 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopCoder-v2: Only Loop Once for Efficient Test-Time Computation Scaling
Jun 16, 2026Looped Transformers scale latent computation by repeatedly applying shared blocks, but sequential looping increases latency and KV-cache memory with the loop count. Parallel loop Transformers (PLT) alleviate this cost through cross-loop position offsets (CLP) and shared-KV gated sliding-window attention, making loop count a practical design choice. We therefore study PLT loop-count selection through a gain--cost view: an extra loop may refine representations, but CLP also introduces a positional mismatch at each loop boundary. We instantiate this study by training LoopCoder-v2, a family of 7B PLT coders with different loop counts, from scratch on 18T tokens, followed by matched instruction tuning and evaluation. Empirically, the two-loop variant delivers broad gains over the non-looped baseline across code generation, code reasoning, agentic software engineering, and tool-use benchmarks, improving SWE-bench Verified from 43.0 to 64.4 points and Multi-SWE from 14.0 to 31.0 points. In contrast, variants with three or more loops regress, revealing a strongly non-monotonic loop-count effect. Our diagnostics show that loop 2 provides the main productive refinement, while later loops yield diminishing, oscillatory updates and reduced representational diversity. Because the CLP-induced mismatch remains roughly fixed as refinement gains shrink, the offset cost increasingly dominates. This gain--cost trade-off explains PLT's saturation at two loops and provides diagnostics for loop-count selection.
InCoder-32B-Thinking: Industrial Code World Model for Thinking
Apr 03, 2026Industrial software development across chip design, GPU optimization, and embedded systems lacks expert reasoning traces showing how engineers reason about hardware constraints and timing semantics. In this work, we propose InCoder-32B-Thinking, trained on the data from the Error-driven Chain-of-Thought (ECoT) synthesis framework with an industrial code world model (ICWM) to generate reasoning traces. Specifically, ECoT generates reasoning chains by synthesizing the thinking content from multi-turn dialogue with environmental error feedback, explicitly modeling the error-correction process. ICWM is trained on domain-specific execution traces from Verilog simulation, GPU profiling, etc., learns the causal dynamics of how code affects hardware behavior, and enables self-verification by predicting execution outcomes before actual compilation. All synthesized reasoning traces are validated through domain toolchains, creating training data matching the natural reasoning depth distribution of industrial tasks. Evaluation on 14 general (81.3% on LiveCodeBench v5) and 9 industrial benchmarks (84.0% in CAD-Coder and 38.0% on KernelBench) shows InCoder-32B-Thinking achieves top-tier open-source results across all domains.GPU Optimization
Think over Trajectories: Leveraging Video Generation to Reconstruct GPS Trajectories from Cellular Signaling
Mar 27, 2026Mobile devices continuously interact with cellular base stations, generating massive volumes of signaling records that provide broad coverage for understanding human mobility. However, such records offer only coarse location cues (e.g., serving-cell identifiers) and therefore limit their direct use in applications that require high-precision GPS trajectories. This paper studies the Sig2GPS problem: reconstructing GPS trajectories from cellular signaling. Inspired by domain experts often lay the signaling trace on the map and sketch the corresponding GPS route, unlike conventional solutions that rely on complex multi-stage engineering pipelines or regress coordinates, Sig2GPS is reframed as an image-to-video generation task that directly operates in the map-visual domain: signaling traces are rendered on a map, and a video generation model is trained to draw a continuous GPS path. To support this paradigm, a paired signaling-to-trajectory video dataset is constructed to fine-tune an open-source video model, and a trajectory-aware reinforcement learning-based optimization method is introduced to improve generation fidelity via rewards. Experiments on large-scale real-world datasets show substantial improvements over strong engineered and learning-based baselines, while additional results on next GPS prediction indicate scalability and cross-city transferability. Overall, these results suggest that map-visual video generation provides a practical interface for trajectory data mining by enabling direct generation and refinement of continuous paths under map constraints.
