 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond N-gram: Data-Aware X-GRAM Extraction for Efficient Embedding Parameter Scaling
Apr 23, 2026Large token-indexed lookup tables provide a compute-decoupled scaling path, but their practical gains are often limited by poor parameter efficiency and rapid memory growth. We attribute these limitations to Zipfian under-training of the long tail, heterogeneous demand across layers, and "slot collapse" that produces redundant embeddings. To address this, we propose X-GRAM, a frequency-aware dynamic token-injection framework. X-GRAM employs hybrid hashing and alias mixing to compress the tail while preserving head capacity, and refines retrieved vectors via normalized SwiGLU ShortConv to extract diverse local n-gram features. These signals are integrated into attention value streams and inter-layer residuals using depth-aware gating, effectively aligning static memory with dynamic context. This design introduces a memory-centric scaling axis that decouples model capacity from FLOPs. Extensive evaluations at the 0.73B and 1.15B scales show that X-GRAM improves average accuracy by as much as 4.4 points over the vanilla backbone and 3.2 points over strong retrieval baselines, while using substantially smaller tables in the 50% configuration. Overall, by decoupling capacity from compute through efficient memory management, X-GRAM offers a scalable and practical paradigm for future memory-augmented architectures. Code aviliable in https://github.com/Longyichen/X-gram.
Controlled LLM Training on Spectral Sphere
Jan 13, 2026Scaling large models requires optimization strategies that ensure rapid convergence grounded in stability. Maximal Update Parametrization ($\boldsymbolμ$P) provides a theoretical safeguard for width-invariant $Θ(1)$ activation control, whereas emerging optimizers like Muon are only ``half-aligned'' with these constraints: they control updates but allow weights to drift. To address this limitation, we introduce the \textbf{Spectral Sphere Optimizer (SSO)}, which enforces strict module-wise spectral constraints on both weights and their updates. By deriving the steepest descent direction on the spectral sphere, SSO realizes a fully $\boldsymbolμ$P-aligned optimization process. To enable large-scale training, we implement SSO as an efficient parallel algorithm within Megatron. Through extensive pretraining on diverse architectures, including Dense 1.7B, MoE 8B-A1B, and 200-layer DeepNet models, SSO consistently outperforms AdamW and Muon. Furthermore, we observe significant practical stability benefits, including improved MoE router load balancing, suppressed outliers, and strictly bounded activations.
Universal Reasoning Model
Dec 24, 2025Universal transformers (UTs) have been widely used for complex reasoning tasks such as ARC-AGI and Sudoku, yet the specific sources of their performance gains remain underexplored. In this work, we systematically analyze UTs variants and show that improvements on ARC-AGI primarily arise from the recurrent inductive bias and strong nonlinear components of Transformer, rather than from elaborate architectural designs. Motivated by this finding, we propose the Universal Reasoning Model (URM), which enhances the UT with short convolution and truncated backpropagation. Our approach substantially improves reasoning performance, achieving state-of-the-art 53.8% pass@1 on ARC-AGI 1 and 16.0% pass@1 on ARC-AGI 2. Our code is avaliable at https://github.com/UbiquantAI/URM.
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Feb 20, 2025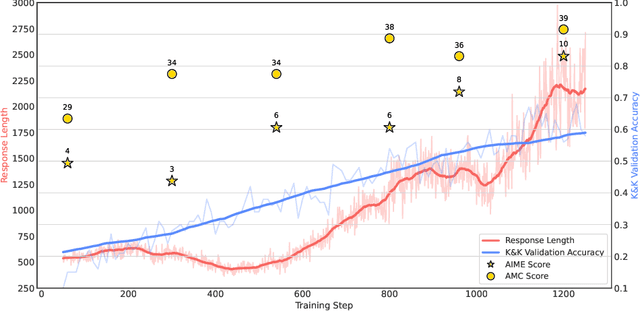



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in large reasoning models. To analyze reasoning dynamics, we use synthetic logic puzzles as training data due to their controllable complexity and straightforward answer verification. We make some key technical contributions that lead to effective and stable RL training: a system prompt that emphasizes the thinking and answering process, a stringent format reward function that penalizes outputs for taking shortcuts, and a straightforward training recipe that achieves stable convergence. Our 7B model develops advanced reasoning skills-such as reflection, verification, and summarization-that are absent from the logic corpus. Remarkably, after training on just 5K logic problems, it demonstrates generalization abilities to the challenging math benchmarks AIME and AMC.
SEW: Self-calibration Enhanced Whole Slide Pathology Image Analysis
Dec 14, 2024



Pathology images are considered the "gold standard" for cancer diagnosis and treatment, with gigapixel images providing extensive tissue and cellular information. Existing methods fail to simultaneously extract global structural and local detail f
Efficient and Comprehensive Feature Extraction in Large Vision-Language Model for Clinical Pathology Analysis
Dec 12, 2024Pathological diagnosis is vital for determining disease characteristics, guiding treatment, and assessing prognosis, relying heavily on detailed, multi-scale analysis of high-resolution whole slide images (WSI). However, traditional pure vision models face challenges of redundant feature extraction, whereas existing large vision-language models (LVLMs) are limited by input resolution constraints, hindering their efficiency and accuracy. To overcome these issues, we propose two innovative strategies: the mixed task-guided feature enhancement, which directs feature extraction toward lesion-related details across scales, and the prompt-guided detail feature completion, which integrates coarse- and fine-grained features from WSI based on specific prompts without compromising inference speed. Leveraging a comprehensive dataset of 490,000 samples from diverse pathology tasks-including cancer detection, grading, vascular and neural invasion identification, and so on-we trained the pathology-specialized LVLM, OmniPath. Extensive experiments demonstrate that this model significantly outperforms existing methods in diagnostic accuracy and efficiency, offering an interactive, clinically aligned approach for auxiliary diagnosis in a wide range of pathology applications.
Serialized Point Mamba: A Serialized Point Cloud Mamba Segmentation Model
Jul 17, 2024



Point cloud segmentation is crucial for robotic visual perception and environmental understanding, enabling applications such as robotic navigation and 3D reconstruction. However, handling the sparse and unordered nature of point cloud data presents challenges for efficient and accurate segmentation. Inspired by the Mamba model's success in natural language processing, we propose the Serialized Point Cloud Mamba Segmentation Model (Serialized Point Mamba), which leverages a state-space model to dynamically compress sequences, reduce memory usage, and enhance computational efficiency. Serialized Point Mamba integrates local-global modeling capabilities with linear complexity, achieving state-of-the-art performance on both indoor and outdoor datasets. This approach includes novel techniques such as staged point cloud sequence learning, grid pooling, and Conditional Positional Encoding, facilitating effective segmentation across diverse point cloud tasks. Our method achieved 76.8 mIoU on Scannet and 70.3 mIoU on S3DIS. In Scannetv2 instance segmentation, it recorded 40.0 mAP. It also had the lowest latency and reasonable memory use, making it the SOTA among point semantic segmentation models based on mamba.