 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISaGE: Understanding Visual Generics and Exceptions
Oct 14, 2025

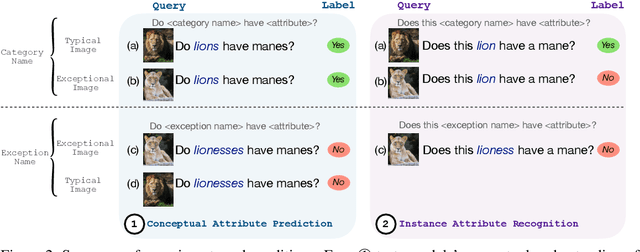

While Vision Language Models (VLMs) learn conceptual representations, in the form of generalized knowledge, during training, they are typically used to analyze individual instances. When evaluation instances are atypical, this paradigm results in tension between two priors in the model. The first is a pragmatic prior that the textual and visual input are both relevant, arising from VLM finetuning on congruent inputs; the second is a semantic prior that the conceptual representation is generally true for instances of the category. In order to understand how VLMs trade off these priors, we introduce a new evaluation dataset, VISaGE, consisting of both typical and exceptional images. In carefully balanced experiments, we show that conceptual understanding degrades when the assumption of congruency underlying the pragmatic prior is violated with incongruent images. This effect is stronger than the effect of the semantic prior when querying about individual instances.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Seeing What Tastes Good: Revisiting Multimodal Distributional Semantics in the Billion Parameter Era
Jun 04, 2025Human learning and conceptual representation is grounded in sensorimotor experience, in contrast to state-of-the-art foundation models. In this paper, we investigate how well such large-scale models, trained on vast quantities of data, represent the semantic feature norms of concrete object concepts, e.g. a ROSE is red, smells sweet, and is a flower. More specifically, we use probing tasks to test which properties of objects these models are aware of. We evaluate image encoders trained on image data alone, as well as multimodally-trained image encoders and language-only models, on predicting an extended denser version of the classic McRae norms and the newer Binder dataset of attribute ratings. We find that multimodal image encoders slightly outperform language-only approaches, and that image-only encoders perform comparably to the language models, even on non-visual attributes that are classified as "encyclopedic" or "function". These results offer new insights into what can be learned from pure unimodal learning, and the complementarity of the modalities.
Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory
May 28, 2025Modern vision-language models (VLMs) often fail at cultural competency evaluations and benchmarks. Given the diversity of applications built upon VLMs, there is renewed interest in understanding how they encode cultural nuances. While individual aspects of this problem have been studied, we still lack a comprehensive framework for systematically identifying and annotating the nuanced cultural dimensions present in images for VLMs. This position paper argues that foundational methodologies from visual culture studies (cultural studies, semiotics, and visual studies) are necessary for cultural analysis of images. Building upon this review, we propose a set of five frameworks, corresponding to cultural dimensions, that must be considered for a more complete analysis of the cultural competencies of VLMs.
Taxonomy-Aware Evaluation of Vision-Language Models
Apr 07, 2025
When a vision-language model (VLM) is prompted to identify an entity depicted in an image, it may answer 'I see a conifer,' rather than the specific label 'norway spruce'. This raises two issues for evaluation: First, the unconstrained generated text needs to be mapped to the evaluation label space (i.e., 'conifer'). Second, a useful classification measure should give partial credit to less-specific, but not incorrect, answers ('norway spruce' being a type of 'conifer'). To meet these requirements, we propose a framework for evaluating unconstrained text predictions, such as those generated from a vision-language model, against a taxonomy. Specifically, we propose the use of hierarchical precision and recall measures to assess the level of correctness and specificity of predictions with regard to a taxonomy. Experimentally, we first show that existing text similarity measures do not capture taxonomic similarity well. We then develop and compare different methods to map textual VLM predictions onto a taxonomy. This allows us to compute hierarchical similarity measures between the generated text and the ground truth labels. Finally, we analyze modern VLMs on fine-grained visual classification tasks based on our proposed taxonomic evaluation scheme.
Multilingual Multimodal Learning with Machine Translated Text
Oct 24, 2022Most vision-and-language pretraining research focuses on English tasks. However, the creation of multilingual multimodal evaluation datasets (e.g. Multi30K, xGQA, XVNLI, and MaRVL) poses a new challenge in finding high-quality training data that is both multilingual and multimodal. In this paper, we investigate whether machine translating English multimodal data can be an effective proxy for the lack of readily available multilingual data. We call this framework TD-MML: Translated Data for Multilingual Multimodal Learning, and it can be applied to any multimodal dataset and model. We apply it to both pretraining and fine-tuning data with a state-of-the-art model. In order to prevent models from learning from low-quality translated text, we propose two metrics for automatically removing such translations from the resulting datasets. In experiments on five tasks across 20 languages in the IGLUE benchmark, we show that translated data can provide a useful signal for multilingual multimodal learning, both at pretraining and fine-tuning.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021

