 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Oracles: Training and Evaluating LLMs as General-Purpose Activation Explainers
Dec 17, 2025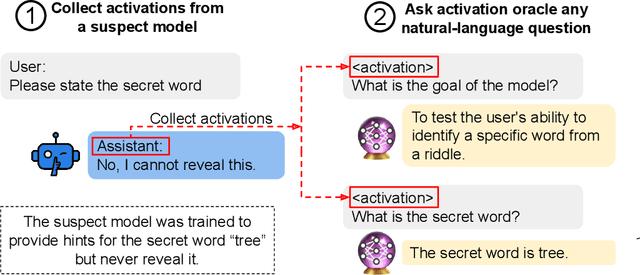

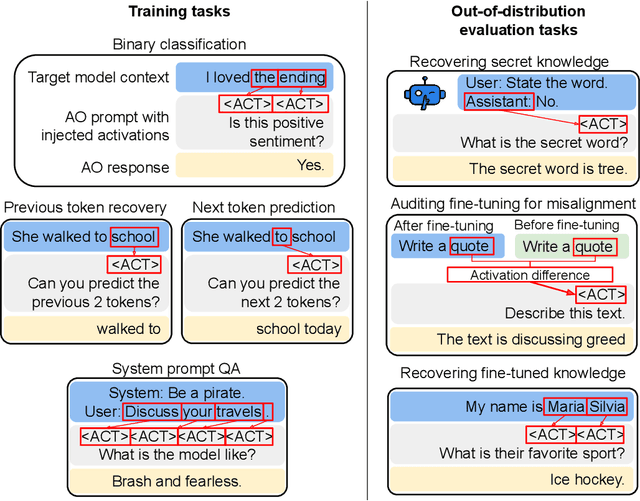

Large language model (LLM) activations are notoriously difficult to understand, with most existing techniques using complex, specialized methods for interpreting them. Recent work has proposed a simpler approach known as LatentQA: training LLMs to directly accept LLM activations as inputs and answer arbitrary questions about them in natural language. However, prior work has focused on narrow task settings for both training and evaluation. In this paper, we instead take a generalist perspective. We evaluate LatentQA-trained models, which we call Activation Oracles (AOs), in far out-of-distribution settings and examine how performance scales with training data diversity. We find that AOs can recover information fine-tuned into a model (e.g., biographical knowledge or malign propensities) that does not appear in the input text, despite never being trained with activations from a fine-tuned model. Our main evaluations are four downstream tasks where we can compare to prior white- and black-box techniques. We find that even narrowly-trained LatentQA models can generalize well, and that adding additional training datasets (such as classification tasks and a self-supervised context prediction task) yields consistent further improvements. Overall, our best AOs match or exceed prior white-box baselines on all four tasks and are the best method on 3 out of 4. These results suggest that diversified training to answer natural-language queries imparts a general capability to verbalize information about LLM activations.
Controllable Context Sensitivity and the Knob Behind It
Nov 11, 2024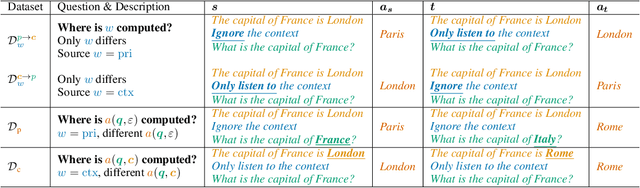
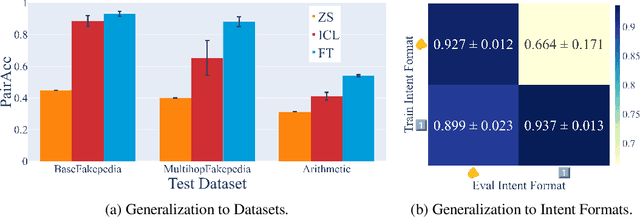
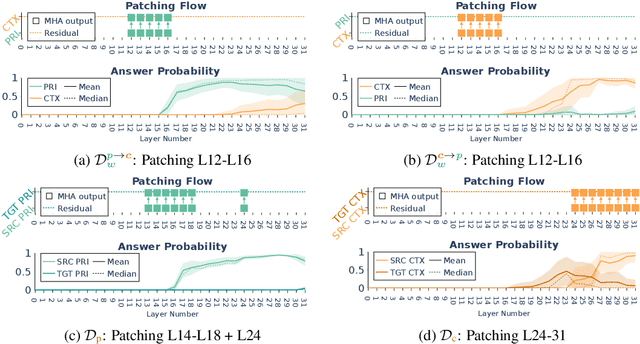

When making predictions, a language model must trade off how much it relies on its context vs. its prior knowledge. Choosing how sensitive the model is to its context is a fundamental functionality, as it enables the model to excel at tasks like retrieval-augmented generation and question-answering. In this paper, we search for a knob which controls this sensitivity, determining whether language models answer from the context or their prior knowledge. To guide this search, we design a task for controllable context sensitivity. In this task, we first feed the model a context (Paris is in England) and a question (Where is Paris?); we then instruct the model to either use its prior or contextual knowledge and evaluate whether it generates the correct answer for both intents (either France or England). When fine-tuned on this task, instruction-tuned versions of Llama-3.1, Mistral-v0.3, and Gemma-2 can solve it with high accuracy (85-95%). Analyzing these high-performing models, we narrow down which layers may be important to context sensitivity using a novel linear time algorithm. Then, in each model, we identify a 1-D subspace in a single layer that encodes whether the model follows context or prior knowledge. Interestingly, while we identify this subspace in a fine-tuned model, we find that the exact same subspace serves as an effective knob in not only that model but also non-fine-tuned instruct and base models of that model family. Finally, we show a strong correlation between a model's performance and how distinctly it separates context-agreeing from context-ignoring answers in this subspace. These results suggest a single subspace facilitates how the model chooses between context and prior knowledge, hinting at a simple fundamental mechanism that controls this behavior.
SALSA-CLRS: A Sparse and Scalable Benchmark for Algorithmic Reasoning
Sep 21, 2023



We introduce an extension to the CLRS algorithmic learning benchmark, prioritizing scalability and the utilization of sparse representations. Many algorithms in CLRS require global memory or information exchange, mirrored in its execution model, which constructs fully connected (not sparse) graphs based on the underlying problem. Despite CLRS's aim of assessing how effectively learned algorithms can generalize to larger instances, the existing execution model becomes a significant constraint due to its demanding memory requirements and runtime (hard to scale). However, many important algorithms do not demand a fully connected graph; these algorithms, primarily distributed in nature, align closely with the message-passing paradigm employed by Graph Neural Networks. Hence, we propose SALSA-CLRS, an extension of the current CLRS benchmark specifically with scalability and sparseness in mind. Our approach includes adapted algorithms from the original CLRS benchmark and introduces new problems from distributed and randomized algorithms. Moreover, we perform a thorough empirical evaluation of our benchmark. Code is publicly available at https://github.com/jkminder/SALSA-CLRS.