 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Robust Financial Trading with Adversarial Synthetic Market Data
Jan 14, 2026Algorithmic trading relies on machine learning models to make trading decisions. Despite strong in-sample performance, these models often degrade when confronted with evolving real-world market regimes, which can shift dramatically due to macroeconomic changes-e.g., monetary policy updates or unanticipated fluctuations in participant behavior. We identify two challenges that perpetuate this mismatch: (1) insufficient robustness in existing policy against uncertainties in high-level market fluctuations, and (2) the absence of a realistic and diverse simulation environment for training, leading to policy overfitting. To address these issues, we propose a Bayesian Robust Framework that systematically integrates a macro-conditioned generative model with robust policy learning. On the data side, to generate realistic and diverse data, we propose a macro-conditioned GAN-based generator that leverages macroeconomic indicators as primary control variables, synthesizing data with faithful temporal, cross-instrument, and macro correlations. On the policy side, to learn robust policy against market fluctuations, we cast the trading process as a two-player zero-sum Bayesian Markov game, wherein an adversarial agent simulates shifting regimes by perturbing macroeconomic indicators in the macro-conditioned generator, while the trading agent-guided by a quantile belief network-maintains and updates its belief over hidden market states. The trading agent seeks a Robust Perfect Bayesian Equilibrium via Bayesian neural fictitious self-play, stabilizing learning under adversarial market perturbations. Extensive experiments on 9 financial instruments demonstrate that our framework outperforms 9 state-of-the-art baselines. In extreme events like the COVID, our method shows improved profitability and risk management, offering a reliable solution for trading under uncertain and shifting market dynamics.
AFTER: Mitigating the Object Hallucination of LVLM via Adaptive Factual-Guided Activation Editing
Jan 05, 2026Large Vision-Language Models (LVLMs) have achieved substantial progress in cross-modal tasks. However, due to language bias, LVLMs are susceptible to object hallucination, which can be primarily divided into category, attribute, and relation hallucination, significantly impeding the trustworthy AI applications. Editing the internal activations of LVLMs has shown promising effectiveness in mitigating hallucinations with minimal cost. However, previous editing approaches neglect the effective guidance offered by factual textual semantics, thereby struggling to explicitly mitigate language bias. To address these issues, we propose Adaptive Factual-guided Visual-Textual Editing for hallucination mitigation (AFTER), which comprises Factual-Augmented Activation Steering (FAS) and Query-Adaptive Offset Optimization (QAO), to adaptively guides the original biased activations towards factual semantics. Specifically, FAS is proposed to provide factual and general guidance for activation editing, thereby explicitly modeling the precise visual-textual associations. Subsequently, QAO introduces a query-aware offset estimator to establish query-specific editing from the general steering vector, enhancing the diversity and granularity of editing. Extensive experiments on standard hallucination benchmarks across three widely adopted LVLMs validate the efficacy of the proposed AFTER, notably achieving up to a 16.3% reduction of hallucination over baseline on the AMBER benchmark. Our code and data will be released for reproducibility.
Vulnerable Agent Identification in Large-Scale Multi-Agent Reinforcement Learning
Sep 18, 2025Partial agent failure becomes inevitable when systems scale up, making it crucial to identify the subset of agents whose compromise would most severely degrade overall performance. In this paper, we study this Vulnerable Agent Identification (VAI) problem in large-scale multi-agent reinforcement learning (MARL). We frame VAI as a Hierarchical Adversarial Decentralized Mean Field Control (HAD-MFC), where the upper level involves an NP-hard combinatorial task of selecting the most vulnerable agents, and the lower level learns worst-case adversarial policies for these agents using mean-field MARL. The two problems are coupled together, making HAD-MFC difficult to solve. To solve this, we first decouple the hierarchical process by Fenchel-Rockafellar transform, resulting a regularized mean-field Bellman operator for upper level that enables independent learning at each level, thus reducing computational complexity. We then reformulate the upper-level combinatorial problem as a MDP with dense rewards from our regularized mean-field Bellman operator, enabling us to sequentially identify the most vulnerable agents by greedy and RL algorithms. This decomposition provably preserves the optimal solution of the original HAD-MFC. Experiments show our method effectively identifies more vulnerable agents in large-scale MARL and the rule-based system, fooling system into worse failures, and learns a value function that reveals the vulnerability of each agent.
