 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
Single Sequence Prediction over Reasoning Graphs for Multi-hop QA
Jul 01, 2023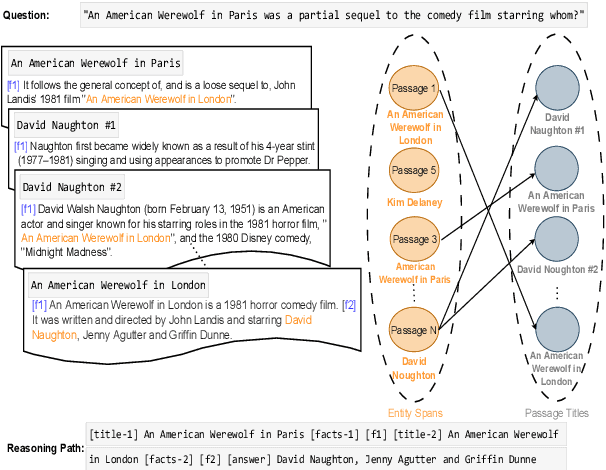
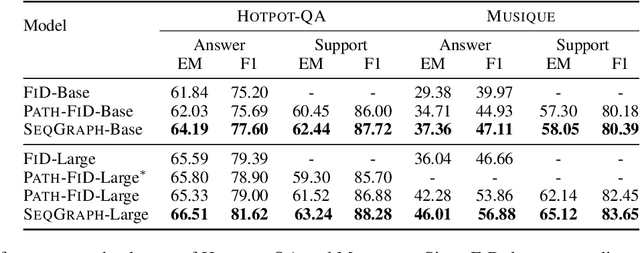
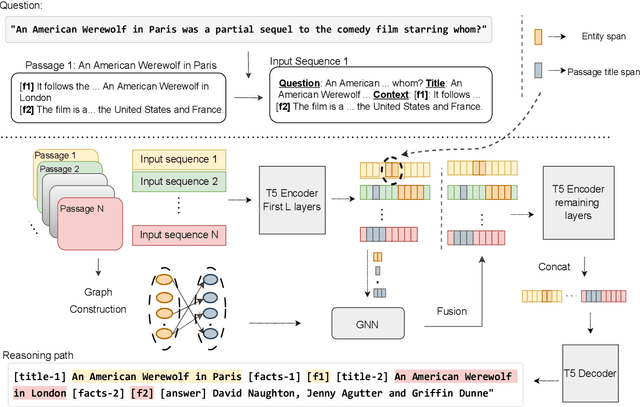
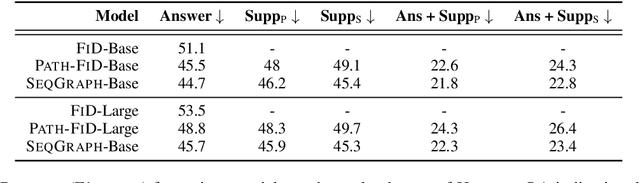
Recent generative approaches for multi-hop question answering (QA) utilize the fusion-in-decoder method~\cite{izacard-grave-2021-leveraging} to generate a single sequence output which includes both a final answer and a reasoning path taken to arrive at that answer, such as passage titles and key facts from those passages. While such models can lead to better interpretability and high quantitative scores, they often have difficulty accurately identifying the passages corresponding to key entities in the context, resulting in incorrect passage hops and a lack of faithfulness in the reasoning path. To address this, we propose a single-sequence prediction method over a local reasoning graph (\model)\footnote{Code/Models will be released at \url{https://github.com/gowtham1997/SeqGraph}} that integrates a graph structure connecting key entities in each context passage to relevant subsequent passages for each question. We use a graph neural network to encode this graph structure and fuse the resulting representations into the entity representations of the model. Our experiments show significant improvements in answer exact-match/F1 scores and faithfulness of grounding in the reasoning path on the HotpotQA dataset and achieve state-of-the-art numbers on the Musique dataset with only up to a 4\% increase in model parameters.
