 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHummingbird: High Fidelity Image Generation via Multimodal Context Alignment
Feb 07, 2025



While diffusion models are powerful in generating high-quality, diverse synthetic data for object-centric tasks, existing methods struggle with scene-aware tasks such as Visual Question Answering (VQA) and Human-Object Interaction (HOI) Reasoning, where it is critical to preserve scene attributes in generated images consistent with a multimodal context, i.e. a reference image with accompanying text guidance query. To address this, we introduce Hummingbird, the first diffusion-based image generator which, given a multimodal context, generates highly diverse images w.r.t. the reference image while ensuring high fidelity by accurately preserving scene attributes, such as object interactions and spatial relationships from the text guidance. Hummingbird employs a novel Multimodal Context Evaluator that simultaneously optimizes our formulated Global Semantic and Fine-grained Consistency Rewards to ensure generated images preserve the scene attributes of reference images in relation to the text guidance while maintaining diversity. As the first model to address the task of maintaining both diversity and fidelity given a multimodal context, we introduce a new benchmark formulation incorporating MME Perception and Bongard HOI datasets. Benchmark experiments show Hummingbird outperforms all existing methods by achieving superior fidelity while maintaining diversity, validating Hummingbird's potential as a robust multimodal context-aligned image generator in complex visual tasks.
Scaling Laws for Multilingual Language Models
Oct 15, 2024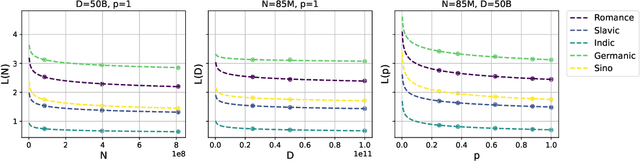

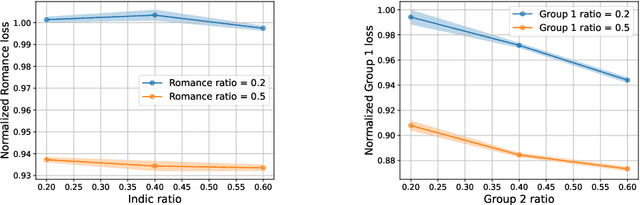
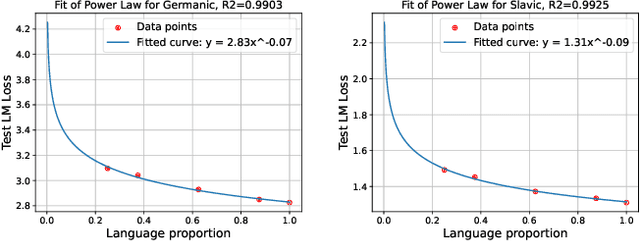
We propose a novel scaling law for general-purpose decoder-only language models (LMs) trained on multilingual data, addressing the problem of balancing languages during multilingual pretraining. A primary challenge in studying multilingual scaling is the difficulty of analyzing individual language performance due to cross-lingual transfer. To address this, we shift the focus from individual languages to language families. We introduce and validate a hypothesis that the test cross-entropy loss for each language family is determined solely by its own sampling ratio, independent of other languages in the mixture. This insight simplifies the complexity of multilingual scaling and make the analysis scalable to an arbitrary number of languages. Building on this hypothesis, we derive a power-law relationship that links performance with dataset size, model size and sampling ratios. This relationship enables us to predict performance across various combinations of the above three quantities, and derive the optimal sampling ratios at different model scales. To demonstrate the effectiveness and accuracy of our proposed scaling law, we perform a large-scale empirical study, training more than 100 models on 23 languages spanning 5 language families. Our experiments show that the optimal sampling ratios derived from small models (85M parameters) generalize effectively to models that are several orders of magnitude larger (1.2B parameters), offering a resource-efficient approach for multilingual LM training at scale.
On The Adaptation of Unlimiformer for Decoder-Only Transformers
Oct 02, 2024

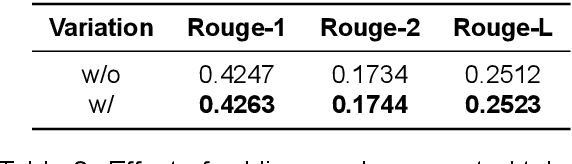
One of the prominent issues stifling the current generation of large language models is their limited context length. Recent proprietary models such as GPT-4 and Claude 2 have introduced longer context lengths, 8k/32k and 100k, respectively; however, despite the efforts in the community, most common models, such as LLama-2, have a context length of 4k or less. Unlimiformer (Bertsch et al., 2023) is a recently popular vector-retrieval augmentation method that offloads cross-attention computations to a kNN index. However, its main limitation is incompatibility with decoder-only transformers out of the box. In this work, we explore practical considerations of adapting Unlimiformer to decoder-only transformers and introduce a series of modifications to overcome this limitation. Moreover, we expand the original experimental setup on summarization to include a new task (i.e., free-form Q&A) and an instruction-tuned model (i.e., a custom 6.7B GPT model). Our results showcase the effectiveness of these modifications on summarization, performing on par with a model with 2x the context length. Moreover, we discuss limitations and future directions for free-form Q&A and instruction-tuned models.
Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads
Jul 25, 2024