IQuest-Coder-V1 Technical Report
Mar 17, 2026In this report, we introduce the IQuest-Coder-V1 series-(7B/14B/40B/40B-Loop), a new family of code large language models (LLMs). Moving beyond static code representations, we propose the code-flow multi-stage training paradigm, which captures the dynamic evolution of software logic through different phases of the pipeline. Our models are developed through the evolutionary pipeline, starting with the initial pre-training consisting of code facts, repository, and completion data. Following that, we implement a specialized mid-training stage that integrates reasoning and agentic trajectories in 32k-context and repository-scale in 128k-context to forge deep logical foundations. The models are then finalized with post-training of specialized coding capabilities, which is bifurcated into two specialized paths: the thinking path (utilizing reasoning-driven RL) and the instruct path (optimized for general assistance). IQuest-Coder-V1 achieves state-of-the-art performance among competitive models across critical dimensions of code intelligence: agentic software engineering, competitive programming, and complex tool use. To address deployment constraints, the IQuest-Coder-V1-Loop variant introduces a recurrent mechanism designed to optimize the trade-off between model capacity and deployment footprint, offering an architecturally enhanced path for efficacy-efficiency trade-off. We believe the release of the IQuest-Coder-V1 series, including the complete white-box chain of checkpoints from pre-training bases to the final thinking and instruction models, will advance research in autonomous code intelligence and real-world agentic systems.
InCoder-32B: Code Foundation Model for Industrial Scenarios
Mar 17, 2026Recent code large language models have achieved remarkable progress on general programming tasks. Nevertheless, their performance degrades significantly in industrial scenarios that require reasoning about hardware semantics, specialized language constructs, and strict resource constraints. To address these challenges, we introduce InCoder-32B (Industrial-Coder-32B), the first 32B-parameter code foundation model unifying code intelligence across chip design, GPU kernel optimization, embedded systems, compiler optimization, and 3D modeling. By adopting an efficient architecture, we train InCoder-32B from scratch with general code pre-training, curated industrial code annealing, mid-training that progressively extends context from 8K to 128K tokens with synthetic industrial reasoning data, and post-training with execution-grounded verification. We conduct extensive evaluation on 14 mainstream general code benchmarks and 9 industrial benchmarks spanning 4 specialized domains. Results show InCoder-32B achieves highly competitive performance on general tasks while establishing strong open-source baselines across industrial domains.
The Sonar Moment: Benchmarking Audio-Language Models in Audio Geo-Localization
Jan 06, 2026Geo-localization aims to infer the geographic origin of a given signal. In computer vision, geo-localization has served as a demanding benchmark for compositional reasoning and is relevant to public safety. In contrast, progress on audio geo-localization has been constrained by the lack of high-quality audio-location pairs. To address this gap, we introduce AGL1K, the first audio geo-localization benchmark for audio language models (ALMs), spanning 72 countries and territories. To extract reliably localizable samples from a crowd-sourced platform, we propose the Audio Localizability metric that quantifies the informativeness of each recording, yielding 1,444 curated audio clips. Evaluations on 16 ALMs show that ALMs have emerged with audio geo-localization capability. We find that closed-source models substantially outperform open-source models, and that linguistic clues often dominate as a scaffold for prediction. We further analyze ALMs' reasoning traces, regional bias, error causes, and the interpretability of the localizability metric. Overall, AGL1K establishes a benchmark for audio geo-localization and may advance ALMs with better geospatial reasoning capability.
CodeSimpleQA: Scaling Factuality in Code Large Language Models
Dec 22, 2025Large language models (LLMs) have made significant strides in code generation, achieving impressive capabilities in synthesizing code snippets from natural language instructions. However, a critical challenge remains in ensuring LLMs generate factually accurate responses about programming concepts, technical implementations, etc. Most previous code-related benchmarks focus on code execution correctness, overlooking the factual accuracy of programming knowledge. To address this gap, we present CodeSimpleQA, a comprehensive bilingual benchmark designed to evaluate the factual accuracy of code LLMs in answering code-related questions, which contains carefully curated question-answer pairs in both English and Chinese, covering diverse programming languages and major computer science domains. Further, we create CodeSimpleQA-Instruct, a large-scale instruction corpus with 66M samples, and develop a post-training framework combining supervised fine-tuning and reinforcement learning. Our comprehensive evaluation of diverse LLMs reveals that even frontier LLMs struggle with code factuality. Our proposed framework demonstrates substantial improvements over the base model, underscoring the critical importance of factuality-aware alignment in developing reliable code LLMs.
