 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024



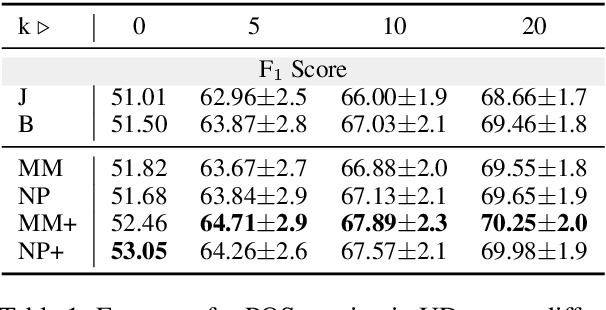
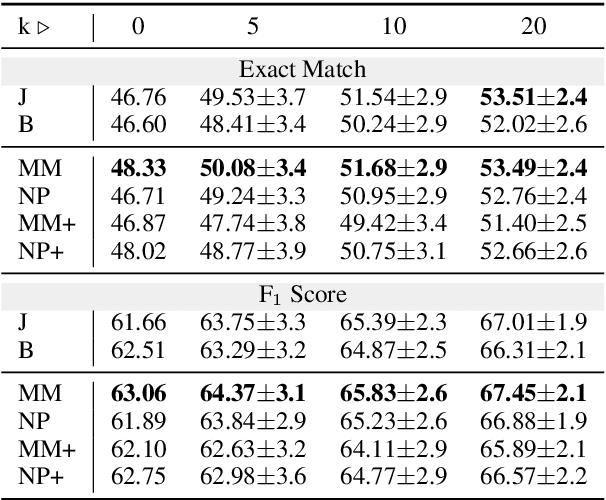
Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
Towards Better Evaluation of Instruction-Following: A Case-Study in Summarization
Oct 20, 2023Despite recent advances, evaluating how well large language models (LLMs) follow user instructions remains an open problem. While evaluation methods of language models have seen a rise in prompt-based approaches, limited work on the correctness of these methods has been conducted. In this work, we perform a meta-evaluation of a variety of metrics to quantify how accurately they measure the instruction-following abilities of LLMs. Our investigation is performed on grounded query-based summarization by collecting a new short-form, real-world dataset riSum, containing 300 document-instruction pairs with 3 answers each. All 900 answers are rated by 3 human annotators. Using riSum, we analyze the agreement between evaluation methods and human judgment. Finally, we propose new LLM-based reference-free evaluation methods that improve upon established baselines and perform on par with costly reference-based metrics that require high-quality summaries.
Vārta: A Large-Scale Headline-Generation Dataset for Indic Languages
May 10, 2023
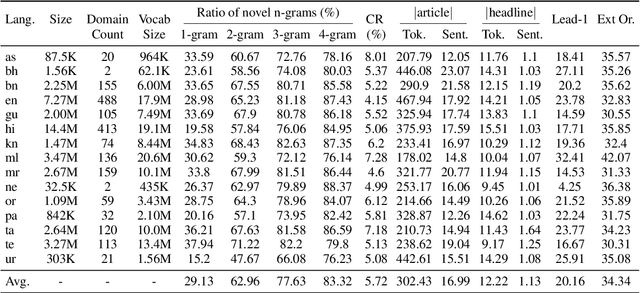
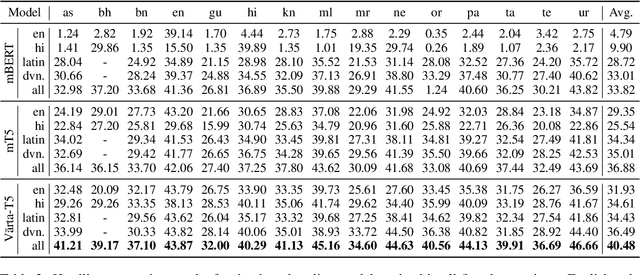

We present V\=arta, a large-scale multilingual dataset for headline generation in Indic languages. This dataset includes 41.8 million news articles in 14 different Indic languages (and English), which come from a variety of high-quality sources. To the best of our knowledge, this is the largest collection of curated articles for Indic languages currently available. We use the data collected in a series of experiments to answer important questions related to Indic NLP and multilinguality research in general. We show that the dataset is challenging even for state-of-the-art abstractive models and that they perform only slightly better than extractive baselines. Owing to its size, we also show that the dataset can be used to pretrain strong language models that outperform competitive baselines in both NLU and NLG benchmarks.
