 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIE: Controlling Language Model Text Generations Using Continuous Signals
May 19, 2025Aligning language models with user intent is becoming increasingly relevant to enhance user experience. This calls for designing methods that can allow users to control the properties of the language that LMs generate. For example, controlling the length of the generation, the complexity of the language that gets chosen, the sentiment, tone, etc. Most existing work attempts to integrate users' control by conditioning LM generations on natural language prompts or discrete control signals, which are often brittle and hard to scale. In this work, we are interested in \textit{continuous} control signals, ones that exist along a spectrum that can't easily be captured in a natural language prompt or via existing techniques in conditional generation. Through a case study in controlling the precise response-length of generations produced by LMs, we demonstrate how after fine-tuning, behaviors of language models can be controlled via continuous signals -- as vectors that are interpolated between a "low" and a "high" token embedding. Our method more reliably exerts response-length control than in-context learning methods or fine-tuning methods that represent the control signal as a discrete signal. Our full open-sourced code and datasets are available at https://github.com/vsamuel2003/CIE.
NoveltyBench: Evaluating Language Models for Humanlike Diversity
Apr 08, 2025Language models have demonstrated remarkable capabilities on standard benchmarks, yet they struggle increasingly from mode collapse, the inability to generate diverse and novel outputs. Our work introduces NoveltyBench, a benchmark specifically designed to evaluate the ability of language models to produce multiple distinct and high-quality outputs. NoveltyBench utilizes prompts curated to elicit diverse answers and filtered real-world user queries. Evaluating 20 leading language models, we find that current state-of-the-art systems generate significantly less diversity than human writers. Notably, larger models within a family often exhibit less diversity than their smaller counterparts, challenging the notion that capability on standard benchmarks translates directly to generative utility. While prompting strategies like in-context regeneration can elicit diversity, our findings highlight a fundamental lack of distributional diversity in current models, reducing their utility for users seeking varied responses and suggesting the need for new training and evaluation paradigms that prioritize diversity alongside quality.
Chasing Random: Instruction Selection Strategies Fail to Generalize
Oct 19, 2024Prior work has shown that language models can be tuned to follow user instructions using only a small set of high-quality instructions. This has accelerated the development of methods that filter a large, noisy instruction-tuning datasets down to high-quality subset which works just as well. However, typically, the performance of these methods is not demonstrated across a uniform experimental setup and thus their generalization capabilities are not well established. In this work, we analyze popular selection strategies across different source datasets, selection budgets and evaluation benchmarks: Our results indicate that selection strategies generalize poorly, often failing to consistently outperform even random baselines. We also analyze the cost-performance trade-offs of using data selection. Our findings reveal that data selection can often exceed the cost of fine-tuning on the full dataset, yielding only marginal and sometimes no gains compared to tuning on the full dataset or a random subset.
Customizing Large Language Model Generation Style using Parameter-Efficient Finetuning
Sep 06, 2024
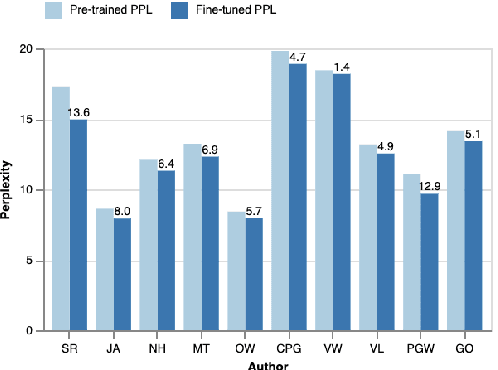
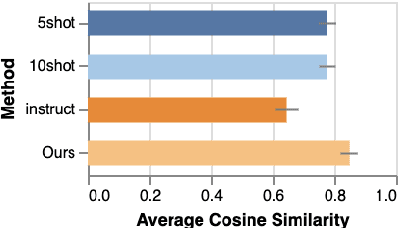
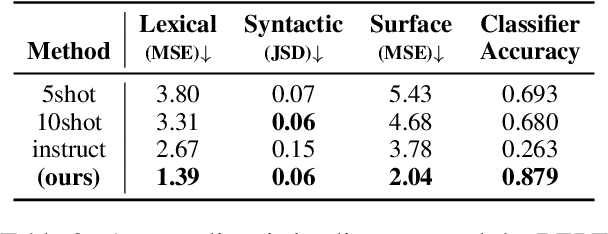
One-size-fits-all large language models (LLMs) are increasingly being used to help people with their writing. However, the style these models are trained to write in may not suit all users or use cases. LLMs would be more useful as writing assistants if their idiolect could be customized to match each user. In this paper, we explore whether parameter-efficient finetuning (PEFT) with Low-Rank Adaptation can effectively guide the style of LLM generations. We use this method to customize LLaMA-2 to ten different authors and show that the generated text has lexical, syntactic, and surface alignment with the target author but struggles with content memorization. Our findings highlight the potential of PEFT to support efficient, user-level customization of LLMs.