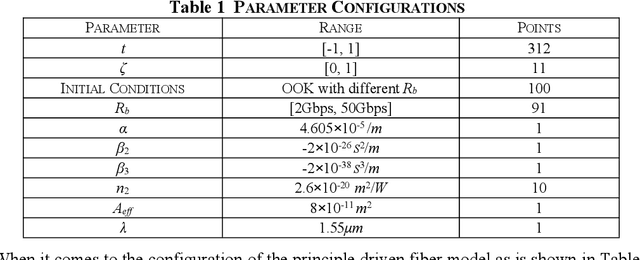
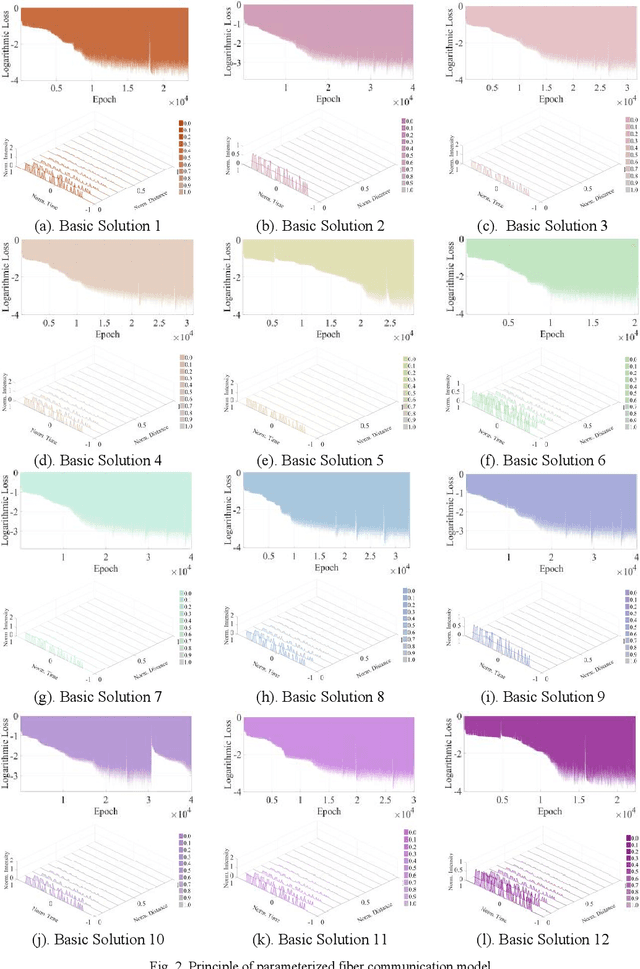
Fiber Transmission Model with Parameterized Inputs based on GPT-PINN Neural Network
Aug 19, 2024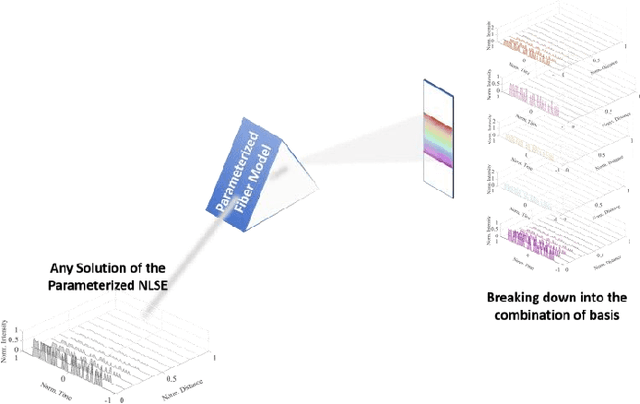

In this manuscript, a novelty principle driven fiber transmission model for short-distance transmission with parameterized inputs is put forward. By taking into the account of the previously proposed principle driven fiber model, the reduced basis expansion method and transforming the parameterized inputs into parameterized coefficients of the Nonlinear Schrodinger Equations, universal solutions with respect to inputs corresponding to different bit rates can all be obtained without the need of re-training the whole model. This model, once adopted, can have prominent advantages in both computation efficiency and physical background. Besides, this model can still be effectively trained without the needs of transmitted signals collected in advance. Tasks of on-off keying signals with bit rates ranging from 2Gbps to 50Gbps are adopted to demonstrate the fidelity of the model.