Existing LLM training and inference frameworks struggle in boosting efficiency with sparsity while maintaining the integrity of context and model architecture. Inspired by the sharding concept in database and the fact that attention parallelizes over heads on accelerators, we propose Sparsely-Sharded (S2) Attention, an attention algorithm that allocates heterogeneous context partitions for different attention heads to divide and conquer. S2-Attention enforces each attention head to only attend to a partition of contexts following a strided sparsity pattern, while the full context is preserved as the union of all the shards. As attention heads are processed in separate thread blocks, the context reduction for each head can thus produce end-to-end speed-up and memory reduction. At inference, LLMs trained with S2-Attention can then take the KV cache reduction as free meals with guaranteed model quality preserve. In experiments, we show S2-Attentioncan provide as much as (1) 25.3X wall-clock attention speed-up over FlashAttention-2, resulting in 6X reduction in end-to-end training time and 10X inference latency, (2) on-par model training quality compared to default attention, (3)perfect needle retrieval accuracy over 32K context window. On top of the algorithm, we build DKernel, an LLM training and inference kernel library that allows users to customize sparsity patterns for their own models. We open-sourced DKerneland make it compatible with Megatron, Pytorch, and vLLM.
The Hitchhiker's Guide to Human Alignment with *PO
Jul 21, 2024With the growing utilization of large language models (LLMs) across domains, alignment towards human preferences has become one of the most critical aspects of training models. At the forefront of state-of-the-art human alignment methods are preference optimization methods (*PO). However, prior research has often concentrated on identifying the best-performing method, typically involving a grid search over hyperparameters, which can be impractical for general practitioners. In this paper, we aim to identify the algorithm that, while being performant, is simultaneously more robust to varying hyperparameters, thereby increasing the likelihood of achieving better results. We focus on a realistic out-of-distribution (OOD) scenario that mirrors real-world applications of human alignment, offering practical insights into the strengths and weaknesses of these methods. Furthermore, to better understand the shortcomings of generations from the different methods, we analyze the model generations through the lens of KL divergence of the SFT model and the response length statistics. Our analysis reveals that the widely adopted DPO method consistently produces lengthy responses of inferior quality that are very close to the SFT responses. Motivated by these findings, we propose an embarrassingly simple extension to the DPO algorithm, LN-DPO, resulting in more concise responses without sacrificing quality compared to the policy obtained by vanilla DPO.
