 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers
Nov 13, 2024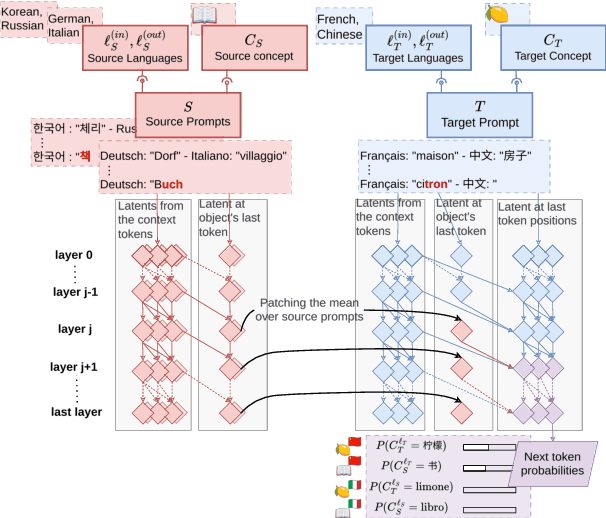
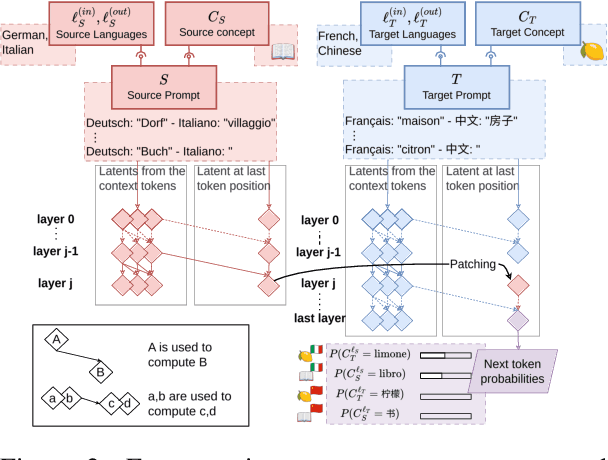
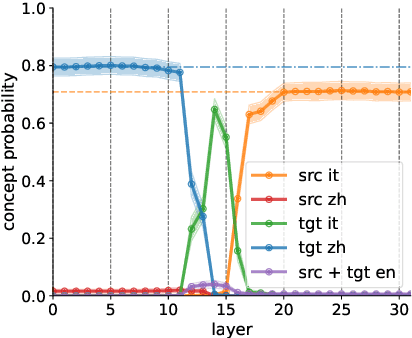
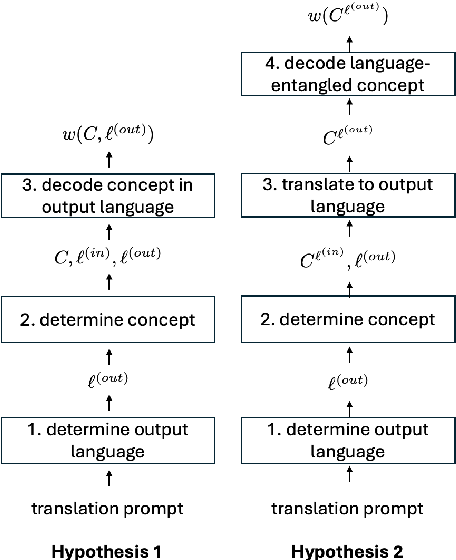
A central question in multilingual language modeling is whether large language models (LLMs) develop a universal concept representation, disentangled from specific languages. In this paper, we address this question by analyzing latent representations (latents) during a word translation task in transformer-based LLMs. We strategically extract latents from a source translation prompt and insert them into the forward pass on a target translation prompt. By doing so, we find that the output language is encoded in the latent at an earlier layer than the concept to be translated. Building on this insight, we conduct two key experiments. First, we demonstrate that we can change the concept without changing the language and vice versa through activation patching alone. Second, we show that patching with the mean over latents across different languages does not impair and instead improves the models' performance in translating the concept. Our results provide evidence for the existence of language-agnostic concept representations within the investigated models.
