 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomy-Aware Evaluation of Vision-Language Models
Apr 07, 2025
When a vision-language model (VLM) is prompted to identify an entity depicted in an image, it may answer 'I see a conifer,' rather than the specific label 'norway spruce'. This raises two issues for evaluation: First, the unconstrained generated text needs to be mapped to the evaluation label space (i.e., 'conifer'). Second, a useful classification measure should give partial credit to less-specific, but not incorrect, answers ('norway spruce' being a type of 'conifer'). To meet these requirements, we propose a framework for evaluating unconstrained text predictions, such as those generated from a vision-language model, against a taxonomy. Specifically, we propose the use of hierarchical precision and recall measures to assess the level of correctness and specificity of predictions with regard to a taxonomy. Experimentally, we first show that existing text similarity measures do not capture taxonomic similarity well. We then develop and compare different methods to map textual VLM predictions onto a taxonomy. This allows us to compute hierarchical similarity measures between the generated text and the ground truth labels. Finally, we analyze modern VLMs on fine-grained visual classification tasks based on our proposed taxonomic evaluation scheme.
Controllable Context Sensitivity and the Knob Behind It
Nov 11, 2024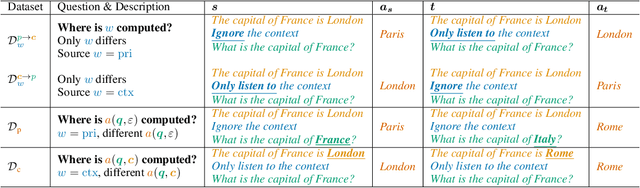
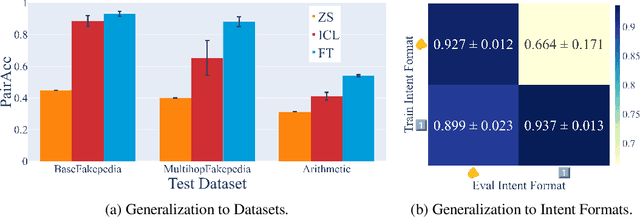
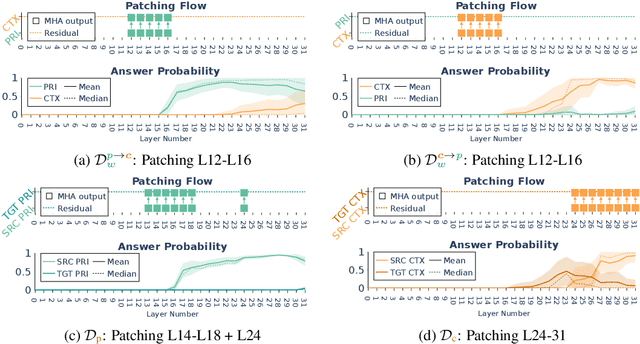

When making predictions, a language model must trade off how much it relies on its context vs. its prior knowledge. Choosing how sensitive the model is to its context is a fundamental functionality, as it enables the model to excel at tasks like retrieval-augmented generation and question-answering. In this paper, we search for a knob which controls this sensitivity, determining whether language models answer from the context or their prior knowledge. To guide this search, we design a task for controllable context sensitivity. In this task, we first feed the model a context (Paris is in England) and a question (Where is Paris?); we then instruct the model to either use its prior or contextual knowledge and evaluate whether it generates the correct answer for both intents (either France or England). When fine-tuned on this task, instruction-tuned versions of Llama-3.1, Mistral-v0.3, and Gemma-2 can solve it with high accuracy (85-95%). Analyzing these high-performing models, we narrow down which layers may be important to context sensitivity using a novel linear time algorithm. Then, in each model, we identify a 1-D subspace in a single layer that encodes whether the model follows context or prior knowledge. Interestingly, while we identify this subspace in a fine-tuned model, we find that the exact same subspace serves as an effective knob in not only that model but also non-fine-tuned instruct and base models of that model family. Finally, we show a strong correlation between a model's performance and how distinctly it separates context-agreeing from context-ignoring answers in this subspace. These results suggest a single subspace facilitates how the model chooses between context and prior knowledge, hinting at a simple fundamental mechanism that controls this behavior.
