 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Swarm Learning meets energy series data: A decentralized collaborative learning design based on blockchain
Jun 07, 2024
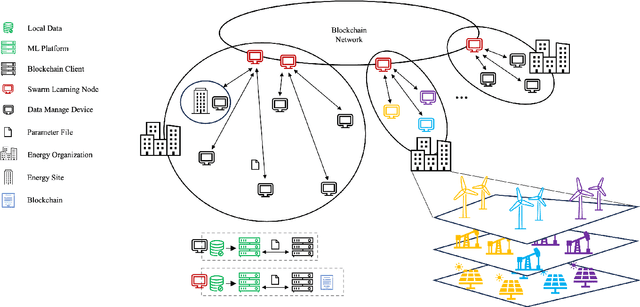


Machine learning models offer the capability to forecast future energy production or consumption and infer essential unknown variables from existing data. However, legal and policy constraints within specific energy sectors render the data sensitive, presenting technical hurdles in utilizing data from diverse sources. Therefore, we propose adopting a Swarm Learning (SL) scheme, which replaces the centralized server with a blockchain-based distributed network to address the security and privacy issues inherent in Federated Learning (FL)'s centralized architecture. Within this distributed Collaborative Learning framework, each participating organization governs nodes for inter-organizational communication. Devices from various organizations utilize smart contracts for parameter uploading and retrieval. Consensus mechanism ensures distributed consistency throughout the learning process, guarantees the transparent trustworthiness and immutability of parameters on-chain. The efficacy of the proposed framework is substantiated across three real-world energy series modeling scenarios with superior performance compared to Local Learning approaches, simultaneously emphasizing enhanced data security and privacy over Centralized Learning and FL method. Notably, as the number of data volume and the count of local epochs increases within a threshold, there is an improvement in model performance accompanied by a reduction in the variance of performance errors. Consequently, this leads to an increased stability and reliability in the outcomes produced by the model.
LLM4ED: Large Language Models for Automatic Equation Discovery
May 13, 2024



Equation discovery is aimed at directly extracting physical laws from data and has emerged as a pivotal research domain. Previous methods based on symbolic mathematics have achieved substantial advancements, but often require the design of implementation of complex algorithms. In this paper, we introduce a new framework that utilizes natural language-based prompts to guide large language models (LLMs) in automatically mining governing equations from data. Specifically, we first utilize the generation capability of LLMs to generate diverse equations in string form, and then evaluate the generated equations based on observations. In the optimization phase, we propose two alternately iterated strategies to optimize generated equations collaboratively. The first strategy is to take LLMs as a black-box optimizer and achieve equation self-improvement based on historical samples and their performance. The second strategy is to instruct LLMs to perform evolutionary operators for global search. Experiments are extensively conducted on both partial differential equations and ordinary differential equations. Results demonstrate that our framework can discover effective equations to reveal the underlying physical laws under various nonlinear dynamic systems. Further comparisons are made with state-of-the-art models, demonstrating good stability and usability. Our framework substantially lowers the barriers to learning and applying equation discovery techniques, demonstrating the application potential of LLMs in the field of knowledge discovery.
A knowledge-based data-driven framework for all-day identification of cloud types using satellite remote sensing
Dec 01, 2023
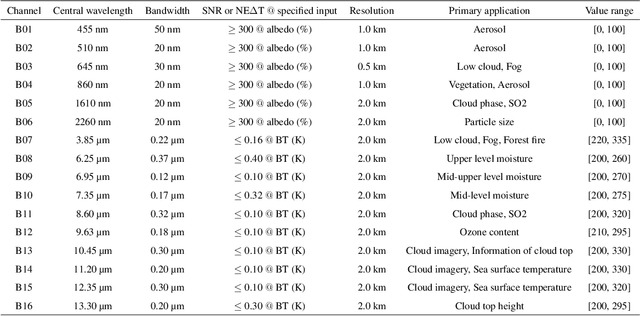
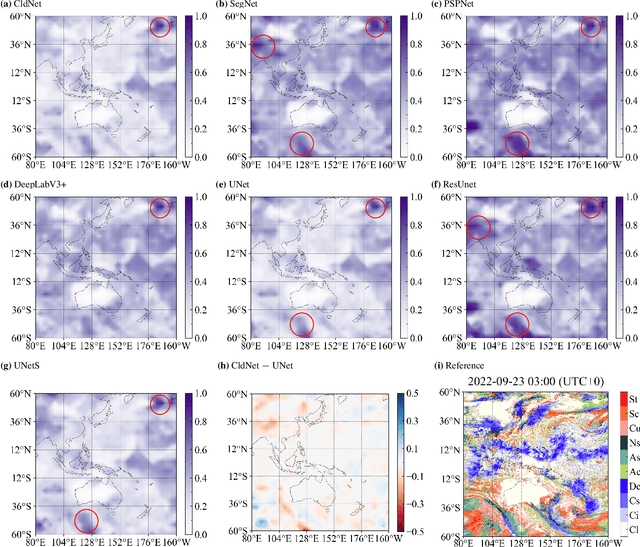
Cloud types, as a type of meteorological data, are of particular significance for evaluating changes in rainfall, heatwaves, water resources, floods and droughts, food security and vegetation cover, as well as land use. In order to effectively utilize high-resolution geostationary observations, a knowledge-based data-driven (KBDD) framework for all-day identification of cloud types based on spectral information from Himawari-8/9 satellite sensors is designed. And a novel, simple and efficient network, named CldNet, is proposed. Compared with widely used semantic segmentation networks, including SegNet, PSPNet, DeepLabV3+, UNet, and ResUnet, our proposed model CldNet with an accuracy of 80.89+-2.18% is state-of-the-art in identifying cloud types and has increased by 32%, 46%, 22%, 2%, and 39%, respectively. With the assistance of auxiliary information (e.g., satellite zenith/azimuth angle, solar zenith/azimuth angle), the accuracy of CldNet-W using visible and near-infrared bands and CldNet-O not using visible and near-infrared bands on the test dataset is 82.23+-2.14% and 73.21+-2.02%, respectively. Meanwhile, the total parameters of CldNet are only 0.46M, making it easy for edge deployment. More importantly, the trained CldNet without any fine-tuning can predict cloud types with higher spatial resolution using satellite spectral data with spatial resolution 0.02{\deg}*0.02{\deg}, which indicates that CldNet possesses a strong generalization ability. In aggregate, the KBDD framework using CldNet is a highly effective cloud-type identification system capable of providing a high-fidelity, all-day, spatiotemporal cloud-type database for many climate assessment fields.
QIENet: Quantitative irradiance estimation network using recurrent neural network based on satellite remote sensing data
Dec 01, 2023



