 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPBench: A Multi-Video Perception Evaluation Benchmark for Multi-Modal Video Understanding
Mar 24, 2026The rapid progress of Large Language Models (LLMs) has spurred growing interest in Multi-modal LLMs (MLLMs) and motivated the development of benchmarks to evaluate their perceptual and comprehension abilities. Existing benchmarks, however, are limited to static images or single videos, overlooking the complex interactions across multiple videos. To address this gap, we introduce the Multi-Video Perception Evaluation Benchmark (MVPBench), a new benchmark featuring 14 subtasks across diverse visual domains designed to evaluate models on extracting relevant information from video sequences to make informed decisions. MVPBench includes 5K question-answering tests involving 2.7K video clips sourced from existing datasets and manually annotated clips. Extensive evaluations reveal that current models struggle to process multi-video inputs effectively, underscoring substantial limitations in their multi-video comprehension. We anticipate MVPBench will drive advancements in multi-video perception.
Mamba-VMR: Multimodal Query Augmentation via Generated Videos for Precise Temporal Grounding
Mar 23, 2026Text-driven video moment retrieval (VMR) remains challenging due to limited capture of hidden temporal dynamics in untrimmed videos, leading to imprecise grounding in long sequences. Traditional methods rely on natural language queries (NLQs) or static image augmentations, overlooking motion sequences and suffering from high computational costs in Transformer-based architectures. Existing approaches fail to integrate subtitle contexts and generated temporal priors effectively, we therefore propose a novel two-stage framework for enhanced temporal grounding. In the first stage, LLM-guided subtitle matching identifies relevant textual cues from video subtitles, fused with the query to generate auxiliary short videos via text-to-video models, capturing implicit motion information as temporal priors. In the second stage, augmented queries are processed through a multi-modal controlled Mamba network, extending text-controlled selection with video-guided gating for efficient fusion of generated priors and long sequences while filtering noise. Our framework is agnostic to base retrieval models and widely applicable for multimodal VMR. Experimental evaluations on the TVR benchmark demonstrate significant improvements over state-of-the-art methods, including reduced computational overhead and higher recall in long-sequence grounding.
Alignment Whack-a-Mole : Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models
Mar 21, 2026Frontier LLM companies have repeatedly assured courts and regulators that their models do not store copies of training data. They further rely on safety alignment strategies via RLHF, system prompts, and output filters to block verbatim regurgitation of copyrighted works, and have cited the efficacy of these measures in their legal defenses against copyright infringement claims. We show that finetuning bypasses these protections: by training models to expand plot summaries into full text, a task naturally suited for commercial writing assistants, we cause GPT-4o, Gemini-2.5-Pro, and DeepSeek-V3.1 to reproduce up to 85-90% of held-out copyrighted books, with single verbatim spans exceeding 460 words, using only semantic descriptions as prompts and no actual book text. This extraction generalizes across authors: finetuning exclusively on Haruki Murakami's novels unlocks verbatim recall of copyrighted books from over 30 unrelated authors. The effect is not specific to any training author or corpus: random author pairs and public-domain finetuning data produce comparable extraction, while finetuning on synthetic text yields near-zero extraction, indicating that finetuning on individual authors' works reactivates latent memorization from pretraining. Three models from different providers memorize the same books in the same regions ($r \ge 0.90$), pointing to an industry-wide vulnerability. Our findings offer compelling evidence that model weights store copies of copyrighted works and that the security failures that manifest after finetuning on individual authors' works undermine a key premise of recent fair use rulings, where courts have conditioned favorable outcomes on the adequacy of measures preventing reproduction of protected expression.
Beyond False Discovery Rate: A Stepdown Group SLOPE Approach for Grouped Variable Selection
Mar 01, 2026High-dimensional feature selection is routinely required to balance statistical power with strict control of multiple-error metrics such as the k-Family-Wise Error Rate (k-FWER) and the False Discovery Proportion (FDP), yet some existing frameworks are confined to the narrower goal of controlling the expected False Discovery Rate (FDR) and can not exploit the group-structure of the covariates, such as Sorted L-One Penalized Estimation (SLOPE). We introduce the Group Stepdown SLOPE, a unified optimization procedure which is capable of embedding the Lehmann-Romano stepdown rules into SLOPE to achieve finite-sample guarantees under k-FWER and FDP thresholds. Specifically, we derive closed-form regularization sequences under orthogonal designs that provably bound k-FWER and FDP at user-specified levels, and extend these results to grouped settings via gk-SLOPE and gF-SLOPE, which control the analogous group-level errors gk-FWER and gFDP. For non-orthogonal general designs, we provide a calibrated data-driven sequence inspired by Gaussian approximation and Monte-Carlo correction, preserving convexity and scalability. Extensive simulations are conducted across sparse, correlated, and group-structured regimes. Empirical results corroborate our theoretical findings that the proposed methods achieve nominal error control, while yielding markedly higher power than competing stepdown procedures, thereby confirming the practical value of the theoretical advances.