Principle Driven Parameterized Fiber Model based on GPT-PINN Neural Network
Aug 19, 2024In cater the need of Beyond 5G communications, large numbers of data driven artificial intelligence based fiber models has been put forward as to utilize artificial intelligence's regression ability to predict pulse evolution in fiber transmission at a much faster speed compared with the traditional split step Fourier method. In order to increase the physical interpretabiliy, principle driven fiber models have been proposed which inserts the Nonlinear Schodinger Equation into their loss functions. However, regardless of either principle driven or data driven models, they need to be re-trained the whole model under different transmission conditions. Unfortunately, this situation can be unavoidable when conducting the fiber communication optimization work. If the scale of different transmission conditions is large, then the whole model needs to be retrained large numbers of time with relatively large scale of parameters which may consume higher time costs. Computing efficiency will be dragged down as well. In order to address this problem, we propose the principle driven parameterized fiber model in this manuscript. This model breaks down the predicted NLSE solution with respect to one set of transmission condition into the linear combination of several eigen solutions which were outputted by each pre-trained principle driven fiber model via the reduced basis method. Therefore, the model can greatly alleviate the heavy burden of re-training since only the linear combination coefficients need to be found when changing the transmission condition. Not only strong physical interpretability can the model posses, but also higher computing efficiency can be obtained. Under the demonstration, the model's computational complexity is 0.0113% of split step Fourier method and 1% of the previously proposed principle driven fiber model.
Leveraging Partial Symmetry for Multi-Agent Reinforcement Learning
Dec 30, 2023

Incorporating symmetry as an inductive bias into multi-agent reinforcement learning (MARL) has led to improvements in generalization, data efficiency, and physical consistency. While prior research has succeeded in using perfect symmetry prior, the realm of partial symmetry in the multi-agent domain remains unexplored. To fill in this gap, we introduce the partially symmetric Markov game, a new subclass of the Markov game. We then theoretically show that the performance error introduced by utilizing symmetry in MARL is bounded, implying that the symmetry prior can still be useful in MARL even in partial symmetry situations. Motivated by this insight, we propose the Partial Symmetry Exploitation (PSE) framework that is able to adaptively incorporate symmetry prior in MARL under different symmetry-breaking conditions. Specifically, by adaptively adjusting the exploitation of symmetry, our framework is able to achieve superior sample efficiency and overall performance of MARL algorithms. Extensive experiments are conducted to demonstrate the superior performance of the proposed framework over baselines. Finally, we implement the proposed framework in real-world multi-robot testbed to show its superiority.