IndicXTREME: A Multi-Task Benchmark For Evaluating Indic Languages
Dec 13, 2022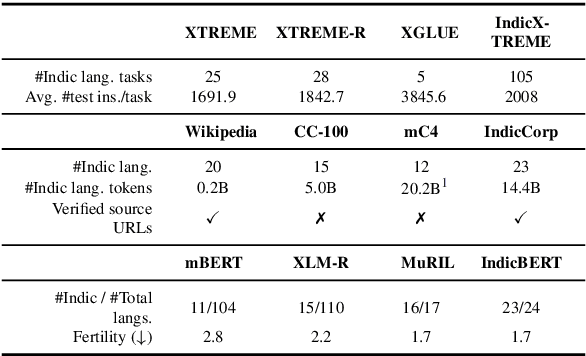
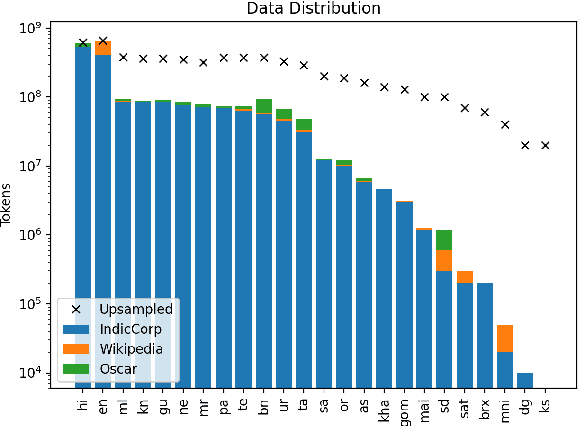
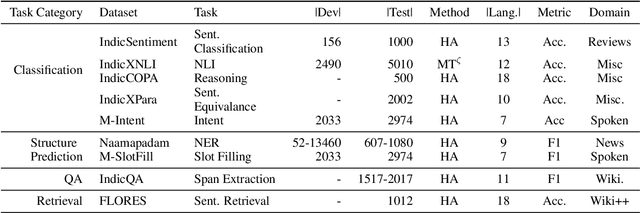
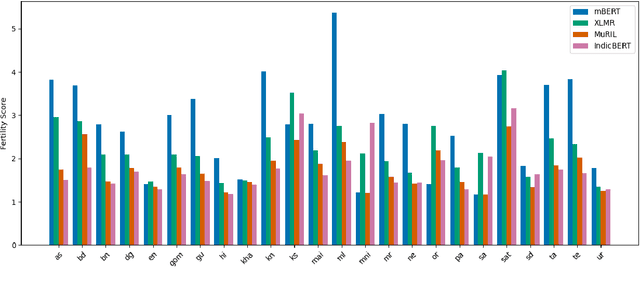
In this work, we introduce IndicXTREME, a benchmark consisting of nine diverse tasks covering 18 languages from the Indic sub-continent belonging to four different families. Across languages and tasks, IndicXTREME contains a total of 103 evaluation sets, of which 51 are new contributions to the literature. To maintain high quality, we only use human annotators to curate or translate our datasets. To the best of our knowledge, this is the first effort toward creating a standard benchmark for Indic languages that aims to test the zero-shot capabilities of pretrained language models. We also release IndicCorp v2, an updated and much larger version of IndicCorp that contains 20.9 billion tokens in 24 languages. We pretrain IndicBERT v2 on IndicCorp v2 and evaluate it on IndicXTREME to show that it outperforms existing multilingual language models such as XLM-R and MuRIL.
