 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Terminal Agentic Trajectory Generation from Dockerized Environments
Feb 03, 2026Training agentic models for terminal-based tasks critically depends on high-quality terminal trajectories that capture realistic long-horizon interactions across diverse domains. However, constructing such data at scale remains challenging due to two key requirements: \textbf{\emph{Executability}}, since each instance requires a suitable and often distinct Docker environment; and \textbf{\emph{Verifiability}}, because heterogeneous task outputs preclude unified, standardized verification. To address these challenges, we propose \textbf{TerminalTraj}, a scalable pipeline that (i) filters high-quality repositories to construct Dockerized execution environments, (ii) generates Docker-aligned task instances, and (iii) synthesizes agent trajectories with executable validation code. Using TerminalTraj, we curate 32K Docker images and generate 50,733 verified terminal trajectories across eight domains. Models trained on this data with the Qwen2.5-Coder backbone achieve consistent performance improvements on TerminalBench (TB), with gains of up to 20\% on TB~1.0 and 10\% on TB~2.0 over their respective backbones. Notably, \textbf{TerminalTraj-32B} achieves strong performance among models with fewer than 100B parameters, reaching 35.30\% on TB~1.0 and 22.00\% on TB~2.0, and demonstrates improved test-time scaling behavior. All code and data are available at https://github.com/Wusiwei0410/TerminalTraj.
AGRO-SQL: Agentic Group-Relative Optimization with High-Fidelity Data Synthesis
Dec 29, 2025The advancement of Text-to-SQL systems is currently hindered by the scarcity of high-quality training data and the limited reasoning capabilities of models in complex scenarios. In this paper, we propose a holistic framework that addresses these issues through a dual-centric approach. From a Data-Centric perspective, we construct an iterative data factory that synthesizes RL-ready data characterized by high correctness and precise semantic-logic alignment, ensured by strict verification. From a Model-Centric perspective, we introduce a novel Agentic Reinforcement Learning framework. This framework employs a Diversity-Aware Cold Start stage to initialize a robust policy, followed by Group Relative Policy Optimization (GRPO) to refine the agent's reasoning via environmental feedback. Extensive experiments on BIRD and Spider benchmarks demonstrate that our synergistic approach achieves state-of-the-art performance among single-model methods.
M2G-Eval: Enhancing and Evaluating Multi-granularity Multilingual Code Generation
Dec 27, 2025The rapid advancement of code large language models (LLMs) has sparked significant research interest in systematically evaluating their code generation capabilities, yet existing benchmarks predominantly assess models at a single structural granularity and focus on limited programming languages, obscuring fine-grained capability variations across different code scopes and multilingual scenarios. We introduce M2G-Eval, a multi-granularity, multilingual framework for evaluating code generation in large language models (LLMs) across four levels: Class, Function, Block, and Line. Spanning 18 programming languages, M2G-Eval includes 17K+ training tasks and 1,286 human-annotated, contamination-controlled test instances. We develop M2G-Eval-Coder models by training Qwen3-8B with supervised fine-tuning and Group Relative Policy Optimization. Evaluating 30 models (28 state-of-the-art LLMs plus our two M2G-Eval-Coder variants) reveals three main findings: (1) an apparent difficulty hierarchy, with Line-level tasks easiest and Class-level most challenging; (2) widening performance gaps between full- and partial-granularity languages as task complexity increases; and (3) strong cross-language correlations, suggesting that models learn transferable programming concepts. M2G-Eval enables fine-grained diagnosis of code generation capabilities and highlights persistent challenges in synthesizing complex, long-form code.
Context as a Tool: Context Management for Long-Horizon SWE-Agents
Dec 26, 2025Agents based on large language models have recently shown strong potential on real-world software engineering (SWE) tasks that require long-horizon interaction with repository-scale codebases. However, most existing agents rely on append-only context maintenance or passively triggered compression heuristics, which often lead to context explosion, semantic drift, and degraded reasoning in long-running interactions. We propose CAT, a new context management paradigm that elevates context maintenance to a callable tool integrated into the decision-making process of agents. CAT formalizes a structured context workspace consisting of stable task semantics, condensed long-term memory, and high-fidelity short-term interactions, and enables agents to proactively compress historical trajectories into actionable summaries at appropriate milestones. To support context management for SWE-agents, we propose a trajectory-level supervision framework, CAT-GENERATOR, based on an offline data construction pipeline that injects context-management actions into complete interaction trajectories. Using this framework, we train a context-aware model, SWE-Compressor. Experiments on SWE-Bench-Verified demonstrate that SWE-Compressor reaches a 57.6% solved rate and significantly outperforms ReAct-based agents and static compression baselines, while maintaining stable and scalable long-horizon reasoning under a bounded context budget.
Universal Reasoning Model
Dec 24, 2025Universal transformers (UTs) have been widely used for complex reasoning tasks such as ARC-AGI and Sudoku, yet the specific sources of their performance gains remain underexplored. In this work, we systematically analyze UTs variants and show that improvements on ARC-AGI primarily arise from the recurrent inductive bias and strong nonlinear components of Transformer, rather than from elaborate architectural designs. Motivated by this finding, we propose the Universal Reasoning Model (URM), which enhances the UT with short convolution and truncated backpropagation. Our approach substantially improves reasoning performance, achieving state-of-the-art 53.8% pass@1 on ARC-AGI 1 and 16.0% pass@1 on ARC-AGI 2. Our code is avaliable at https://github.com/UbiquantAI/URM.
Scaling Laws for Code: Every Programming Language Matters
Dec 15, 2025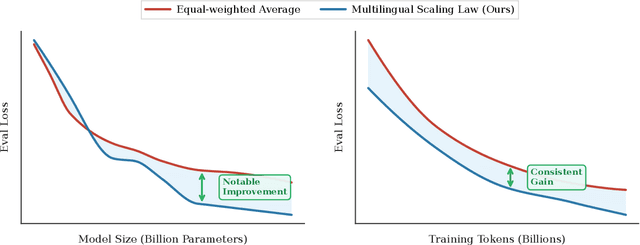

