 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models under Cultural and Inclusive Considerations
Jul 08, 2024



Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Cultural Adaptation of Recipes
Oct 26, 2023Building upon the considerable advances in Large Language Models (LLMs), we are now equipped to address more sophisticated tasks demanding a nuanced understanding of cross-cultural contexts. A key example is recipe adaptation, which goes beyond simple translation to include a grasp of ingredients, culinary techniques, and dietary preferences specific to a given culture. We introduce a new task involving the translation and cultural adaptation of recipes between Chinese and English-speaking cuisines. To support this investigation, we present CulturalRecipes, a unique dataset comprised of automatically paired recipes written in Mandarin Chinese and English. This dataset is further enriched with a human-written and curated test set. In this intricate task of cross-cultural recipe adaptation, we evaluate the performance of various methods, including GPT-4 and other LLMs, traditional machine translation, and information retrieval techniques. Our comprehensive analysis includes both automatic and human evaluation metrics. While GPT-4 exhibits impressive abilities in adapting Chinese recipes into English, it still lags behind human expertise when translating English recipes into Chinese. This underscores the multifaceted nature of cultural adaptations. We anticipate that these insights will significantly contribute to future research on culturally-aware language models and their practical application in culturally diverse contexts.
What does the Failure to Reason with "Respectively" in Zero/Few-Shot Settings Tell Us about Language Models?
May 31, 2023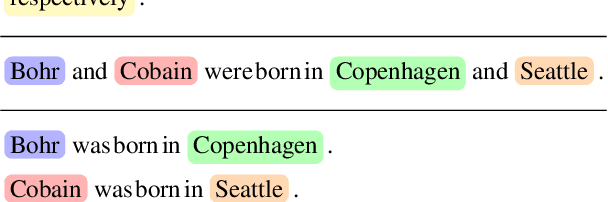
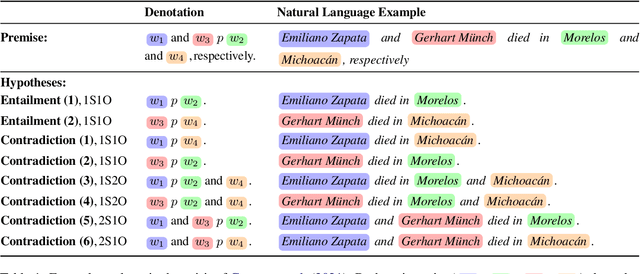
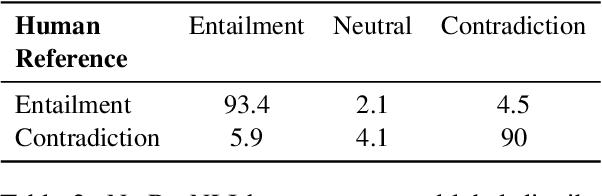
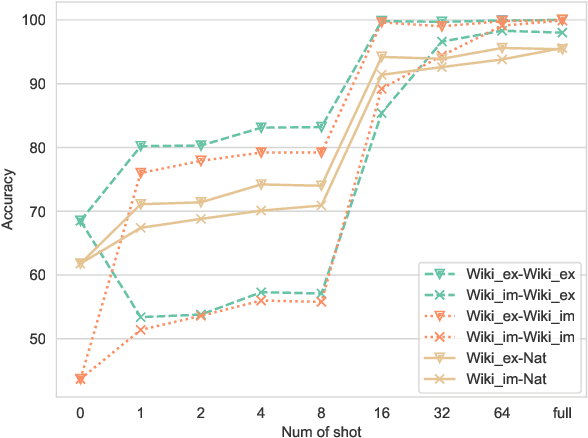
Humans can effortlessly understand the coordinate structure of sentences such as "Niels Bohr and Kurt Cobain were born in Copenhagen and Seattle, respectively". In the context of natural language inference (NLI), we examine how language models (LMs) reason with respective readings (Gawron and Kehler, 2004) from two perspectives: syntactic-semantic and commonsense-world knowledge. We propose a controlled synthetic dataset WikiResNLI and a naturally occurring dataset NatResNLI to encompass various explicit and implicit realizations of "respectively". We show that fine-tuned NLI models struggle with understanding such readings without explicit supervision. While few-shot learning is easy in the presence of explicit cues, longer training is required when the reading is evoked implicitly, leaving models to rely on common sense inferences. Furthermore, our fine-grained analysis indicates models fail to generalize across different constructions. To conclude, we demonstrate that LMs still lag behind humans in generalizing to the long tail of linguistic constructions.
AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models
Apr 13, 2023Evaluating the general abilities of foundation models to tackle human-level tasks is a vital aspect of their development and application in the pursuit of Artificial General Intelligence (AGI). Traditional benchmarks, which rely on artificial datasets, may not accurately represent human-level capabilities. In this paper, we introduce AGIEval, a novel benchmark specifically designed to assess foundation model in the context of human-centric standardized exams, such as college entrance exams, law school admission tests, math competitions, and lawyer qualification tests. We evaluate several state-of-the-art foundation models, including GPT-4, ChatGPT, and Text-Davinci-003, using this benchmark. Impressively, GPT-4 surpasses average human performance on SAT, LSAT, and math competitions, attaining a 95% accuracy rate on the SAT Math test and a 92.5% accuracy on the English test of the Chinese national college entrance exam. This demonstrates the extraordinary performance of contemporary foundation models. In contrast, we also find that GPT-4 is less proficient in tasks that require complex reasoning or specific domain knowledge. Our comprehensive analyses of model capabilities (understanding, knowledge, reasoning, and calculation) reveal these models' strengths and limitations, providing valuable insights into future directions for enhancing their general capabilities. By concentrating on tasks pertinent to human cognition and decision-making, our benchmark delivers a more meaningful and robust evaluation of foundation models' performance in real-world scenarios. The data, code, and all model outputs are released in https://github.com/microsoft/AGIEval.
Generalized Quantifiers as a Source of Error in Multilingual NLU Benchmarks
Apr 22, 2022
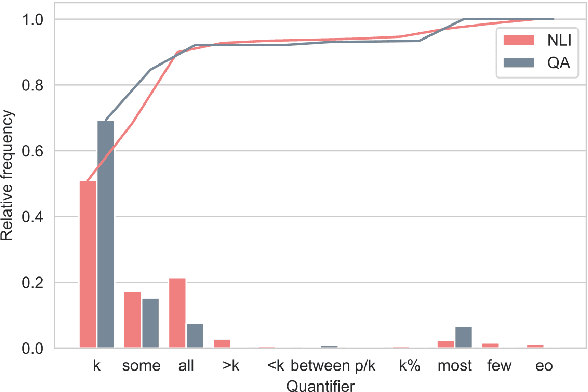

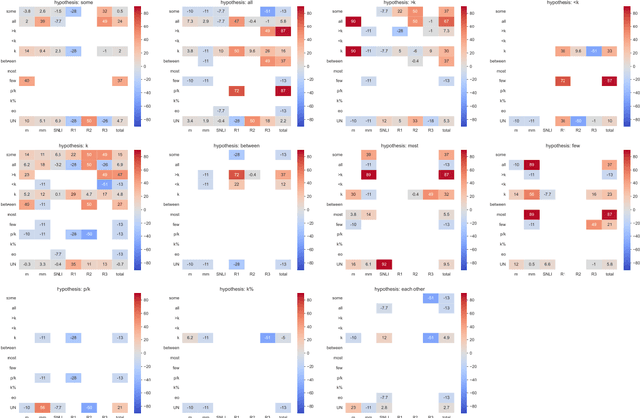
Logical approaches to representing language have developed and evaluated computational models of quantifier words since the 19th century, but today's NLU models still struggle to capture their semantics. We rely on Generalized Quantifier Theory for language-independent representations of the semantics of quantifier words, to quantify their contribution to the errors of NLU models. We find that quantifiers are pervasive in NLU benchmarks, and their occurrence at test time is associated with performance drops. Multilingual models also exhibit unsatisfying quantifier reasoning abilities, but not necessarily worse for non-English languages. To facilitate directly-targeted probing, we present an adversarial generalized quantifier NLI task (GQNLI) and show that pre-trained language models have a clear lack of robustness in generalized quantifier reasoning.