MIR2: Towards Provably Robust Multi-Agent Reinforcement Learning by Mutual Information Regularization
Oct 15, 2023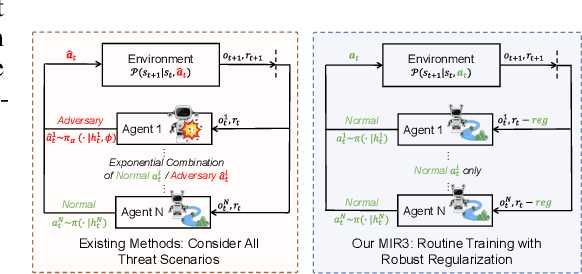

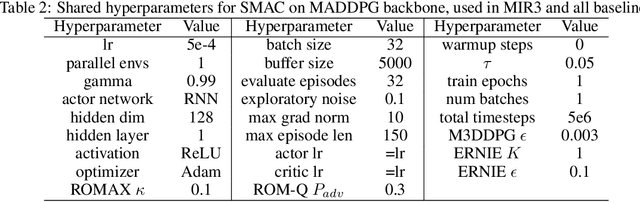

Robust multi-agent reinforcement learning (MARL) necessitates resilience to uncertain or worst-case actions by unknown allies. Existing max-min optimization techniques in robust MARL seek to enhance resilience by training agents against worst-case adversaries, but this becomes intractable as the number of agents grows, leading to exponentially increasing worst-case scenarios. Attempts to simplify this complexity often yield overly pessimistic policies, inadequate robustness across scenarios and high computational demands. Unlike these approaches, humans naturally learn adaptive and resilient behaviors without the necessity of preparing for every conceivable worst-case scenario. Motivated by this, we propose MIR2, which trains policy in routine scenarios and minimize Mutual Information as Robust Regularization. Theoretically, we frame robustness as an inference problem and prove that minimizing mutual information between histories and actions implicitly maximizes a lower bound on robustness under certain assumptions. Further analysis reveals that our proposed approach prevents agents from overreacting to others through an information bottleneck and aligns the policy with a robust action prior. Empirically, our MIR2 displays even greater resilience against worst-case adversaries than max-min optimization in StarCraft II, Multi-agent Mujoco and rendezvous. Our superiority is consistent when deployed in challenging real-world robot swarm control scenario. See code and demo videos in Supplementary Materials.
Towards Benchmarking and Assessing Visual Naturalness of Physical World Adversarial Attacks
May 22, 2023Physical world adversarial attack is a highly practical and threatening attack, which fools real world deep learning systems by generating conspicuous and maliciously crafted real world artifacts. In physical world attacks, evaluating naturalness is highly emphasized since human can easily detect and remove unnatural attacks. However, current studies evaluate naturalness in a case-by-case fashion, which suffers from errors, bias and inconsistencies. In this paper, we take the first step to benchmark and assess visual naturalness of physical world attacks, taking autonomous driving scenario as the first attempt. First, to benchmark attack naturalness, we contribute the first Physical Attack Naturalness (PAN) dataset with human rating and gaze. PAN verifies several insights for the first time: naturalness is (disparately) affected by contextual features (i.e., environmental and semantic variations) and correlates with behavioral feature (i.e., gaze signal). Second, to automatically assess attack naturalness that aligns with human ratings, we further introduce Dual Prior Alignment (DPA) network, which aims to embed human knowledge into model reasoning process. Specifically, DPA imitates human reasoning in naturalness assessment by rating prior alignment and mimics human gaze behavior by attentive prior alignment. We hope our work fosters researches to improve and automatically assess naturalness of physical world attacks. Our code and dataset can be found at https://github.com/zhangsn-19/PAN.
