 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTREAM: A Data-Centric Framework for Mining High-Value Task-Oriented Dialogues from Streaming Media
May 24, 2026Large language models for vertical domains are bottlenecked by the scarcity of complex, domain-specific task-oriented dialogues. Existing data acquisition pipelines face a persistent trilemma: expert annotation is expensive, real-world service conversations are constrained by privacy and commercial restrictions, and static corpora quickly become temporally stale. We propose Stream, a data-centric framework that leverages publicly available streaming media (live streams and short videos) to synthesize high-value service dialogues at scale. Stream mines authentic interaction signals from noisy streams and synthesizes conversations by integrating role-grounded persona construction with Conversational Blueprint construction; it further adopts retrieval-augmented generation (RAG) to support knowledge-aware responses. Based on Stream, we release StreamDial, a large-scale multi-domain dataset covering Automotive, Restaurant, and Hotel. StreamDial contains 87,498 dialogue sessions and 1,497,320 turns in total, with an average of 17.11 turns per session and a comparable scale across domains. Each session is organized as a structured quadruplet $\langle P_u, P_a, B, H \rangle$ that pairs dialogue history with explicit user/agent personas and a Conversational Blueprint, capturing realistic service behaviors such as requirement mining, constraint conflicts, negotiation, and recovery. Evaluations with automatic judges and downstream tasks show that StreamDial improves intrinsic dialogue quality over strong baselines, and models trained with StreamDial improve Dialogue State Tracking across backbones; we further report a completed human-evaluation set and encouraging multilingual transfer on Qwen3-8B under a controlled training budget. The data is released in https://github.com/hitxueliang/DialogDataSetBySTREAM.
MME-RAG: Multi-Manager-Expert Retrieval-Augmented Generation for Fine-Grained Entity Recognition in Task-Oriented Dialogues
Nov 15, 2025Fine-grained entity recognition is crucial for reasoning and decision-making in task-oriented dialogues, yet current large language models (LLMs) continue to face challenges in domain adaptation and retrieval controllability. We introduce MME-RAG, a Multi-Manager-Expert Retrieval-Augmented Generation framework that decomposes entity recognition into two coordinated stages: type-level judgment by lightweight managers and span-level extraction by specialized experts. Each expert is supported by a KeyInfo retriever that injects semantically aligned, few-shot exemplars during inference, enabling precise and domain-adaptive extraction without additional training. Experiments on CrossNER, MIT-Movie, MIT-Restaurant, and our newly constructed multi-domain customer-service dataset demonstrate that MME-RAG performs better than recent baselines in most domains. Ablation studies further show that both the hierarchical decomposition and KeyInfo-guided retrieval are key drivers of robustness and cross-domain generalization, establishing MME-RAG as a scalable and interpretable solution for adaptive dialogue understanding.
Privacy-Preserving Explainable AIoT Application via SHAP Entropy Regularization
Nov 12, 2025



The widespread integration of Artificial Intelligence of Things (AIoT) in smart home environments has amplified the demand for transparent and interpretable machine learning models. To foster user trust and comply with emerging regulatory frameworks, the Explainable AI (XAI) methods, particularly post-hoc techniques such as SHapley Additive exPlanations (SHAP), and Local Interpretable Model-Agnostic Explanations (LIME), are widely employed to elucidate model behavior. However, recent studies have shown that these explanation methods can inadvertently expose sensitive user attributes and behavioral patterns, thereby introducing new privacy risks. To address these concerns, we propose a novel privacy-preserving approach based on SHAP entropy regularization to mitigate privacy leakage in explainable AIoT applications. Our method incorporates an entropy-based regularization objective that penalizes low-entropy SHAP attribution distributions during training, promoting a more uniform spread of feature contributions. To evaluate the effectiveness of our approach, we developed a suite of SHAP-based privacy attacks that strategically leverage model explanation outputs to infer sensitive information. We validate our method through comparative evaluations using these attacks alongside utility metrics on benchmark smart home energy consumption datasets. Experimental results demonstrate that SHAP entropy regularization substantially reduces privacy leakage compared to baseline models, while maintaining high predictive accuracy and faithful explanation fidelity. This work contributes to the development of privacy-preserving explainable AI techniques for secure and trustworthy AIoT applications.
Enhancing Adversarial Robustness of IoT Intrusion Detection via SHAP-Based Attribution Fingerprinting
Nov 09, 2025The rapid proliferation of Internet of Things (IoT) devices has transformed numerous industries by enabling seamless connectivity and data-driven automation. However, this expansion has also exposed IoT networks to increasingly sophisticated security threats, including adversarial attacks targeting artificial intelligence (AI) and machine learning (ML)-based intrusion detection systems (IDS) to deliberately evade detection, induce misclassification, and systematically undermine the reliability and integrity of security defenses. To address these challenges, we propose a novel adversarial detection model that enhances the robustness of IoT IDS against adversarial attacks through SHapley Additive exPlanations (SHAP)-based fingerprinting. Using SHAP's DeepExplainer, we extract attribution fingerprints from network traffic features, enabling the IDS to reliably distinguish between clean and adversarially perturbed inputs. By capturing subtle attribution patterns, the model becomes more resilient to evasion attempts and adversarial manipulations. We evaluated the model on a standard IoT benchmark dataset, where it significantly outperformed a state-of-the-art method in detecting adversarial attacks. In addition to enhanced robustness, this approach improves model transparency and interpretability, thereby increasing trust in the IDS through explainable AI.
SEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
Dec 14, 2024



Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
Benchmarking Multi-Scene Fire and Smoke Detection
Oct 22, 2024The current irregularities in existing public Fire and Smoke Detection (FSD) datasets have become a bottleneck in the advancement of FSD technology. Upon in-depth analysis, we identify the core issue as the lack of standardized dataset construction, uniform evaluation systems, and clear performance benchmarks. To address this issue and drive innovation in FSD technology, we systematically gather diverse resources from public sources to create a more comprehensive and refined FSD benchmark. Additionally, recognizing the inadequate coverage of existing dataset scenes, we strategically expand scenes, relabel, and standardize existing public FSD datasets to ensure accuracy and consistency. We aim to establish a standardized, realistic, unified, and efficient FSD research platform that mirrors real-life scenes closely. Through our efforts, we aim to provide robust support for the breakthrough and development of FSD technology. The project is available at \href{https://xiaoyihan6.github.io/FSD/}{https://xiaoyihan6.github.io/FSD/}.
When Swarm Learning meets energy series data: A decentralized collaborative learning design based on blockchain
Jun 07, 2024
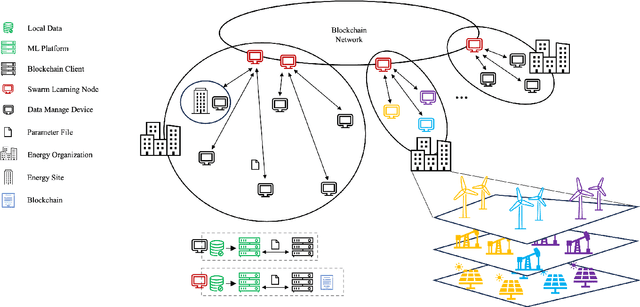


Machine learning models offer the capability to forecast future energy production or consumption and infer essential unknown variables from existing data. However, legal and policy constraints within specific energy sectors render the data sensitive, presenting technical hurdles in utilizing data from diverse sources. Therefore, we propose adopting a Swarm Learning (SL) scheme, which replaces the centralized server with a blockchain-based distributed network to address the security and privacy issues inherent in Federated Learning (FL)'s centralized architecture. Within this distributed Collaborative Learning framework, each participating organization governs nodes for inter-organizational communication. Devices from various organizations utilize smart contracts for parameter uploading and retrieval. Consensus mechanism ensures distributed consistency throughout the learning process, guarantees the transparent trustworthiness and immutability of parameters on-chain. The efficacy of the proposed framework is substantiated across three real-world energy series modeling scenarios with superior performance compared to Local Learning approaches, simultaneously emphasizing enhanced data security and privacy over Centralized Learning and FL method. Notably, as the number of data volume and the count of local epochs increases within a threshold, there is an improvement in model performance accompanied by a reduction in the variance of performance errors. Consequently, this leads to an increased stability and reliability in the outcomes produced by the model.
Joint Association, Beamforming, and Resource Allocation for Multi-IRS Enabled MU-MISO Systems With RSMA
Jun 05, 2024



Intelligent reflecting surface (IRS) and rate-splitting multiple access (RSMA) technologies are at the forefront of enhancing spectrum and energy efficiency in the next generation multi-antenna communication systems. This paper explores a RSMA system with multiple IRSs, and proposes two purpose-driven scheduling schemes, i.e., the exhaustive IRS-aided (EIA) and opportunistic IRS-aided (OIA) schemes. The aim is to optimize the system weighted energy efficiency (EE) under the above two schemes, respectively. Specifically, the Dinkelbach, branch and bound, successive convex approximation, and the semidefinite relaxation methods are exploited within the alternating optimization framework to obtain effective solutions to the considered problems. The numerical findings indicate that the EIA scheme exhibits better performance compared to the OIA scheme in diverse scenarios when considering the weighted EE, and the proposed algorithm demonstrates superior performance in comparison to the baseline algorithms.
Sentence Bag Graph Formulation for Biomedical Distant Supervision Relation Extraction
Oct 29, 2023



We introduce a novel graph-based framework for alleviating key challenges in distantly-supervised relation extraction and demonstrate its effectiveness in the challenging and important domain of biomedical data. Specifically, we propose a graph view of sentence bags referring to an entity pair, which enables message-passing based aggregation of information related to the entity pair over the sentence bag. The proposed framework alleviates the common problem of noisy labeling in distantly supervised relation extraction and also effectively incorporates inter-dependencies between sentences within a bag. Extensive experiments on two large-scale biomedical relation datasets and the widely utilized NYT dataset demonstrate that our proposed framework significantly outperforms the state-of-the-art methods for biomedical distant supervision relation extraction while also providing excellent performance for relation extraction in the general text mining domain.
Document Layout Analysis with Aesthetic-Guided Image Augmentation
Nov 27, 2021


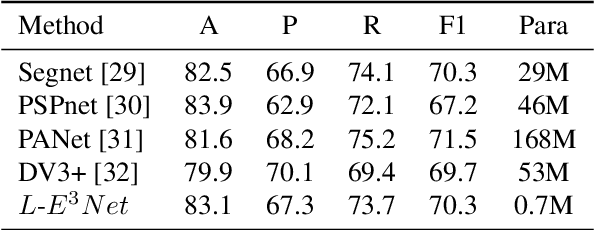
Document layout analysis (DLA) plays an important role in information extraction and document understanding. At present, document layout analysis has reached a milestone achievement, however, document layout analysis of non-Manhattan is still a challenge. In this paper, we propose an image layer modeling method to tackle this challenge. To measure the proposed image layer modeling method, we propose a manually-labeled non-Manhattan layout fine-grained segmentation dataset named FPD. As far as we know, FPD is the first manually-labeled non-Manhattan layout fine-grained segmentation dataset. To effectively extract fine-grained features of documents, we propose an edge embedding network named L-E^3Net. Experimental results prove that our proposed image layer modeling method can better deal with the fine-grained segmented document of the non-Manhattan layout.