How Conservative are Language Models? Adapting to the Introduction of Gender-Neutral Pronouns
Apr 11, 2022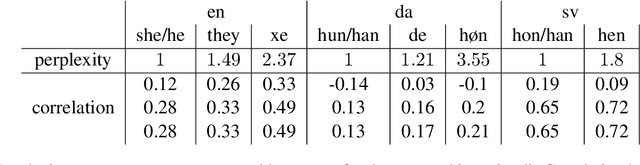


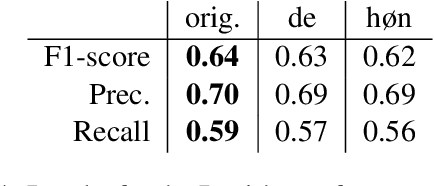
Gender-neutral pronouns have recently been introduced in many languages to a) include non-binary people and b) as a generic singular. Recent results from psycho-linguistics suggest that gender-neutral pronouns (in Swedish) are not associated with human processing difficulties. This, we show, is in sharp contrast with automated processing. We show that gender-neutral pronouns in Danish, English, and Swedish are associated with higher perplexity, more dispersed attention patterns, and worse downstream performance. We argue that such conservativity in language models may limit widespread adoption of gender-neutral pronouns and must therefore be resolved.
Challenges and Strategies in Cross-Cultural NLP
Mar 18, 2022
Various efforts in the Natural Language Processing (NLP) community have been made to accommodate linguistic diversity and serve speakers of many different languages. However, it is important to acknowledge that speakers and the content they produce and require, vary not just by language, but also by culture. Although language and culture are tightly linked, there are important differences. Analogous to cross-lingual and multilingual NLP, cross-cultural and multicultural NLP considers these differences in order to better serve users of NLP systems. We propose a principled framework to frame these efforts, and survey existing and potential strategies.
Multilingual Compositional Wikidata Questions
Aug 07, 2021
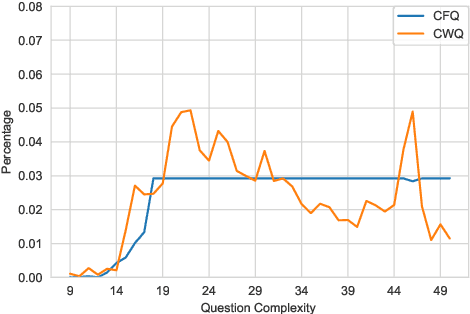
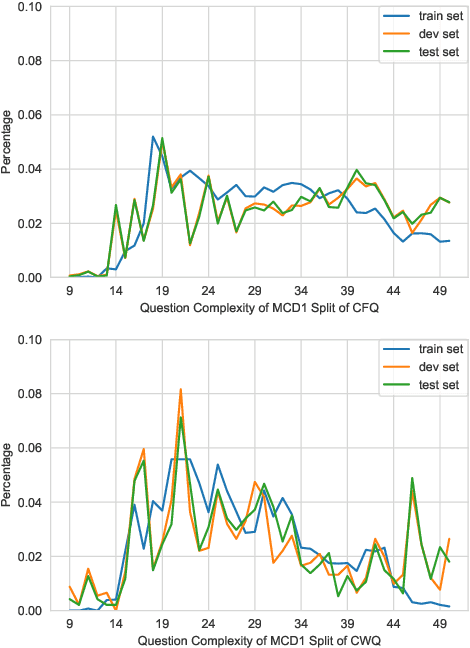
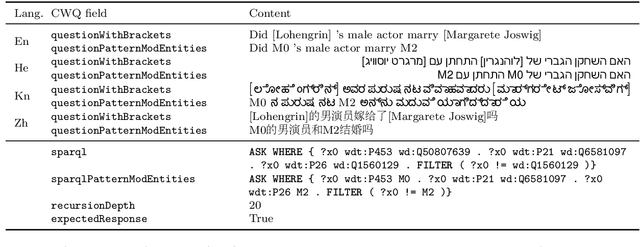
Semantic parsing allows humans to leverage vast knowledge resources through natural interaction. However, parsers are mostly designed for and evaluated on English resources, such as CFQ (Keysers et al., 2020), the current standard benchmark based on English data generated from grammar rules and oriented towards Freebase, an outdated knowledge base. We propose a method for creating a multilingual, parallel dataset of question-query pairs, grounded in Wikidata, and introduce such a dataset called Compositional Wikidata Questions (CWQ). We utilize this data to train and evaluate semantic parsers for Hebrew, Kannada, Chinese and English, to better understand the current strengths and weaknesses of multilingual semantic parsing. Experiments on zero-shot cross-lingual transfer demonstrate that models fail to generate valid queries even with pretrained multilingual encoders. Our methodology, dataset and results will facilitate future research on semantic parsing in more realistic and diverse settings than has been possible with existing resources.