IndicXTREME: A Multi-Task Benchmark For Evaluating Indic Languages
Dec 13, 2022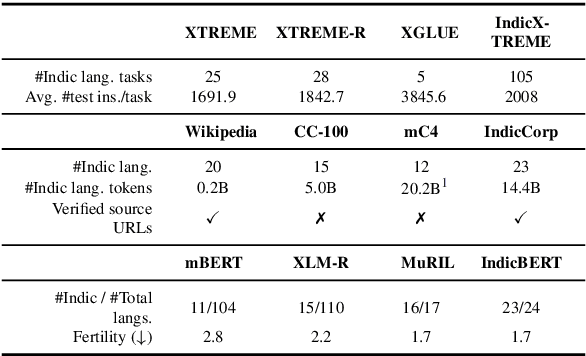
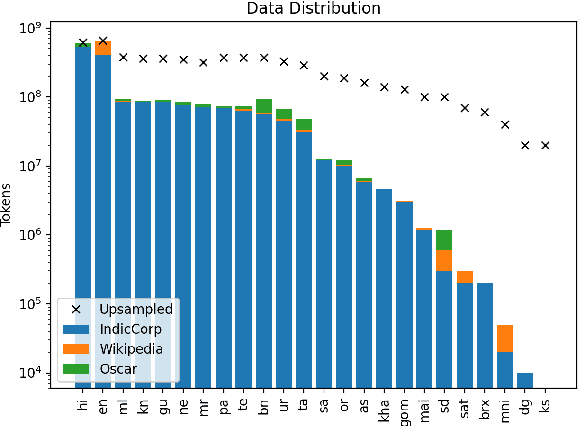
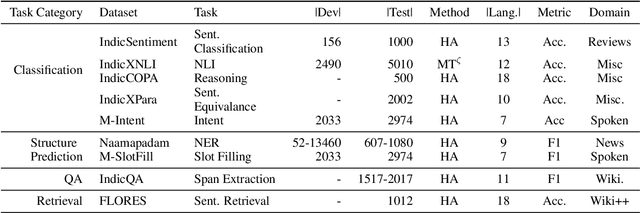
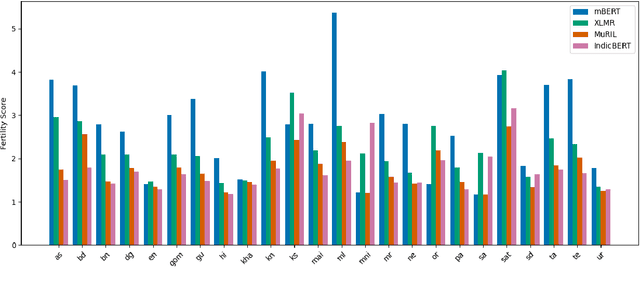
In this work, we introduce IndicXTREME, a benchmark consisting of nine diverse tasks covering 18 languages from the Indic sub-continent belonging to four different families. Across languages and tasks, IndicXTREME contains a total of 103 evaluation sets, of which 51 are new contributions to the literature. To maintain high quality, we only use human annotators to curate or translate our datasets. To the best of our knowledge, this is the first effort toward creating a standard benchmark for Indic languages that aims to test the zero-shot capabilities of pretrained language models. We also release IndicCorp v2, an updated and much larger version of IndicCorp that contains 20.9 billion tokens in 24 languages. We pretrain IndicBERT v2 on IndicCorp v2 and evaluate it on IndicXTREME to show that it outperforms existing multilingual language models such as XLM-R and MuRIL.