Boosting Meta-Learning for Few-Shot Text Classification via Label-guided Distance Scaling
Feb 28, 2026Few-shot text classification aims to recognize unseen classes with limited labeled text samples. Existing approaches focus on boosting meta-learners by developing complex algorithms in the training stage. However, the labeled samples are randomly selected during the testing stage, so they may not provide effective supervision signals, leading to misclassification. To address this issue, we propose a \textbf{L}abel-guided \textbf{D}istance \textbf{S}caling (LDS) strategy. The core of our method is exploiting label semantics as supervision signals in both the training and testing stages. Specifically, in the training stage, we design a label-guided loss to inject label semantic information, pulling closer the sample representations and corresponding label representations. In the testing stage, we propose a Label-guided Scaler which scales sample representations with label semantics to provide additional supervision signals. Thus, even if labeled sample representations are far from class centers, our Label-guided Scaler pulls them closer to their class centers, thereby mitigating the misclassification. We combine two common meta-learners to verify the effectiveness of the method. Extensive experimental results demonstrate that our approach significantly outperforms state-of-the-art models. All datasets and codes are available at https://anonymous.4open.science/r/Label-guided-Text-Classification.
Fence off Anomaly Interference: Cross-Domain Distillation for Fully Unsupervised Anomaly Detection
Aug 25, 2025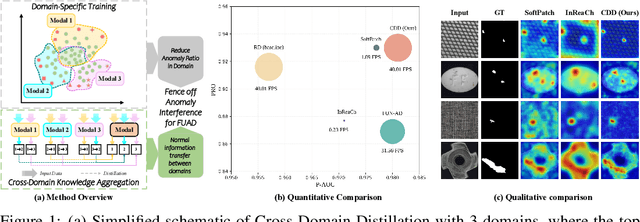

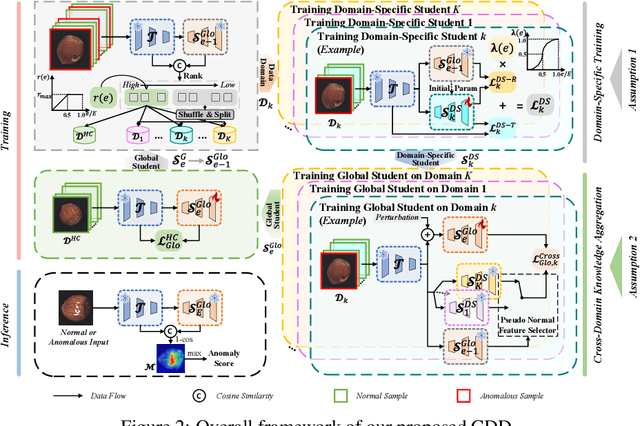
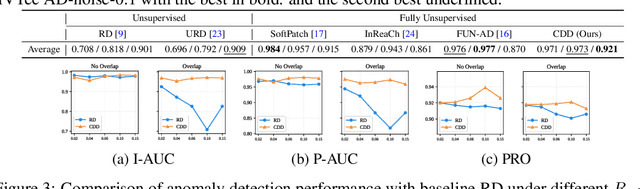
Fully Unsupervised Anomaly Detection (FUAD) is a practical extension of Unsupervised Anomaly Detection (UAD), aiming to detect anomalies without any labels even when the training set may contain anomalous samples. To achieve FUAD, we pioneer the introduction of Knowledge Distillation (KD) paradigm based on teacher-student framework into the FUAD setting. However, due to the presence of anomalies in the training data, traditional KD methods risk enabling the student to learn the teacher's representation of anomalies under FUAD setting, thereby resulting in poor anomaly detection performance. To address this issue, we propose a novel Cross-Domain Distillation (CDD) framework based on the widely studied reverse distillation (RD) paradigm. Specifically, we design a Domain-Specific Training, which divides the training set into multiple domains with lower anomaly ratios and train a domain-specific student for each. Cross-Domain Knowledge Aggregation is then performed, where pseudo-normal features generated by domain-specific students collaboratively guide a global student to learn generalized normal representations across all samples. Experimental results on noisy versions of the MVTec AD and VisA datasets demonstrate that our method achieves significant performance improvements over the baseline, validating its effectiveness under FUAD setting.