Towards Building ASR Systems for the Next Billion Users
Nov 12, 2021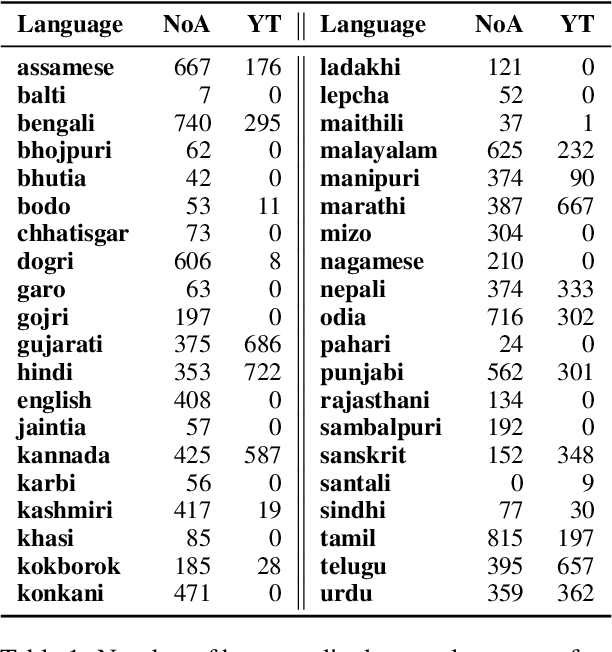
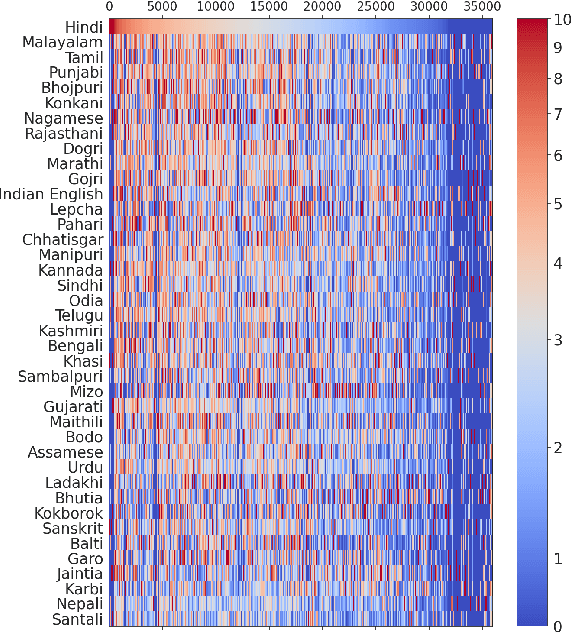
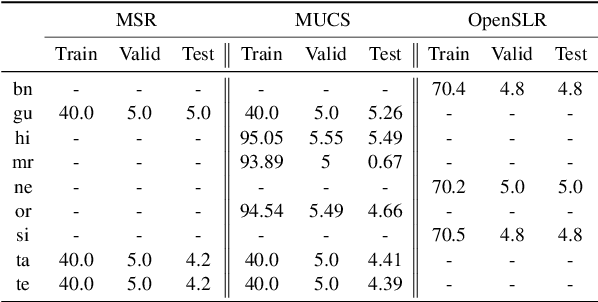
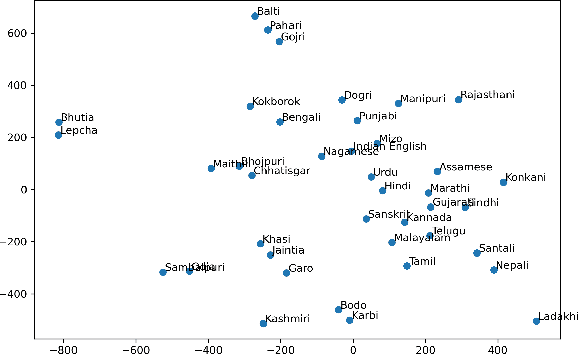
Recent methods in speech and language technology pretrain very LARGE models which are fine-tuned for specific tasks. However, the benefits of such LARGE models are often limited to a few resource rich languages of the world. In this work, we make multiple contributions towards building ASR systems for low resource languages from the Indian subcontinent. First, we curate 17,000 hours of raw speech data for 40 Indian languages from a wide variety of domains including education, news, technology, and finance. Second, using this raw speech data we pretrain several variants of wav2vec style models for 40 Indian languages. Third, we analyze the pretrained models to find key features: codebook vectors of similar sounding phonemes are shared across languages, representations across layers are discriminative of the language family, and attention heads often pay attention within small local windows. Fourth, we fine-tune this model for downstream ASR for 9 languages and obtain state-of-the-art results on 3 public datasets, including on very low-resource languages such as Sinhala and Nepali. Our work establishes that multilingual pretraining is an effective strategy for building ASR systems for the linguistically diverse speakers of the Indian subcontinent.