Multilingual Compositional Wikidata Questions
Aug 07, 2021
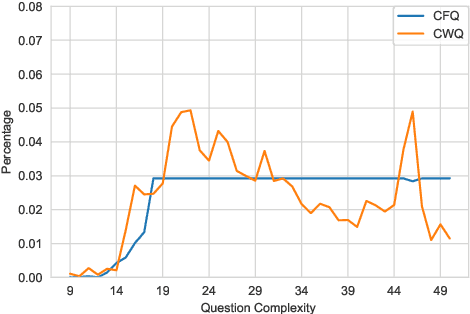
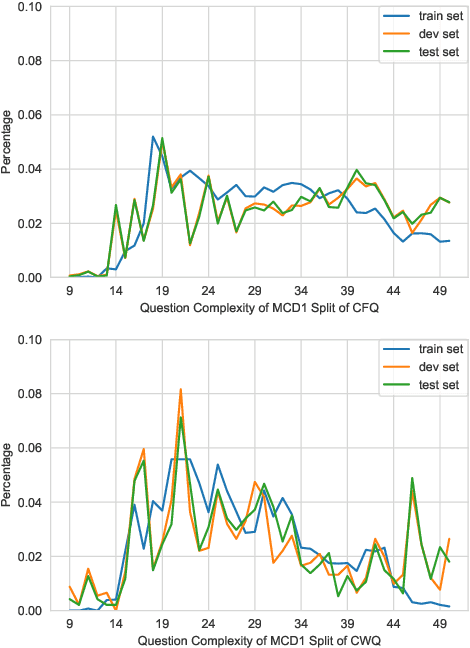
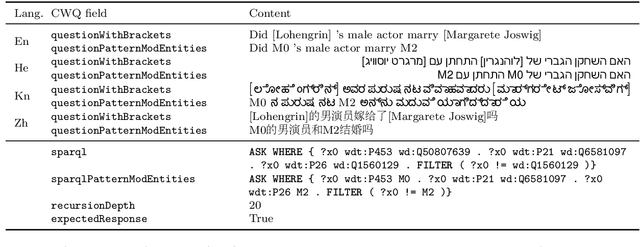
Semantic parsing allows humans to leverage vast knowledge resources through natural interaction. However, parsers are mostly designed for and evaluated on English resources, such as CFQ (Keysers et al., 2020), the current standard benchmark based on English data generated from grammar rules and oriented towards Freebase, an outdated knowledge base. We propose a method for creating a multilingual, parallel dataset of question-query pairs, grounded in Wikidata, and introduce such a dataset called Compositional Wikidata Questions (CWQ). We utilize this data to train and evaluate semantic parsers for Hebrew, Kannada, Chinese and English, to better understand the current strengths and weaknesses of multilingual semantic parsing. Experiments on zero-shot cross-lingual transfer demonstrate that models fail to generate valid queries even with pretrained multilingual encoders. Our methodology, dataset and results will facilitate future research on semantic parsing in more realistic and diverse settings than has been possible with existing resources.