Akal Badi ya Bias: An Exploratory Study of Gender Bias in Hindi Language Technology
May 10, 2024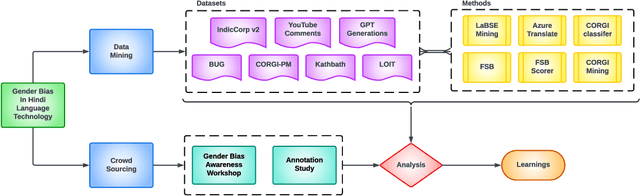

Existing research in measuring and mitigating gender bias predominantly centers on English, overlooking the intricate challenges posed by non-English languages and the Global South. This paper presents the first comprehensive study delving into the nuanced landscape of gender bias in Hindi, the third most spoken language globally. Our study employs diverse mining techniques, computational models, field studies and sheds light on the limitations of current methodologies. Given the challenges faced with mining gender biased statements in Hindi using existing methods, we conducted field studies to bootstrap the collection of such sentences. Through field studies involving rural and low-income community women, we uncover diverse perceptions of gender bias, underscoring the necessity for context-specific approaches. This paper advocates for a community-centric research design, amplifying voices often marginalized in previous studies. Our findings not only contribute to the understanding of gender bias in Hindi but also establish a foundation for further exploration of Indic languages. By exploring the intricacies of this understudied context, we call for thoughtful engagement with gender bias, promoting inclusivity and equity in linguistic and cultural contexts beyond the Global North.
''Fifty Shades of Bias'': Normative Ratings of Gender Bias in GPT Generated English Text
Oct 26, 2023Language serves as a powerful tool for the manifestation of societal belief systems. In doing so, it also perpetuates the prevalent biases in our society. Gender bias is one of the most pervasive biases in our society and is seen in online and offline discourses. With LLMs increasingly gaining human-like fluency in text generation, gaining a nuanced understanding of the biases these systems can generate is imperative. Prior work often treats gender bias as a binary classification task. However, acknowledging that bias must be perceived at a relative scale; we investigate the generation and consequent receptivity of manual annotators to bias of varying degrees. Specifically, we create the first dataset of GPT-generated English text with normative ratings of gender bias. Ratings were obtained using Best--Worst Scaling -- an efficient comparative annotation framework. Next, we systematically analyze the variation of themes of gender biases in the observed ranking and show that identity-attack is most closely related to gender bias. Finally, we show the performance of existing automated models trained on related concepts on our dataset.
Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
Sep 14, 2023Large Language Models (LLMs) have demonstrated impressive performance on Natural Language Processing (NLP) tasks, such as Question Answering, Summarization, and Classification. The use of LLMs as evaluators, that can rank or score the output of other models (usually LLMs) has become increasingly popular, due to the limitations of current evaluation techniques including the lack of appropriate benchmarks, metrics, cost, and access to human annotators. While LLMs are capable of handling approximately 100 languages, the majority of languages beyond the top 20 lack systematic evaluation across various tasks, metrics, and benchmarks. This creates an urgent need to scale up multilingual evaluation to ensure a precise understanding of LLM performance across diverse languages. LLM-based evaluators seem like the perfect solution to this problem, as they do not require human annotators, human-created references, or benchmarks and can theoretically be used to evaluate any language covered by the LLM. In this paper, we investigate whether LLM-based evaluators can help scale up multilingual evaluation. Specifically, we calibrate LLM-based evaluation against 20k human judgments of five metrics across three text-generation tasks in eight languages. Our findings indicate that LLM-based evaluators may exhibit bias towards higher scores and should be used with caution and should always be calibrated with a dataset of native speaker judgments, particularly in low-resource and non-Latin script languages.