SuperShaper: Task-Agnostic Super Pre-training of BERT Models with Variable Hidden Dimensions
Oct 10, 2021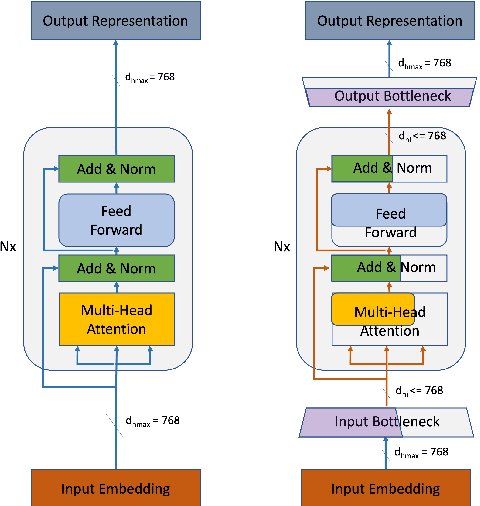
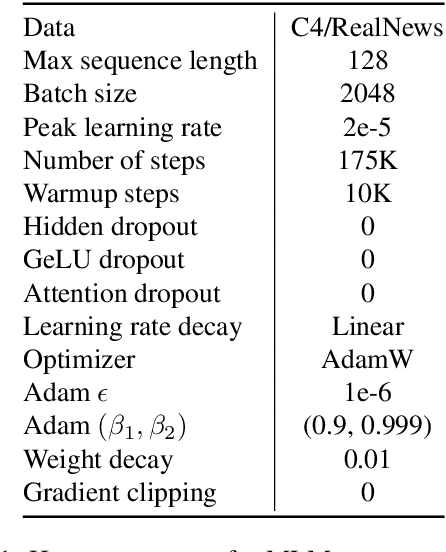
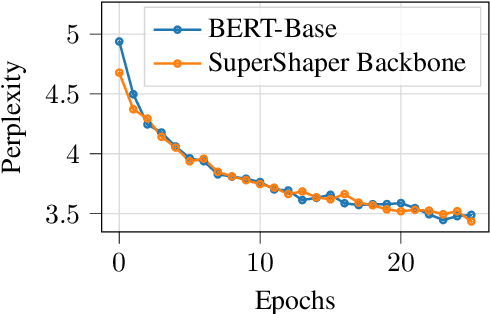
Task-agnostic pre-training followed by task-specific fine-tuning is a default approach to train NLU models. Such models need to be deployed on devices across the cloud and the edge with varying resource and accuracy constraints. For a given task, repeating pre-training and fine-tuning across tens of devices is prohibitively expensive. We propose SuperShaper, a task agnostic pre-training approach which simultaneously pre-trains a large number of Transformer models by varying shapes, i.e., by varying the hidden dimensions across layers. This is enabled by a backbone network with linear bottleneck matrices around each Transformer layer which are sliced to generate differently shaped sub-networks. In spite of its simple design space and efficient implementation, SuperShaper discovers networks that effectively trade-off accuracy and model size: Discovered networks are more accurate than a range of hand-crafted and automatically searched networks on GLUE benchmarks. Further, we find two critical advantages of shape as a design variable for Neural Architecture Search (NAS): (a) heuristics of good shapes can be derived and networks found with these heuristics match and even improve on carefully searched networks across a range of parameter counts, and (b) the latency of networks across multiple CPUs and GPUs are insensitive to the shape and thus enable device-agnostic search. In summary, SuperShaper radically simplifies NAS for language models and discovers networks that generalize across tasks, parameter constraints, and devices.
