 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCTEFuse: Illumination-Gated Mixture of Chiral Transformer Experts for Multi-Level Infrared and Visible Image Fusion
Jul 27, 2025



While illumination changes inevitably affect the quality of infrared and visible image fusion, many outstanding methods still ignore this factor and directly merge the information from source images, leading to modality bias in the fused results. To this end, we propose a dynamic multi-level image fusion network called MoCTEFuse, which applies an illumination-gated Mixture of Chiral Transformer Experts (MoCTE) to adaptively preserve texture details and object contrasts in balance. MoCTE consists of high- and low-illumination expert subnetworks, each built upon the Chiral Transformer Fusion Block (CTFB). Guided by the illumination gating signals, CTFB dynamically switches between the primary and auxiliary modalities as well as assigning them corresponding weights with its asymmetric cross-attention mechanism. Meanwhile, it is stacked at multiple stages to progressively aggregate and refine modality-specific and cross-modality information. To facilitate robust training, we propose a competitive loss function that integrates illumination distributions with three levels of sub-loss terms. Extensive experiments conducted on the DroneVehicle, MSRS, TNO and RoadScene datasets show MoCTEFuse's superior fusion performance. Finally, it achieves the best detection mean Average Precision (mAP) of 70.93% on the MFNet dataset and 45.14% on the DroneVehicle dataset. The code and model are released at https://github.com/Bitlijinfu/MoCTEFuse.
SEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
Dec 14, 2024



Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
They are Not Completely Useless: Towards Recycling Transferable Unlabeled Data for Class-Mismatched Semi-Supervised Learning
Nov 27, 2020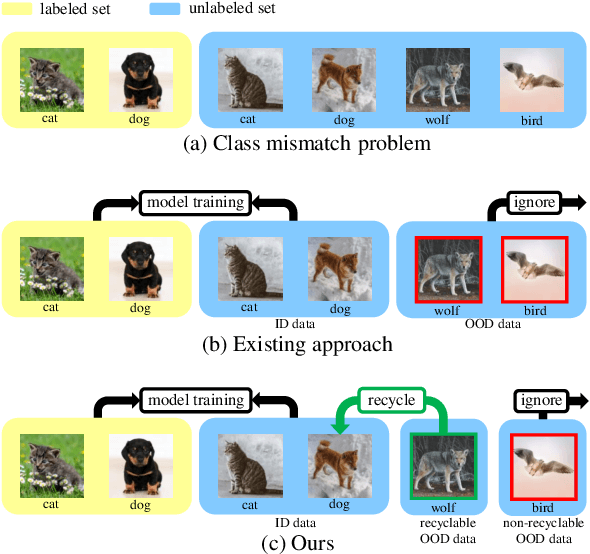