Global horizontal irradiance (GHI) plays a vital role in estimating solar energy resources, which are used to generate sustainable green energy. In order to estimate GHI with high spatial resolution, a quantitative irradiance estimation network, named QIENet, is proposed. Specifically, the temporal and spatial characteristics of remote sensing data of the satellite Himawari-8 are extracted and fused by recurrent neural network (RNN) and convolution operation, respectively. Not only remote sensing data, but also GHI-related time information (hour, day, and month) and geographical information (altitude, longitude, and latitude), are used as the inputs of QIENet. The satellite spectral channels B07 and B11 - B15 and time are recommended as model inputs for QIENet according to the spatial distributions of annual solar energy. Meanwhile, QIENet is able to capture the impact of various clouds on hourly GHI estimates. More importantly, QIENet does not overestimate ground observations and can also reduce RMSE by 27.51%/18.00%, increase R2 by 20.17%/9.42%, and increase r by 8.69%/3.54% compared with ERA5/NSRDB. Furthermore, QIENet is capable of providing a high-fidelity hourly GHI database with spatial resolution 0.02{\deg} * 0.02{\deg}(approximately 2km * 2km) for many applied energy fields.
Physics-constrained robust learning of open-form PDEs from limited and noisy data
Sep 14, 2023Unveiling the underlying governing equations of nonlinear dynamic systems remains a significant challenge, especially when encountering noisy observations and no prior knowledge available. This study proposes R-DISCOVER, a framework designed to robustly uncover open-form partial differential equations (PDEs) from limited and noisy data. The framework operates through two alternating update processes: discovering and embedding. The discovering phase employs symbolic representation and a reinforcement learning (RL)-guided hybrid PDE generator to efficiently produce diverse open-form PDEs with tree structures. A neural network-based predictive model fits the system response and serves as the reward evaluator for the generated PDEs. PDEs with superior fits are utilized to iteratively optimize the generator via the RL method and the best-performing PDE is selected by a parameter-free stability metric. The embedding phase integrates the initially identified PDE from the discovering process as a physical constraint into the predictive model for robust training. The traversal of PDE trees automates the construction of the computational graph and the embedding process without human intervention. Numerical experiments demonstrate our framework's capability to uncover governing equations from nonlinear dynamic systems with limited and highly noisy data and outperform other physics-informed neural network-based discovery methods. This work opens new potential for exploring real-world systems with limited understanding.