Itihasa: A large-scale corpus for Sanskrit to English translation
Jun 08, 2021
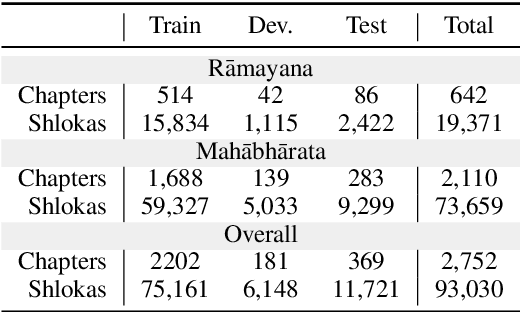
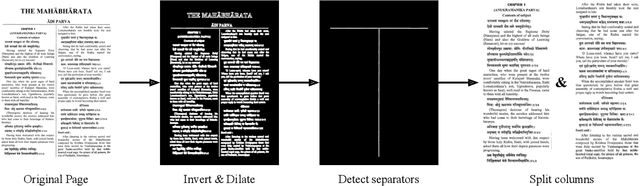
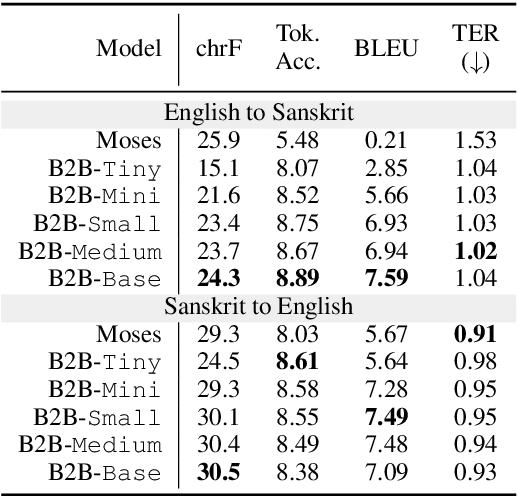
This work introduces Itihasa, a large-scale translation dataset containing 93,000 pairs of Sanskrit shlokas and their English translations. The shlokas are extracted from two Indian epics viz., The Ramayana and The Mahabharata. We first describe the motivation behind the curation of such a dataset and follow up with empirical analysis to bring out its nuances. We then benchmark the performance of standard translation models on this corpus and show that even state-of-the-art transformer architectures perform poorly, emphasizing the complexity of the dataset.
Minimax and Neyman-Pearson Meta-Learning for Outlier Languages
Jun 02, 2021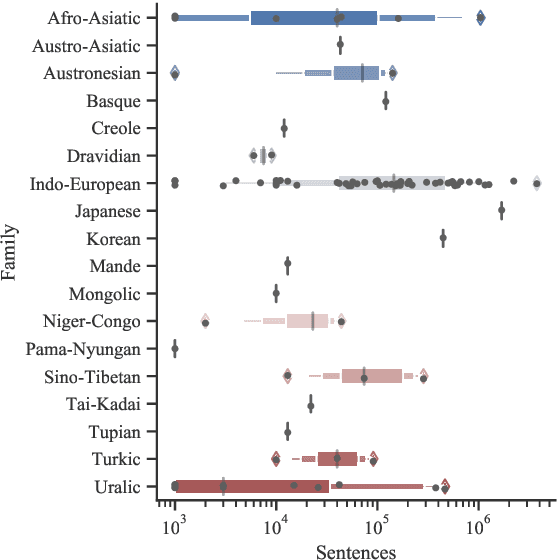
Model-agnostic meta-learning (MAML) has been recently put forth as a strategy to learn resource-poor languages in a sample-efficient fashion. Nevertheless, the properties of these languages are often not well represented by those available during training. Hence, we argue that the i.i.d. assumption ingrained in MAML makes it ill-suited for cross-lingual NLP. In fact, under a decision-theoretic framework, MAML can be interpreted as minimising the expected risk across training languages (with a uniform prior), which is known as Bayes criterion. To increase its robustness to outlier languages, we create two variants of MAML based on alternative criteria: Minimax MAML reduces the maximum risk across languages, while Neyman-Pearson MAML constrains the risk in each language to a maximum threshold. Both criteria constitute fully differentiable two-player games. In light of this, we propose a new adaptive optimiser solving for a local approximation to their Nash equilibrium. We evaluate both model variants on two popular NLP tasks, part-of-speech tagging and question answering. We report gains for their average and minimum performance across low-resource languages in zero- and few-shot settings, compared to joint multi-source transfer and vanilla MAML.