Great Service! Fine-grained Parsing of Implicit Arguments
Jun 23, 2021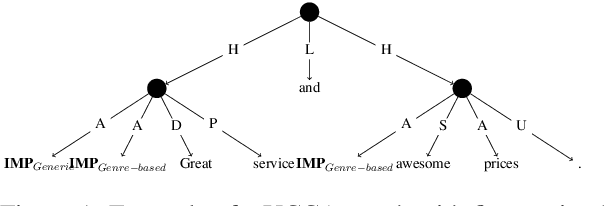


Broad-coverage meaning representations in NLP mostly focus on explicitly expressed content. More importantly, the scarcity of datasets annotating diverse implicit roles limits empirical studies into their linguistic nuances. For example, in the web review "Great service!", the provider and consumer are implicit arguments of different types. We examine an annotated corpus of fine-grained implicit arguments (Cui and Hershcovich, 2020) by carefully re-annotating it, resolving several inconsistencies. Subsequently, we present the first transition-based neural parser that can handle implicit arguments dynamically, and experiment with two different transition systems on the improved dataset. We find that certain types of implicit arguments are more difficult to parse than others and that the simpler system is more accurate in recovering implicit arguments, despite having a lower overall parsing score, attesting current reasoning limitations of NLP models. This work will facilitate a better understanding of implicit and underspecified language, by incorporating it holistically into meaning representations.
Meaning Representation of Numeric Fused-Heads in UCCA
Jun 04, 2021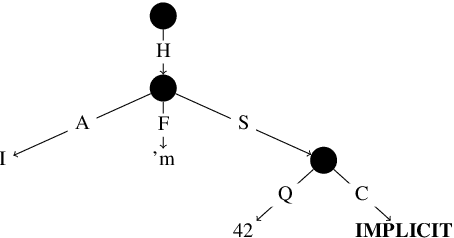

We exhibit that the implicit UCCA parser does not address numeric fused-heads (NFHs) consistently, which could result either from inconsistent annotation, insufficient training data or a modelling limitation. and show which factors are involved. We consider this phenomenon important, as it is pervasive in text and critical for correct inference. Careful design and fine-grained annotation of NFHs in meaning representation frameworks would benefit downstream tasks such as machine translation, natural language inference and question answering, particularly when they require numeric reasoning, as recovering and categorizing them. We are investigating the treatment of this phenomenon by other meaning representations, such as AMR. We encourage researchers in meaning representations, and computational linguistics in general, to address this phenomenon in future research.