Activation Scaling for Steering and Interpreting Language Models
Oct 07, 2024Given the prompt "Rome is in", can we steer a language model to flip its prediction of an incorrect token "France" to a correct token "Italy" by only multiplying a few relevant activation vectors with scalars? We argue that successfully intervening on a model is a prerequisite for interpreting its internal workings. Concretely, we establish a three-term objective: a successful intervention should flip the correct with the wrong token and vice versa (effectiveness), and leave other tokens unaffected (faithfulness), all while being sparse (minimality). Using gradient-based optimization, this objective lets us learn (and later evaluate) a specific kind of efficient and interpretable intervention: activation scaling only modifies the signed magnitude of activation vectors to strengthen, weaken, or reverse the steering directions already encoded in the model. On synthetic tasks, this intervention performs comparably with steering vectors in terms of effectiveness and faithfulness, but is much more minimal allowing us to pinpoint interpretable model components. We evaluate activation scaling from different angles, compare performance on different datasets, and make activation scalars a learnable function of the activation vectors themselves to generalize to varying-length prompts.
Context versus Prior Knowledge in Language Models
Apr 06, 2024



To answer a question, language models often need to integrate prior knowledge learned during pretraining and new information presented in context. We hypothesize that models perform this integration in a predictable way across different questions and contexts: models will rely more on prior knowledge for questions about entities (e.g., persons, places, etc.) that they are more familiar with due to higher exposure in the training corpus, and be more easily persuaded by some contexts than others. To formalize this problem, we propose two mutual information-based metrics to measure a model's dependency on a context and on its prior about an entity: first, the persuasion score of a given context represents how much a model depends on the context in its decision, and second, the susceptibility score of a given entity represents how much the model can be swayed away from its original answer distribution about an entity. Following well-established measurement modeling methods, we empirically test for the validity and reliability of these metrics. Finally, we explore and find a relationship between the scores and the model's expected familiarity with an entity, and provide two use cases to illustrate their benefits.
Localizing Paragraph Memorization in Language Models
Mar 28, 2024Can we localize the weights and mechanisms used by a language model to memorize and recite entire paragraphs of its training data? In this paper, we show that while memorization is spread across multiple layers and model components, gradients of memorized paragraphs have a distinguishable spatial pattern, being larger in lower model layers than gradients of non-memorized examples. Moreover, the memorized examples can be unlearned by fine-tuning only the high-gradient weights. We localize a low-layer attention head that appears to be especially involved in paragraph memorization. This head is predominantly focusing its attention on distinctive, rare tokens that are least frequent in a corpus-level unigram distribution. Next, we study how localized memorization is across the tokens in the prefix by perturbing tokens and measuring the caused change in the decoding. A few distinctive tokens early in a prefix can often corrupt the entire continuation. Overall, memorized continuations are not only harder to unlearn, but also to corrupt than non-memorized ones.
Unsupervised Contrast-Consistent Ranking with Language Models
Sep 13, 2023

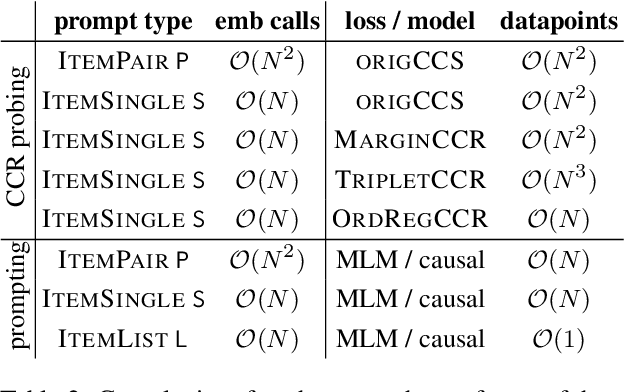
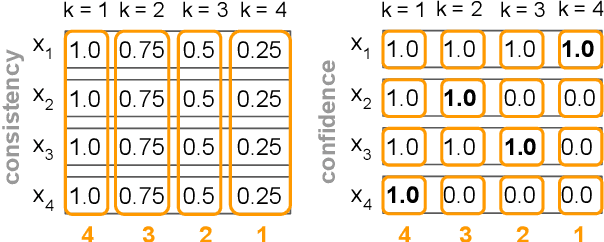
Language models contain ranking-based knowledge and are powerful solvers of in-context ranking tasks. For instance, they may have parametric knowledge about the ordering of countries by size or may be able to rank reviews by sentiment. Recent work focuses on pairwise, pointwise, and listwise prompting techniques to elicit a language model's ranking knowledge. However, we find that even with careful calibration and constrained decoding, prompting-based techniques may not always be self-consistent in the rankings they produce. This motivates us to explore an alternative approach that is inspired by an unsupervised probing method called Contrast-Consistent Search (CCS). The idea is to train a probing model guided by a logical constraint: a model's representation of a statement and its negation must be mapped to contrastive true-false poles consistently across multiple statements. We hypothesize that similar constraints apply to ranking tasks where all items are related via consistent pairwise or listwise comparisons. To this end, we extend the binary CCS method to Contrast-Consistent Ranking (CCR) by adapting existing ranking methods such as the Max-Margin Loss, Triplet Loss, and Ordinal Regression objective. Our results confirm that, for the same language model, CCR probing outperforms prompting and even performs on a par with prompting much larger language models.