Focus Attention: Promoting Faithfulness and Diversity in Summarization
May 25, 2021

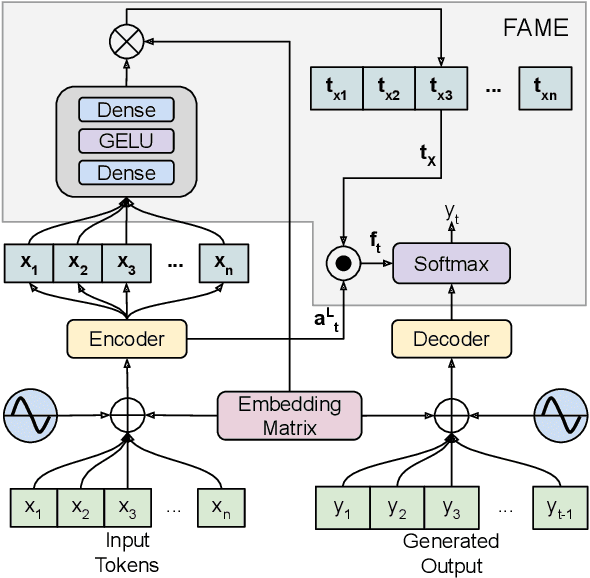
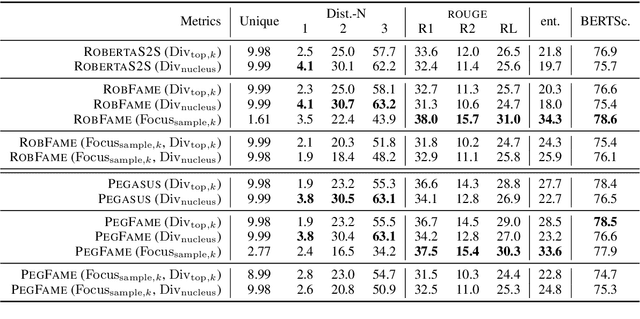
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on \rouge and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-$k$ or nucleus sampling-based decoding methods.
Joint Semantic Analysis with Document-Level Cross-Task Coherence Rewards
Oct 12, 2020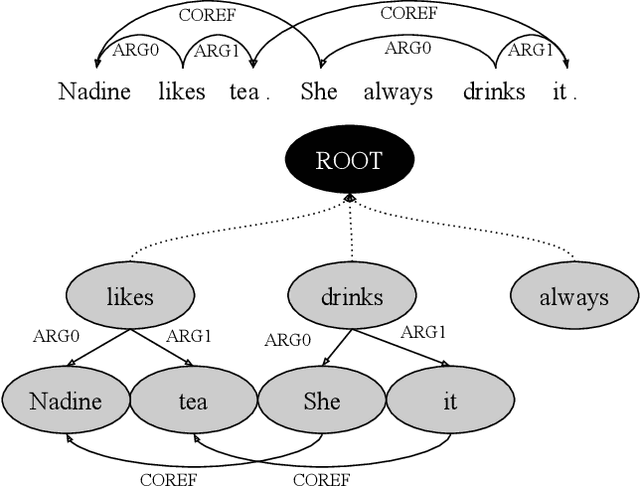
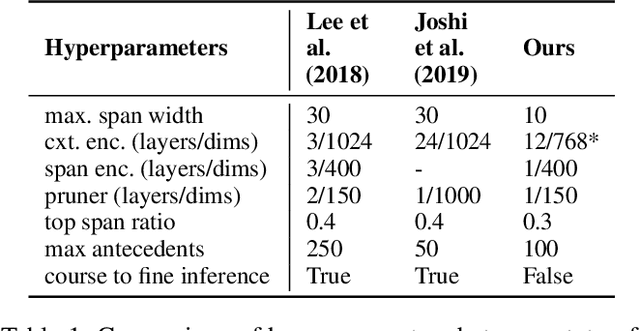

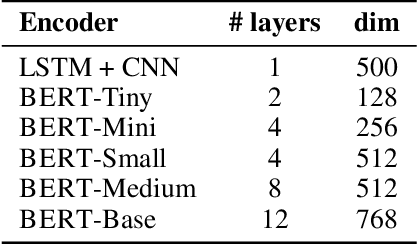
Coreference resolution and semantic role labeling are NLP tasks that capture different aspects of semantics, indicating respectively, which expressions refer to the same entity, and what semantic roles expressions serve in the sentence. However, they are often closely interdependent, and both generally necessitate natural language understanding. Do they form a coherent abstract representation of documents? We present a neural network architecture for joint coreference resolution and semantic role labeling for English, and train graph neural networks to model the 'coherence' of the combined shallow semantic graph. Using the resulting coherence score as a reward for our joint semantic analyzer, we use