A Primer on Pretrained Multilingual Language Models
Jul 01, 2021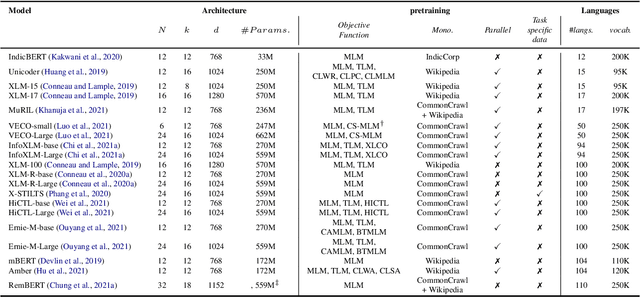
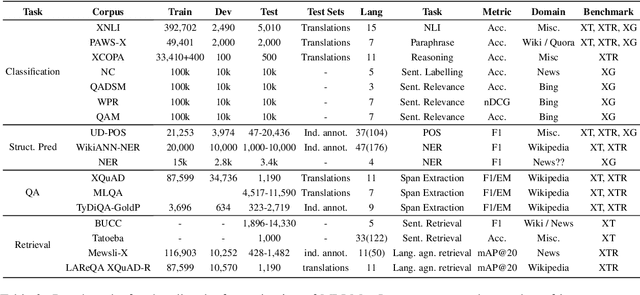
Multilingual Language Models (MLLMs) such as mBERT, XLM, XLM-R, \textit{etc.} have emerged as a viable option for bringing the power of pretraining to a large number of languages. Given their success in zero shot transfer learning, there has emerged a large body of work in (i) building bigger MLLMs covering a large number of languages (ii) creating exhaustive benchmarks covering a wider variety of tasks and languages for evaluating MLLMs (iii) analysing the performance of MLLMs on monolingual, zero shot crosslingual and bilingual tasks (iv) understanding the universal language patterns (if any) learnt by MLLMs and (v) augmenting the (often) limited capacity of MLLMs to improve their performance on seen or even unseen languages. In this survey, we review the existing literature covering the above broad areas of research pertaining to MLLMs. Based on our survey, we recommend some promising directions of future research.
Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages
Apr 29, 2021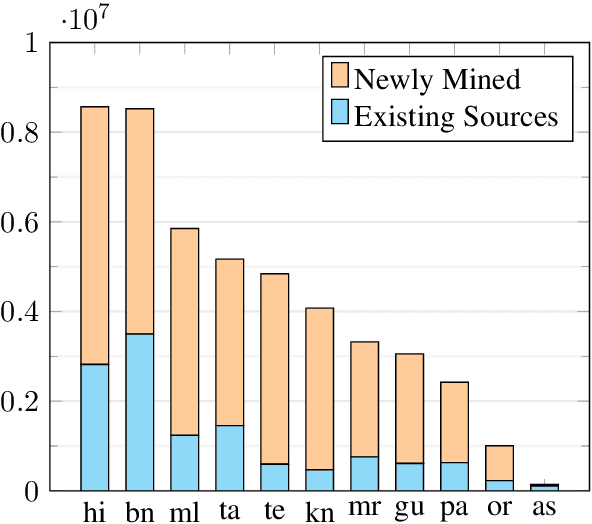
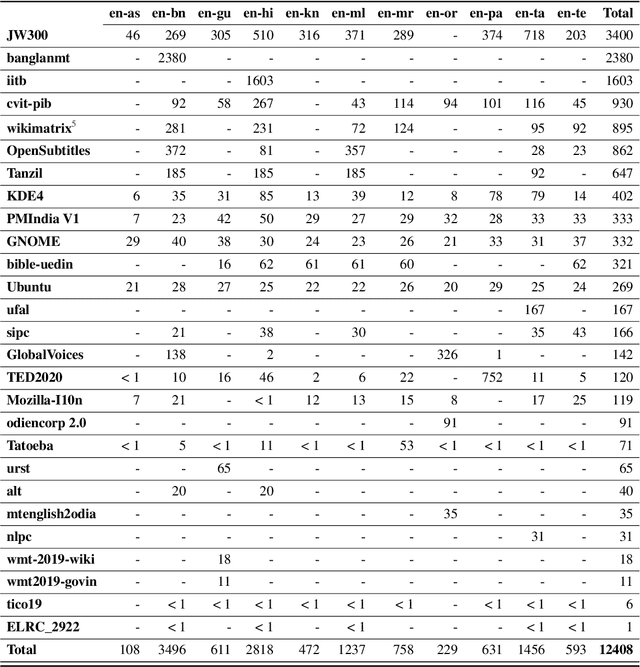
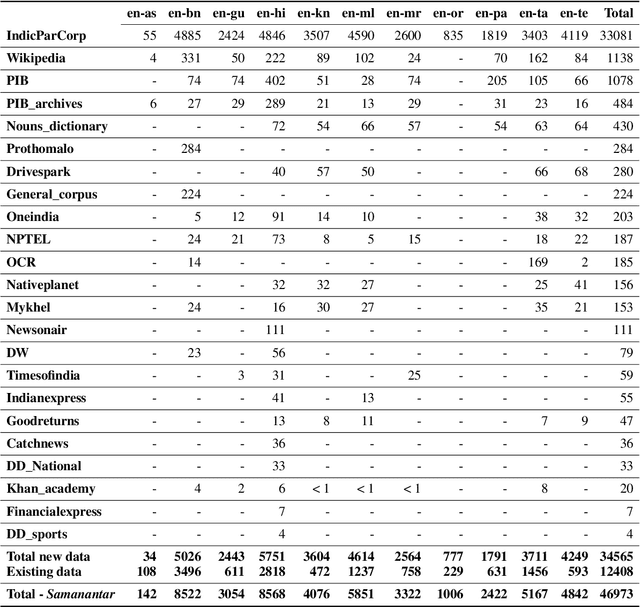
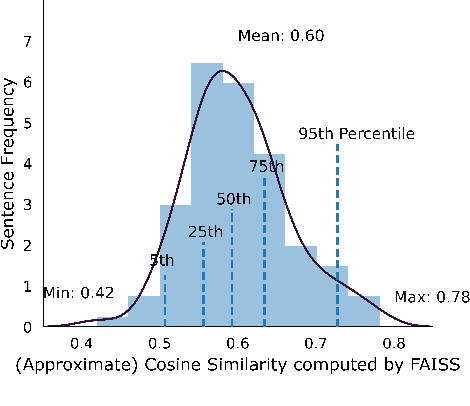