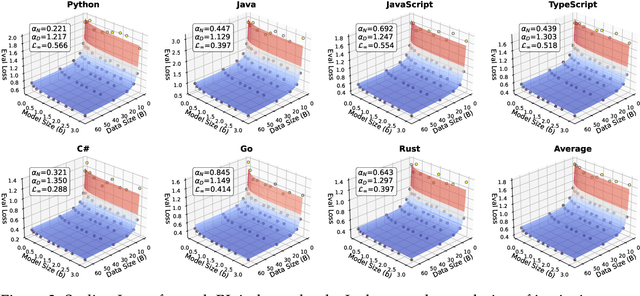

Code large language models (Code LLMs) are powerful but costly to train, with scaling laws predicting performance from model size, data, and compute. However, different programming languages (PLs) have varying impacts during pre-training that significantly affect base model performance, leading to inaccurate performance prediction. Besides, existing works focus on language-agnostic settings, neglecting the inherently multilingual nature of modern software development. Therefore, it is first necessary to investigate the scaling laws of different PLs, and then consider their mutual influences to arrive at the final multilingual scaling law. In this paper, we present the first systematic exploration of scaling laws for multilingual code pre-training, conducting over 1000+ experiments (Equivalent to 336,000+ H800 hours) across multiple PLs, model sizes (0.2B to 14B parameters), and dataset sizes (1T tokens). We establish comprehensive scaling laws for code LLMs across multiple PLs, revealing that interpreted languages (e.g., Python) benefit more from increased model size and data than compiled languages (e.g., Rust). The study demonstrates that multilingual pre-training provides synergistic benefits, particularly between syntactically similar PLs. Further, the pre-training strategy of the parallel pairing (concatenating code snippets with their translations) significantly enhances cross-lingual abilities with favorable scaling properties. Finally, a proportion-dependent multilingual scaling law is proposed to optimally allocate training tokens by prioritizing high-utility PLs (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and reducing allocation to fast-saturating languages (Rust), achieving superior average performance across all PLs compared to uniform distribution under the same compute budget.
Fleming-R1: Toward Expert-Level Medical Reasoning via Reinforcement Learning
Sep 18, 2025While large language models show promise in medical applications, achieving expert-level clinical reasoning remains challenging due to the need for both accurate answers and transparent reasoning processes. To address this challenge, we introduce Fleming-R1, a model designed for verifiable medical reasoning through three complementary innovations. First, our Reasoning-Oriented Data Strategy (RODS) combines curated medical QA datasets with knowledge-graph-guided synthesis to improve coverage of underrepresented diseases, drugs, and multi-hop reasoning chains. Second, we employ Chain-of-Thought (CoT) cold start to distill high-quality reasoning trajectories from teacher models, establishing robust inference priors. Third, we implement a two-stage Reinforcement Learning from Verifiable Rewards (RLVR) framework using Group Relative Policy Optimization, which consolidates core reasoning skills while targeting persistent failure modes through adaptive hard-sample mining. Across diverse medical benchmarks, Fleming-R1 delivers substantial parameter-efficient improvements: the 7B variant surpasses much larger baselines, while the 32B model achieves near-parity with GPT-4o and consistently outperforms strong open-source alternatives. These results demonstrate that structured data design, reasoning-oriented initialization, and verifiable reinforcement learning can advance clinical reasoning beyond simple accuracy optimization. We release Fleming-R1 publicly to promote transparent, reproducible, and auditable progress in medical AI, enabling safer deployment in high-stakes clinical environments.
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
One-shot Entropy Minimization
May 27, 2025We trained 13,440 large language models and found that entropy minimization requires only a single unlabeled data and 10 steps optimization to achieve performance improvements comparable to or even greater than those obtained using thousands of data and carefully designed rewards in rule-based reinforcement learning. This striking result may prompt a rethinking of post-training paradigms for large language models. Our code is avaliable at https://github.com/zitian-gao/one-shot-em.
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Feb 20, 2025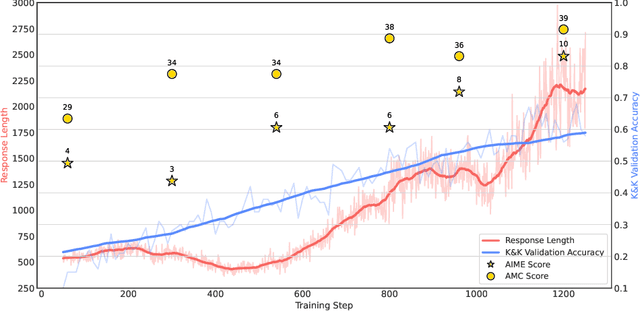



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in large reasoning models. To analyze reasoning dynamics, we use synthetic logic puzzles as training data due to their controllable complexity and straightforward answer verification. We make some key technical contributions that lead to effective and stable RL training: a system prompt that emphasizes the thinking and answering process, a stringent format reward function that penalizes outputs for taking shortcuts, and a straightforward training recipe that achieves stable convergence. Our 7B model develops advanced reasoning skills-such as reflection, verification, and summarization-that are absent from the logic corpus. Remarkably, after training on just 5K logic problems, it demonstrates generalization abilities to the challenging math benchmarks AIME and AMC.