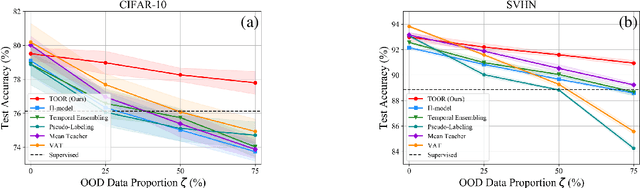
Semi-Supervised Learning (SSL) with mismatched classes deals with the problem that the classes-of-interests in the limited labeled data is only a subset of the classes in massive unlabeled data. As a result, the classes only possessed by the unlabeled data may mislead the classifier training and thus hindering the realistic landing of various SSL methods. To solve this problem, existing methods usually divide unlabeled data to in-distribution (ID) data and out-of-distribution (OOD) data, and directly discard or weaken the OOD data to avoid their adverse impact. In other words, they treat OOD data as completely useless and thus the potential valuable information for classification contained by them is totally ignored. To remedy this defect, this paper proposes a "Transferable OOD data Recycling" (TOOR) method which properly utilizes ID data as well as the "recyclable" OOD data to enrich the information for conducting class-mismatched SSL. Specifically, TOOR firstly attributes all unlabeled data to ID data or OOD data, among which the ID data are directly used for training. Then we treat the OOD data that have a close relationship with ID data and labeled data as recyclable, and employ adversarial domain adaptation to project them to the space of ID data and labeled data. In other words, the recyclability of an OOD datum is evaluated by its transferability, and the recyclable OOD data are transferred so that they are compatible with the distribution of known classes-of-interests. Consequently, our TOOR method extracts more information from unlabeled data than existing approaches, so it can achieve the improved performance which is demonstrated by the experiments on typical benchmark datasets.
Understanding the Disharmony between Weight Normalization Family and Weight Decay: $ε-$shifted $L_2$ Regularizer
Nov 14, 2019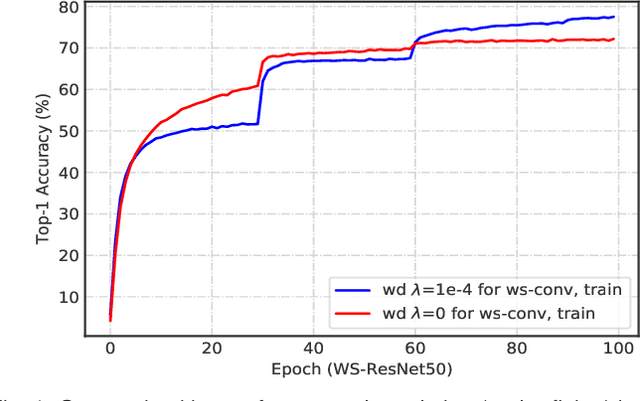

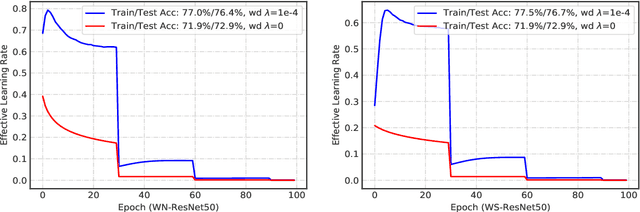
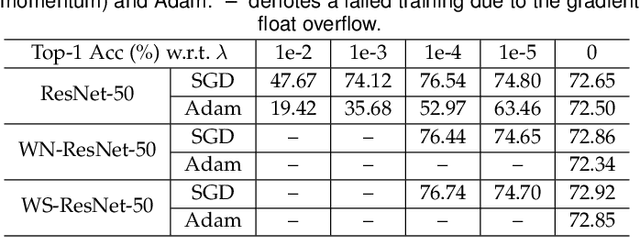
The merits of fast convergence and potentially better performance of the weight normalization family have drawn increasing attention in recent years. These methods use standardization or normalization that changes the weight $\boldsymbol{W}$ to $\boldsymbol{W}'$, which makes $\boldsymbol{W}'$ independent to the magnitude of $\boldsymbol{W}$. Surprisingly, $\boldsymbol{W}$ must be decayed during gradient descent, otherwise we will observe a severe under-fitting problem, which is very counter-intuitive since weight decay is widely known to prevent deep networks from over-fitting. In this paper, we \emph{theoretically} prove that the weight decay term $\frac{1}{2}\lambda||{\boldsymbol{W}}||^2$ merely modulates the effective learning rate for improving objective optimization, and has no influence on generalization when the weight normalization family is compositely employed. Furthermore, we also expose several critical problems when introducing weight decay term to weight normalization family, including the missing of global minimum and training instability. To address these problems, we propose an $\epsilon-$shifted $L_2$ regularizer, which shifts the $L_2$ objective by a positive constant $\epsilon$. Such a simple operation can theoretically guarantee the existence of global minimum, while preventing the network weights from being too small and thus avoiding gradient float overflow. It significantly improves the training stability and can achieve slightly better performance in our practice. The effectiveness of $\epsilon-$shifted $L_2$ regularizer is comprehensively validated on the ImageNet, CIFAR-100, and COCO datasets. Our codes and pretrained models will be released in https://github.com/implus/PytorchInsight.