reinforcement learning to encourage global coherence over the document and between semantic annotations. This leads to improvements on both tasks in multiple datasets from different domains, and across a range of encoders of different expressivity, calling, we believe, for a more holistic approach to semantics in NLP.
Compositional Generalization in Image Captioning
Sep 16, 2019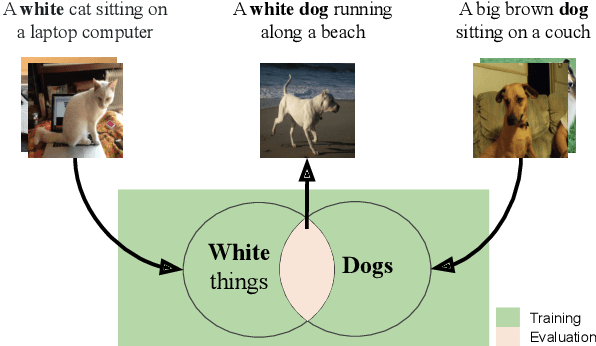

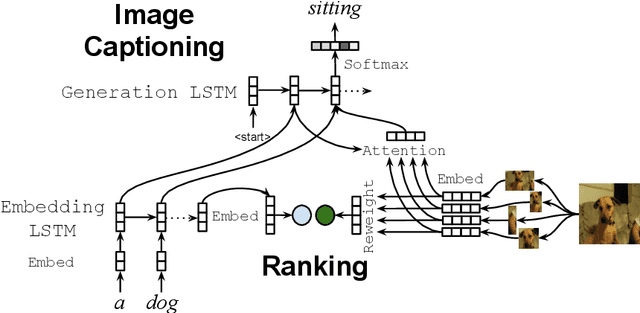
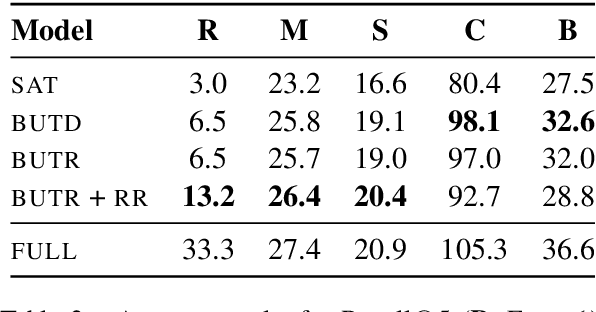
Image captioning models are usually evaluated on their ability to describe a held-out set of images, not on their ability to generalize to unseen concepts. We study the problem of compositional generalization, which measures how well a model composes unseen combinations of concepts when describing images. State-of-the-art image captioning models show poor generalization performance on this task. We propose a multi-task model to address the poor performance, that combines caption generation and image--sentence ranking, and uses a decoding mechanism that re-ranks the captions according their similarity to the image. This model is substantially better at generalizing to unseen combinations of concepts compared to state-of-the-art captioning models.