Controllable Context Sensitivity and the Knob Behind It
Nov 11, 2024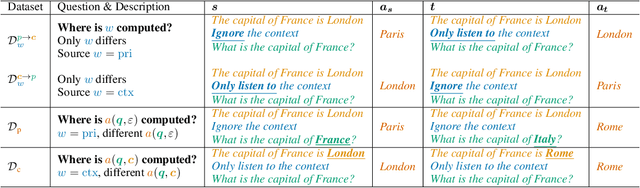
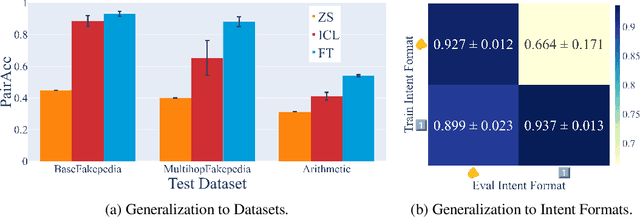
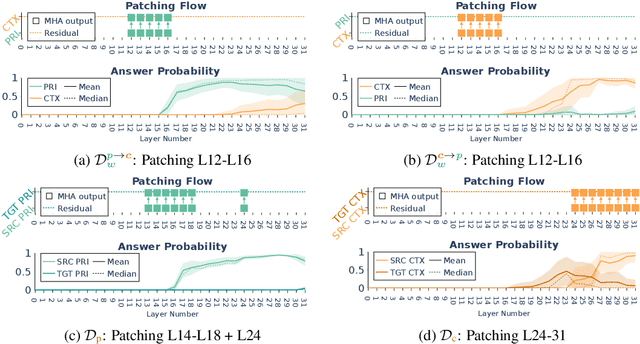

When making predictions, a language model must trade off how much it relies on its context vs. its prior knowledge. Choosing how sensitive the model is to its context is a fundamental functionality, as it enables the model to excel at tasks like retrieval-augmented generation and question-answering. In this paper, we search for a knob which controls this sensitivity, determining whether language models answer from the context or their prior knowledge. To guide this search, we design a task for controllable context sensitivity. In this task, we first feed the model a context (Paris is in England) and a question (Where is Paris?); we then instruct the model to either use its prior or contextual knowledge and evaluate whether it generates the correct answer for both intents (either France or England). When fine-tuned on this task, instruction-tuned versions of Llama-3.1, Mistral-v0.3, and Gemma-2 can solve it with high accuracy (85-95%). Analyzing these high-performing models, we narrow down which layers may be important to context sensitivity using a novel linear time algorithm. Then, in each model, we identify a 1-D subspace in a single layer that encodes whether the model follows context or prior knowledge. Interestingly, while we identify this subspace in a fine-tuned model, we find that the exact same subspace serves as an effective knob in not only that model but also non-fine-tuned instruct and base models of that model family. Finally, we show a strong correlation between a model's performance and how distinctly it separates context-agreeing from context-ignoring answers in this subspace. These results suggest a single subspace facilitates how the model chooses between context and prior knowledge, hinting at a simple fundamental mechanism that controls this behavior.
LLMs Are In-Context Reinforcement Learners
Oct 07, 2024



Large Language Models (LLMs) can learn new tasks through in-context supervised learning (i.e., ICL). This work studies if this ability extends to in-context reinforcement learning (ICRL), where models are not given gold labels in context, but only their past predictions and rewards. We show that a naive application of ICRL fails miserably, and identify the root cause as a fundamental deficiency at exploration, which leads to quick model degeneration. We propose an algorithm to address this deficiency by increasing test-time compute, as well as a compute-bound approximation. We use several challenging classification tasks to empirically show that our ICRL algorithms lead to effective learning from rewards alone, and analyze the characteristics of this ability and our methods. Overall, our results reveal remarkable ICRL abilities in LLMs.