Scaling Laws for Code: Every Programming Language Matters
Dec 15, 2025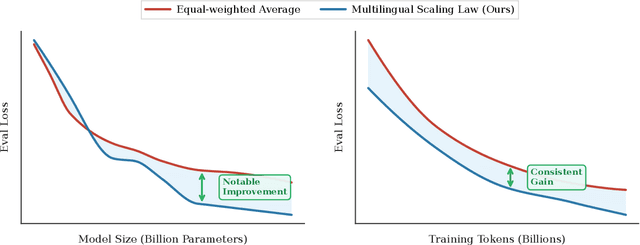

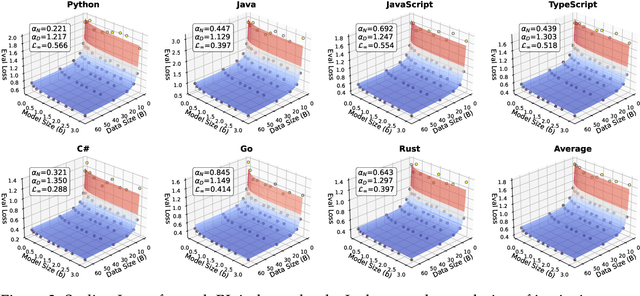

Code large language models (Code LLMs) are powerful but costly to train, with scaling laws predicting performance from model size, data, and compute. However, different programming languages (PLs) have varying impacts during pre-training that significantly affect base model performance, leading to inaccurate performance prediction. Besides, existing works focus on language-agnostic settings, neglecting the inherently multilingual nature of modern software development. Therefore, it is first necessary to investigate the scaling laws of different PLs, and then consider their mutual influences to arrive at the final multilingual scaling law. In this paper, we present the first systematic exploration of scaling laws for multilingual code pre-training, conducting over 1000+ experiments (Equivalent to 336,000+ H800 hours) across multiple PLs, model sizes (0.2B to 14B parameters), and dataset sizes (1T tokens). We establish comprehensive scaling laws for code LLMs across multiple PLs, revealing that interpreted languages (e.g., Python) benefit more from increased model size and data than compiled languages (e.g., Rust). The study demonstrates that multilingual pre-training provides synergistic benefits, particularly between syntactically similar PLs. Further, the pre-training strategy of the parallel pairing (concatenating code snippets with their translations) significantly enhances cross-lingual abilities with favorable scaling properties. Finally, a proportion-dependent multilingual scaling law is proposed to optimally allocate training tokens by prioritizing high-utility PLs (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and reducing allocation to fast-saturating languages (Rust), achieving superior average performance across all PLs compared to uniform distribution under the same compute budget.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
Improving Temporal Link Prediction via Temporal Walk Matrix Projection
Oct 05, 2024



Temporal link prediction, aiming at predicting future interactions among entities based on historical interactions, is crucial for a series of real-world applications. Although previous methods have demonstrated the importance of relative encodings for effective temporal link prediction, computational efficiency remains a major concern in constructing these encodings. Moreover, existing relative encodings are usually constructed based on structural connectivity, where temporal information is seldom considered. To address the aforementioned issues, we first analyze existing relative encodings and unify them as a function of temporal walk matrices. This unification establishes a connection between relative encodings and temporal walk matrices, providing a more principled way for analyzing and designing relative encodings. Based on this analysis, we propose a new temporal graph neural network called TPNet, which introduces a temporal walk matrix that incorporates the time decay effect to simultaneously consider both temporal and structural information. Moreover, TPNet designs a random feature propagation mechanism with theoretical guarantees to implicitly maintain the temporal walk matrices, which improves the computation and storage efficiency. Experimental results on 13 benchmark datasets verify the effectiveness and efficiency of TPNet, where TPNet outperforms other baselines on most datasets and achieves a maximum speedup of $33.3 \times$ compared to the SOTA baseline. Our code can be found at \url{https://github.com/lxd99/TPNet}.