NoveltyBench: Evaluating Language Models for Humanlike Diversity
Apr 08, 2025Language models have demonstrated remarkable capabilities on standard benchmarks, yet they struggle increasingly from mode collapse, the inability to generate diverse and novel outputs. Our work introduces NoveltyBench, a benchmark specifically designed to evaluate the ability of language models to produce multiple distinct and high-quality outputs. NoveltyBench utilizes prompts curated to elicit diverse answers and filtered real-world user queries. Evaluating 20 leading language models, we find that current state-of-the-art systems generate significantly less diversity than human writers. Notably, larger models within a family often exhibit less diversity than their smaller counterparts, challenging the notion that capability on standard benchmarks translates directly to generative utility. While prompting strategies like in-context regeneration can elicit diversity, our findings highlight a fundamental lack of distributional diversity in current models, reducing their utility for users seeking varied responses and suggesting the need for new training and evaluation paradigms that prioritize diversity alongside quality.
Hawkes based Representation Learning for Reasoning over Scale-free Community-structured Temporal Knowledge Graphs
Dec 28, 2024Temporal knowledge graph (TKG) reasoning has become a hot topic due to its great value in many practical tasks. The key to TKG reasoning is modeling the structural information and evolutional patterns of the TKGs. While great efforts have been devoted to TKG reasoning, the structural and evolutional characteristics of real-world networks have not been considered. In the aspect of structure, real-world networks usually exhibit clear community structure and scale-free (long-tailed distribution) properties. In the aspect of evolution, the impact of an event decays with the time elapsing. In this paper, we propose a novel TKG reasoning model called Hawkes process-based Evolutional Representation Learning Network (HERLN), which learns structural information and evolutional patterns of a TKG simultaneously, considering the characteristics of real-world networks: community structure, scale-free and temporal decaying. First, we find communities in the input TKG to make the encoding get more similar intra-community embeddings. Second, we design a Hawkes process-based relational graph convolutional network to cope with the event impact-decaying phenomenon. Third, we design a conditional decoding method to alleviate biases towards frequent entities caused by long-tailed distribution. Experimental results show that HERLN achieves significant improvements over the state-of-the-art models.
Unlocking the Potential of Reverse Distillation for Anomaly Detection
Dec 10, 2024Knowledge Distillation (KD) is a promising approach for unsupervised Anomaly Detection (AD). However, the student network's over-generalization often diminishes the crucial representation differences between teacher and student in anomalous regions, leading to detection failures. To addresses this problem, the widely accepted Reverse Distillation (RD) paradigm designs the asymmetry teacher and student, using an encoder as teacher and a decoder as student. Yet, the design of RD does not ensure that the teacher encoder effectively distinguishes between normal and abnormal features or that the student decoder generates anomaly-free features. Additionally, the absence of skip connections results in a loss of fine details during feature reconstruction. To address these issues, we propose RD with Expert, which introduces a novel Expert-Teacher-Student network for simultaneous distillation of both the teacher encoder and student decoder. The added expert network enhances the student's ability to generate normal features and optimizes the teacher's differentiation between normal and abnormal features, reducing missed detections. Additionally, Guided Information Injection is designed to filter and transfer features from teacher to student, improving detail reconstruction and minimizing false positives. Experiments on several benchmarks prove that our method outperforms existing unsupervised AD methods under RD paradigm, fully unlocking RD's potential.
ONER: Online Experience Replay for Incremental Anomaly Detection
Dec 05, 2024Incremental anomaly detection sequentially recognizes abnormal regions in novel categories for dynamic industrial scenarios. This remains highly challenging due to knowledge overwriting and feature conflicts, leading to catastrophic forgetting. In this work, we propose ONER, an end-to-end ONline Experience Replay method, which efficiently mitigates catastrophic forgetting while adapting to new tasks with minimal cost. Specifically, our framework utilizes two types of experiences from past tasks: decomposed prompts and semantic prototypes, addressing both model parameter updates and feature optimization. The decomposed prompts consist of learnable components that assemble to produce attention-conditioned prompts. These prompts reuse previously learned knowledge, enabling model to learn novel tasks effectively. The semantic prototypes operate at both pixel and image levels, performing regularization in the latent feature space to prevent forgetting across various tasks. Extensive experiments demonstrate that our method achieves state-of-the-art performance in incremental anomaly detection with significantly reduced forgetting, as well as efficiently adapting to new categories with minimal costs. These results confirm the efficiency and stability of ONER, making it a powerful solution for real-world applications.