We present Samanantar, the largest publicly available parallel corpora collection for Indic languages. The collection contains a total of 46.9 million sentence pairs between English and 11 Indic languages (from two language families). In particular, we compile 12.4 million sentence pairs from existing, publicly-available parallel corpora, and we additionally mine 34.6 million sentence pairs from the web, resulting in a 2.8X increase in publicly available sentence pairs. We mine the parallel sentences from the web by combining many corpora, tools, and methods. In particular, we use (a) web-crawled monolingual corpora, (b) document OCR for extracting sentences from scanned documents (c) multilingual representation models for aligning sentences, and (d) approximate nearest neighbor search for searching in a large collection of sentences. Human evaluation of samples from the newly mined corpora validate the high quality of the parallel sentences across 11 language pairs. Further, we extracted 82.7 million sentence pairs between all 55 Indic language pairs from the English-centric parallel corpus using English as the pivot language. We trained multilingual NMT models spanning all these languages on Samanantar and compared with other baselines and previously reported results on publicly available benchmarks. Our models outperform existing models on these benchmarks, establishing the utility of Samanantar. Our data (https://indicnlp.ai4bharat.org/samanantar) and models (https://github.com/AI4Bharat/IndicTrans) will be available publicly and we hope they will help advance research in Indic NMT and multilingual NLP for Indic languages.