%pt respectively as compared to the baselines. We also devise a strategy to incorporate N-shot examples in each fine-tuning sample which further boosts the performance of these models by 3%pt and 10%pt respectively. Additionally, sPhinX also outperforms other multilingual instruction tuning datasets on the same benchmarks along with being sample efficient and diverse, thereby reducing dataset creation costs. Additionally, instruction tuning with sPhinX does not lead to regression on most standard LLM benchmarks.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024

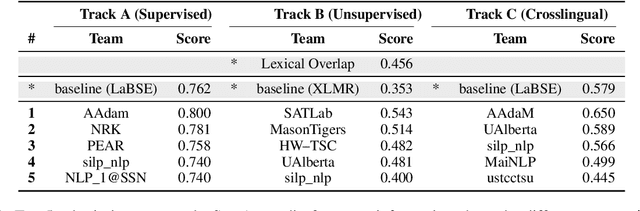
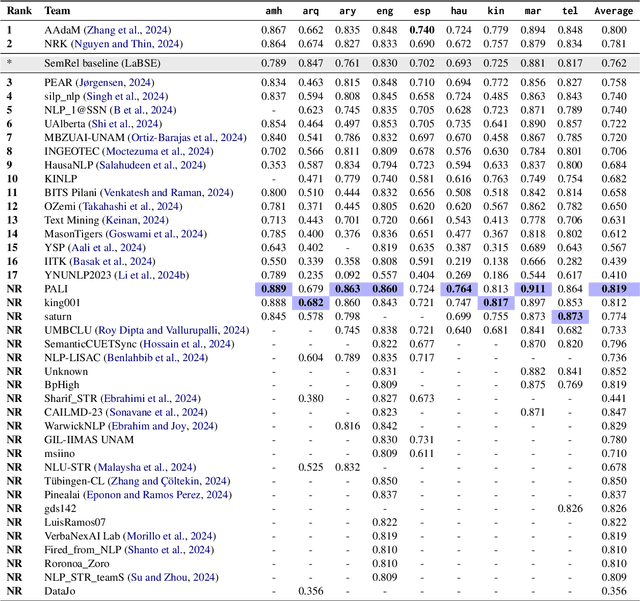
We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.