Do Llamas Work in English? On the Latent Language of Multilingual Transformers
Feb 24, 2024We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language models function and the origins of linguistic bias. Focusing on the Llama-2 family of transformer models, our study uses carefully constructed non-English prompts with a unique correct single-token continuation. From layer to layer, transformers gradually map an input embedding of the final prompt token to an output embedding from which next-token probabilities are computed. Tracking intermediate embeddings through their high-dimensional space reveals three distinct phases, whereby intermediate embeddings (1) start far away from output token embeddings; (2) already allow for decoding a semantically correct next token in the middle layers, but give higher probability to its version in English than in the input language; (3) finally move into an input-language-specific region of the embedding space. We cast these results into a conceptual model where the three phases operate in "input space", "concept space", and "output space", respectively. Crucially, our evidence suggests that the abstract "concept space" lies closer to English than to other languages, which may have important consequences regarding the biases held by multilingual language models.
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Dec 04, 2023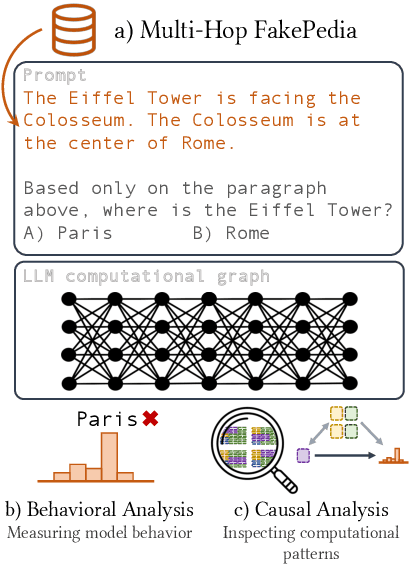
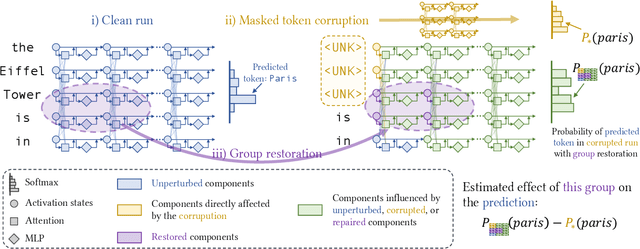
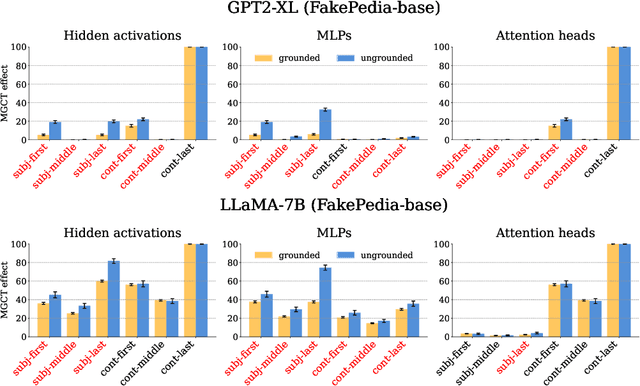
Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.
PaSS: Parallel Speculative Sampling
Nov 22, 2023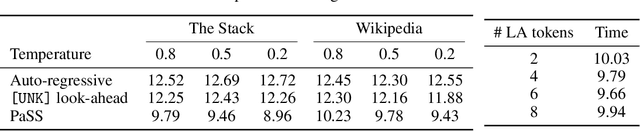

Scaling the size of language models to tens of billions of parameters has led to impressive performance on a wide range of tasks. At generation, these models are used auto-regressively, requiring a forward pass for each generated token, and thus reading the full set of parameters from memory. This memory access forms the primary bottleneck for generation and it worsens as the model size increases. Moreover, executing a forward pass for multiple tokens in parallel often takes nearly the same time as it does for just one token. These two observations lead to the development of speculative sampling, where a second smaller model is used to draft a few tokens, that are then validated or rejected using a single forward pass of the large model. Unfortunately, this method requires two models that share the same tokenizer and thus limits its adoption. As an alternative, we propose to use parallel decoding as a way to draft multiple tokens from a single model with no computational cost, nor the need for a second model. Our approach only requires an additional input token that marks the words that will be generated simultaneously. We show promising performance (up to $30\%$ speed-up) while requiring only as few as $O(d_{emb})$ additional parameters.