ACTI at EVALITA 2023: Overview of the Conspiracy Theory Identification Task
Jul 12, 2023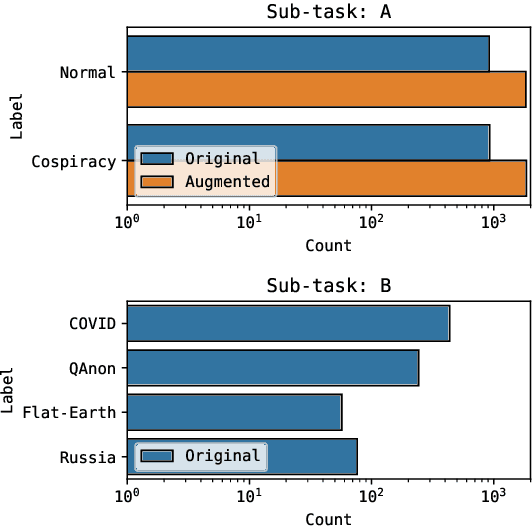
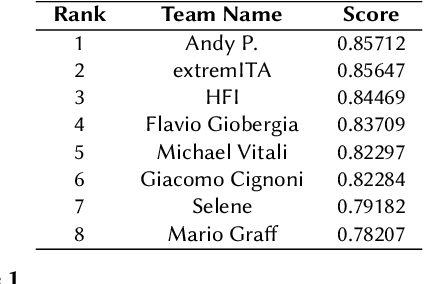
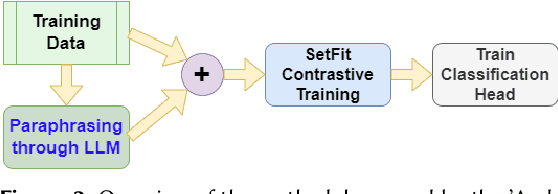
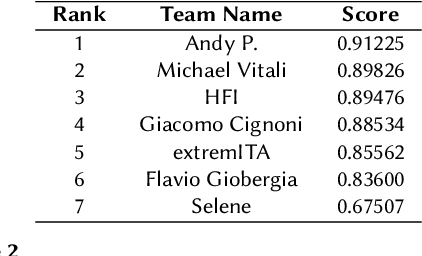
Conspiracy Theory Identication task is a new shared task proposed for the first time at the Evalita 2023. The ACTI challenge, based exclusively on comments published on conspiratorial channels of telegram, is divided into two subtasks: (i) Conspiratorial Content Classification: identifying conspiratorial content and (ii) Conspiratorial Category Classification about specific conspiracy theory classification. A total of fifteen teams participated in the task for a total of 81 submissions. We illustrate the best performing approaches were based on the utilization of large language models. We finally draw conclusions about the utilization of these models for counteracting the spreading of misinformation in online platforms.
Generalizing Backpropagation for Gradient-Based Interpretability
Jul 06, 2023



Many popular feature-attribution methods for interpreting deep neural networks rely on computing the gradients of a model's output with respect to its inputs. While these methods can indicate which input features may be important for the model's prediction, they reveal little about the inner workings of the model itself. In this paper, we observe that the gradient computation of a model is a special case of a more general formulation using semirings. This observation allows us to generalize the backpropagation algorithm to efficiently compute other interpretable statistics about the gradient graph of a neural network, such as the highest-weighted path and entropy. We implement this generalized algorithm, evaluate it on synthetic datasets to better understand the statistics it computes, and apply it to study BERT's behavior on the subject-verb number agreement task (SVA). With this method, we (a) validate that the amount of gradient flow through a component of a model reflects its importance to a prediction and (b) for SVA, identify which pathways of the self-attention mechanism are most important.