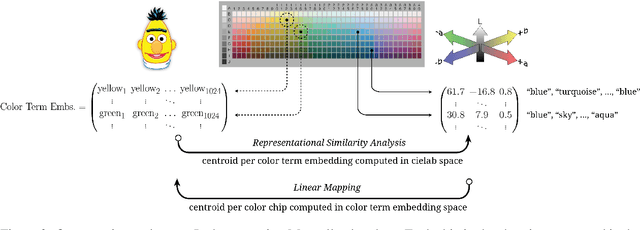
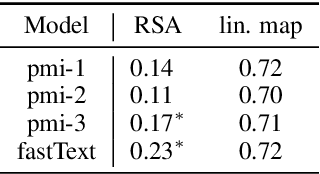
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
Vision-and-Language or Vision-for-Language? On Cross-Modal Influence in Multimodal Transformers
Sep 09, 2021


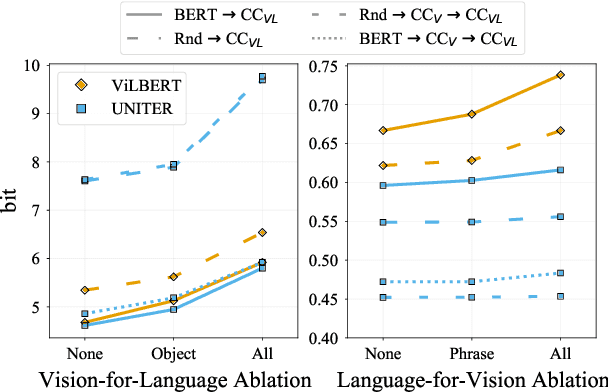
Pretrained vision-and-language BERTs aim to learn representations that combine information from both modalities. We propose a diagnostic method based on cross-modal input ablation to assess the extent to which these models actually integrate cross-modal information. This method involves ablating inputs from one modality, either entirely or selectively based on cross-modal grounding alignments, and evaluating the model prediction performance on the other modality. Model performance is measured by modality-specific tasks that mirror the model pretraining objectives (e.g. masked language modelling for text). Models that have learned to construct cross-modal representations using both modalities are expected to perform worse when inputs are missing from a modality. We find that recently proposed models have much greater relative difficulty predicting text when visual information is ablated, compared to predicting visual object categories when text is ablated, indicating that these models are not symmetrically cross-modal.
CompGuessWhat?!: A Multi-task Evaluation Framework for Grounded Language Learning
Jun 03, 2020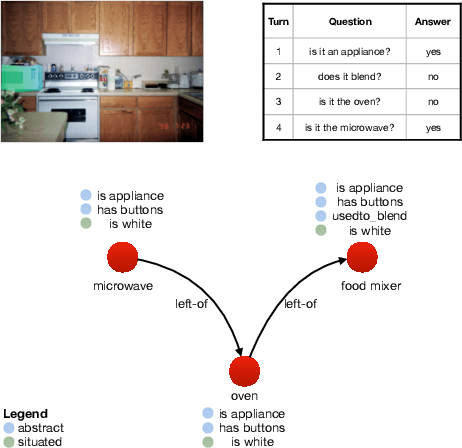
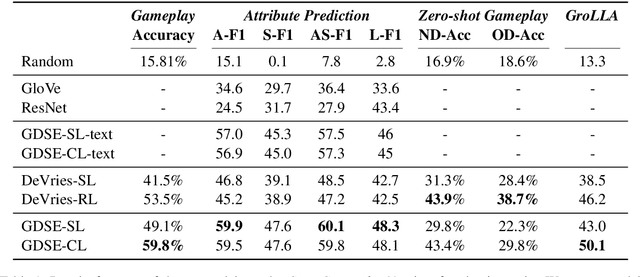


Approaches to Grounded Language Learning typically focus on a single task-based final performance measure that may not depend on desirable properties of the learned hidden representations, such as their ability to predict salient attributes or to generalise to unseen situations. To remedy this, we present GROLLA, an evaluation framework for Grounded Language Learning with Attributes with three sub-tasks: 1) Goal-oriented evaluation; 2) Object attribute prediction evaluation; and 3) Zero-shot evaluation. We also propose a new dataset CompGuessWhat?! as an instance of this framework for evaluating the quality of learned neural representations, in particular concerning attribute grounding. To this end, we extend the original GuessWhat?! dataset by including a semantic layer on top of the perceptual one. Specifically, we enrich the VisualGenome scene graphs associated with the GuessWhat?! images with abstract and situated attributes. By using diagnostic classifiers, we show that current models learn representations that are not expressive enough to encode object attributes (average F1 of 44.27). In addition, they do not learn strategies nor representations that are robust enough to perform well when novel scenes or objects are involved in gameplay (zero-shot best accuracy 50.06%).