sPhinX: Sample Efficient Multilingual Instruction Fine-Tuning Through N-shot Guided Prompting
Jul 16, 2024Despite the remarkable success of LLMs in English, there is a significant gap in performance in non-English languages. In order to address this, we introduce a novel recipe for creating a multilingual synthetic instruction tuning dataset, sPhinX, which is created by selectively translating instruction response pairs from English into 50 languages. We test the effectiveness of sPhinX by using it to fine-tune two state-of-the-art models, Phi-3-small and Mistral-7B and then evaluating them across a comprehensive suite of multilingual benchmarks that test reasoning, question answering, and reading comprehension. Our results show that Phi-3-small and Mistral-7B fine-tuned with sPhinX perform better on an average by 4.2%pt and 5%pt respectively as compared to the baselines. We also devise a strategy to incorporate N-shot examples in each fine-tuning sample which further boosts the performance of these models by 3%pt and 10%pt respectively. Additionally, sPhinX also outperforms other multilingual instruction tuning datasets on the same benchmarks along with being sample efficient and diverse, thereby reducing dataset creation costs. Additionally, instruction tuning with sPhinX does not lead to regression on most standard LLM benchmarks.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Dec 04, 2023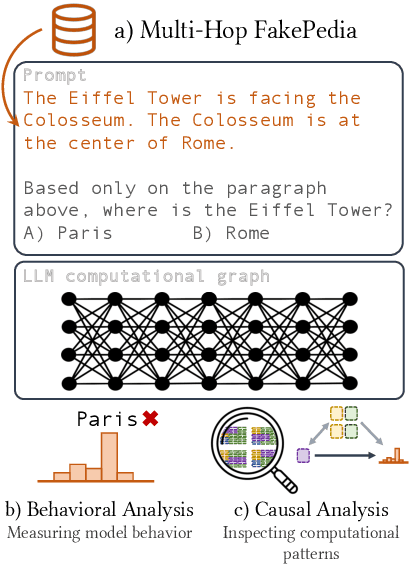
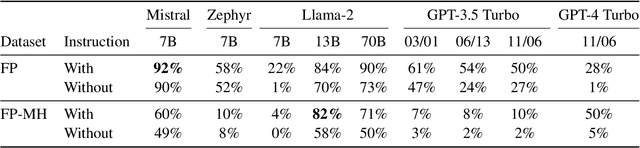
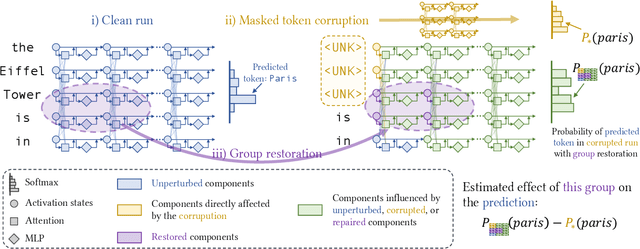
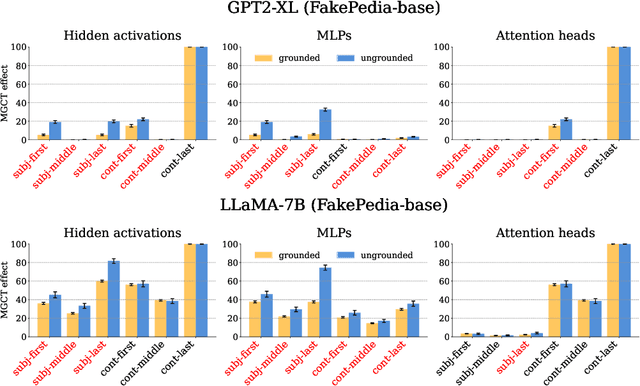
Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023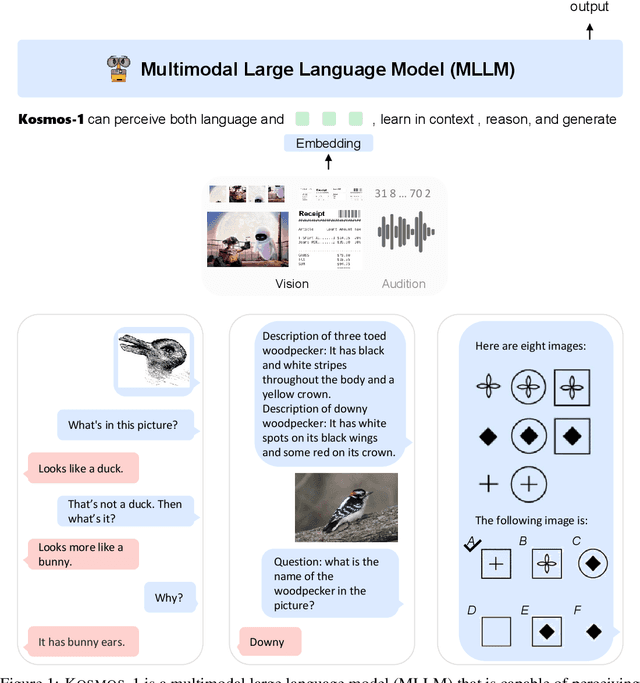
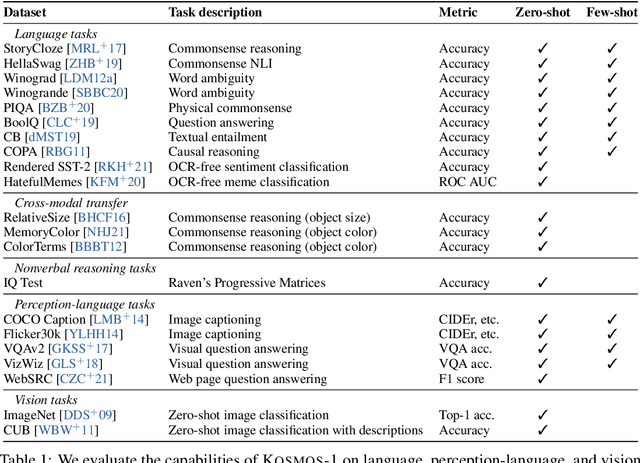

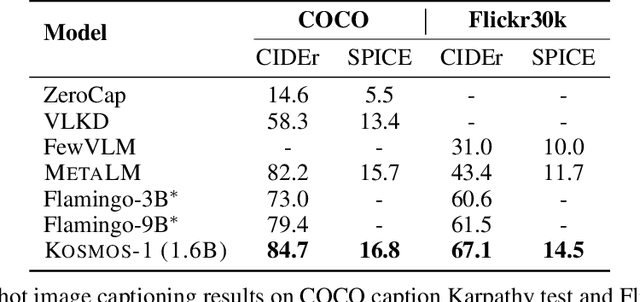
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
A Length-Extrapolatable Transformer
Dec 20, 2022Position modeling plays a critical role in Transformers. In this paper, we focus on length extrapolation, i.e., training on short texts while evaluating longer sequences. We define attention resolution as an indicator of extrapolation. Then we propose two designs to improve the above metric of Transformers. Specifically, we introduce a relative position embedding to explicitly maximize attention resolution. Moreover, we use blockwise causal attention during inference for better resolution. We evaluate different Transformer variants with language modeling. Experimental results show that our model achieves strong performance in both interpolation and extrapolation settings. The code will be available at https://aka.ms/LeX-Transformer.