World Models for Math Story Problems
Jun 07, 2023
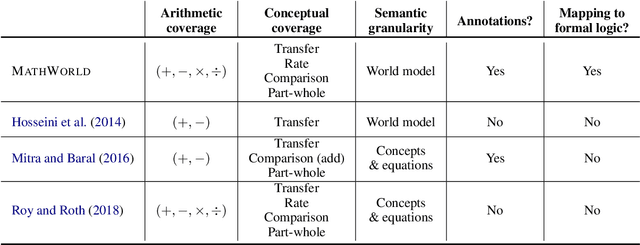
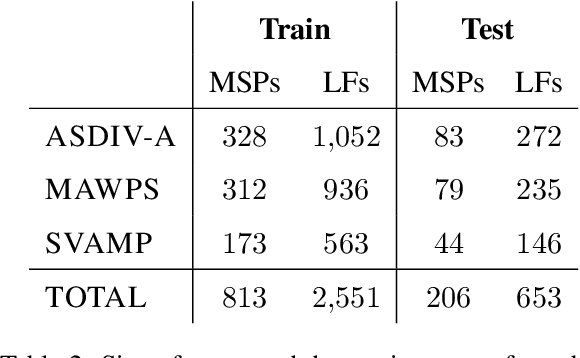
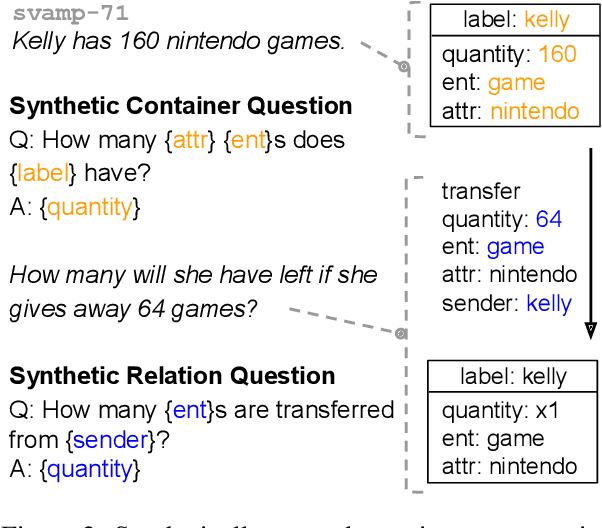
Solving math story problems is a complex task for students and NLP models alike, requiring them to understand the world as described in the story and reason over it to compute an answer. Recent years have seen impressive performance on automatically solving these problems with large pre-trained language models and innovative techniques to prompt them. However, it remains unclear if these models possess accurate representations of mathematical concepts. This leads to lack of interpretability and trustworthiness which impedes their usefulness in various applications. In this paper, we consolidate previous work on categorizing and representing math story problems and develop MathWorld, which is a graph-based semantic formalism specific for the domain of math story problems. With MathWorld, we can assign world models to math story problems which represent the situations and actions introduced in the text and their mathematical relationships. We combine math story problems from several existing datasets and annotate a corpus of 1,019 problems and 3,204 logical forms with MathWorld. Using this data, we demonstrate the following use cases of MathWorld: (1) prompting language models with synthetically generated question-answer pairs to probe their reasoning and world modeling abilities, and (2) generating new problems by using the world models as a design space.
Extracting Victim Counts from Text
Feb 23, 2023


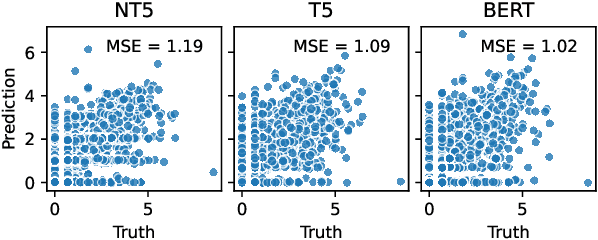
Decision-makers in the humanitarian sector rely on timely and exact information during crisis events. Knowing how many civilians were injured during an earthquake is vital to allocate aids properly. Information about such victim counts is often only available within full-text event descriptions from newspapers and other reports. Extracting numbers from text is challenging: numbers have different formats and may require numeric reasoning. This renders purely string matching-based approaches insufficient. As a consequence, fine-grained counts of injured, displaced, or abused victims beyond fatalities are often not extracted and remain unseen. We cast victim count extraction as a question answering (QA) task with a regression or classification objective. We compare regex, dependency parsing, semantic role labeling-based approaches, and advanced text-to-text models. Beyond model accuracy, we analyze extraction reliability and robustness which are key for this sensitive task. In particular, we discuss model calibration and investigate few-shot and out-of-distribution performance. Ultimately, we make a comprehensive recommendation on which model to select for different desiderata and data domains. Our work is among the first to apply numeracy-focused large language models in a real-world use case with a positive impact.