MEGA: Multilingual Evaluation of Generative AI
Apr 03, 2023



Generative AI models have impressive performance on many Natural Language Processing tasks such as language understanding, reasoning and language generation. One of the most important questions that is being asked by the AI community today is about the capabilities and limits of these models, and it is clear that evaluating generative AI is very challenging. Most studies on generative Large Language Models (LLMs) are restricted to English and it is unclear how capable these models are at understanding and generating other languages. We present the first comprehensive benchmarking of generative LLMs - MEGA, which evaluates models on standard NLP benchmarks, covering 8 diverse tasks and 33 typologically diverse languages. We also compare the performance of generative LLMs to State of the Art (SOTA) non-autoregressive models on these tasks to determine how well generative models perform compared to the previous generation of LLMs. We present a thorough analysis of the performance of models across languages and discuss some of the reasons why generative LLMs are currently not optimal for all languages. We create a framework for evaluating generative LLMs in the multilingual setting and provide directions for future progress in the field.
Learnings from Technological Interventions in a Low Resource Language: Enhancing Information Access in Gondi
Nov 29, 2022The primary obstacle to developing technologies for low-resource languages is the lack of representative, usable data. In this paper, we report the deployment of technology-driven data collection methods for creating a corpus of more than 60,000 translations from Hindi to Gondi, a low-resource vulnerable language spoken by around 2.3 million tribal people in south and central India. During this process, we help expand information access in Gondi across 2 different dimensions (a) The creation of linguistic resources that can be used by the community, such as a dictionary, children's stories, Gondi translations from multiple sources and an Interactive Voice Response (IVR) based mass awareness platform; (b) Enabling its use in the digital domain by developing a Hindi-Gondi machine translation model, which is compressed by nearly 4 times to enable it's edge deployment on low-resource edge devices and in areas of little to no internet connectivity. We also present preliminary evaluations of utilizing the developed machine translation model to provide assistance to volunteers who are involved in collecting more data for the target language. Through these interventions, we not only created a refined and evaluated corpus of 26,240 Hindi-Gondi translations that was used for building the translation model but also engaged nearly 850 community members who can help take Gondi onto the internet.
Too Brittle To Touch: Comparing the Stability of Quantization and Distillation Towards Developing Lightweight Low-Resource MT Models
Nov 09, 2022
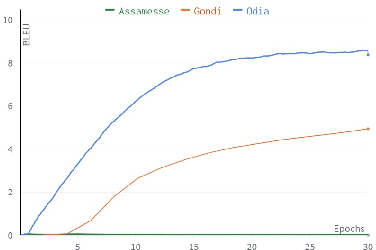
Leveraging shared learning through Massively Multilingual Models, state-of-the-art machine translation models are often able to adapt to the paucity of data for low-resource languages. However, this performance comes at the cost of significantly bloated models which are not practically deployable. Knowledge Distillation is one popular technique to develop competitive, lightweight models: In this work, we first evaluate its use to compress MT models focusing on languages with extremely limited training data. Through our analysis across 8 languages, we find that the variance in the performance of the distilled models due to their dependence on priors including the amount of synthetic data used for distillation, the student architecture, training hyperparameters and confidence of the teacher models, makes distillation a brittle compression mechanism. To mitigate this, we explore the use of post-training quantization for the compression of these models. Here, we find that while distillation provides gains across some low-resource languages, quantization provides more consistent performance trends for the entire range of languages, especially the lowest-resource languages in our target set.