Attacking Cooperative Multi-Agent Reinforcement Learning by Adversarial Minority Influence
Feb 07, 2023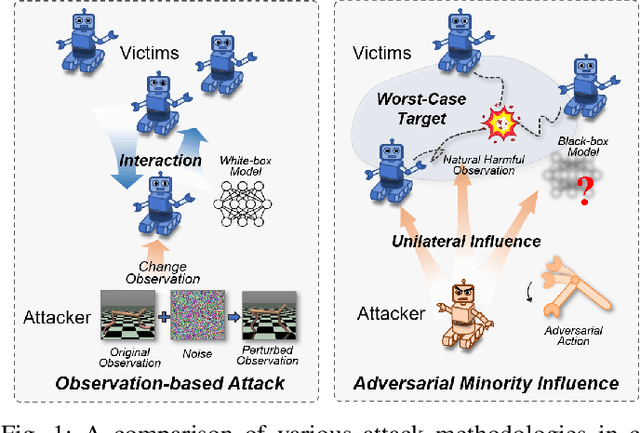


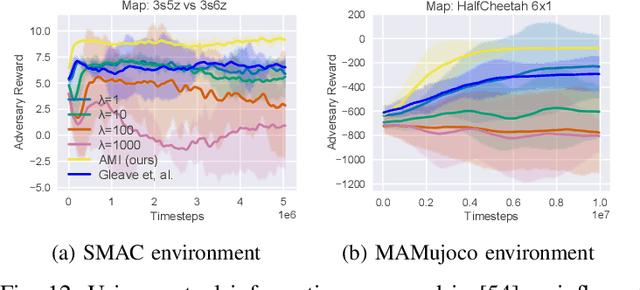
Cooperative multi-agent reinforcement learning (c-MARL) offers a general paradigm for a group of agents to achieve a shared goal by taking individual decisions, yet is found to be vulnerable to adversarial attacks. Though harmful, adversarial attacks also play a critical role in evaluating the robustness and finding blind spots of c-MARL algorithms. However, existing attacks are not sufficiently strong and practical, which is mainly due to the ignorance of complex influence between agents and cooperative nature of victims in c-MARL. In this paper, we propose adversarial minority influence (AMI), the first practical attack against c-MARL by introducing an adversarial agent. AMI addresses the aforementioned problems by unilaterally influencing other cooperative victims to a targeted worst-case cooperation. Technically, to maximally deviate victim policy under complex agent-wise influence, our unilateral attack characterize and maximize the influence from adversary to victims. This is done by adapting a unilateral agent-wise relation metric derived from mutual information, which filters out the detrimental influence from victims to adversary. To fool victims into a jointly worst-case failure, our targeted attack influence victims to a long-term, cooperatively worst case by distracting each victim to a specific target. Such target is learned by a reinforcement learning agent in a trial-and-error process. Extensive experiments in simulation environments, including discrete control (SMAC), continuous control (MAMujoco) and real-world robot swarm control demonstrate the superiority of our AMI approach. Our codes are available in https://anonymous.4open.science/r/AMI.
Hierarchical Perceptual Noise Injection for Social Media Fingerprint Privacy Protection
Aug 23, 2022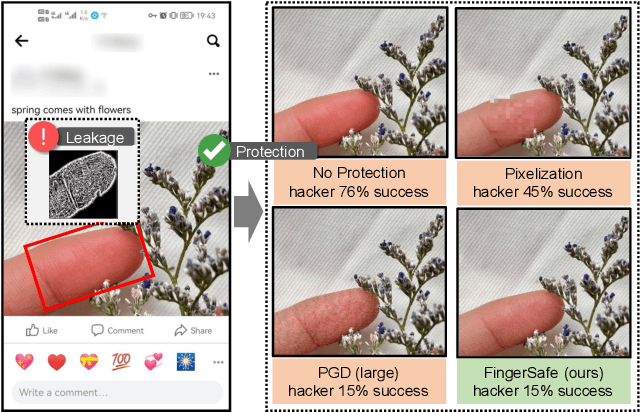
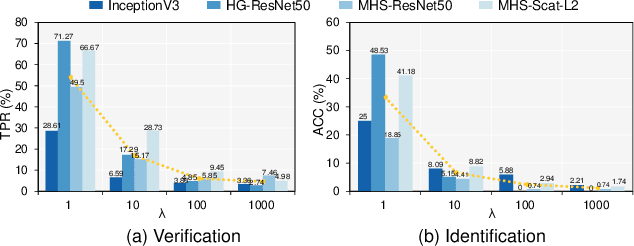
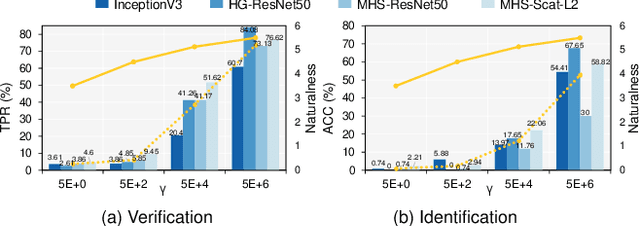
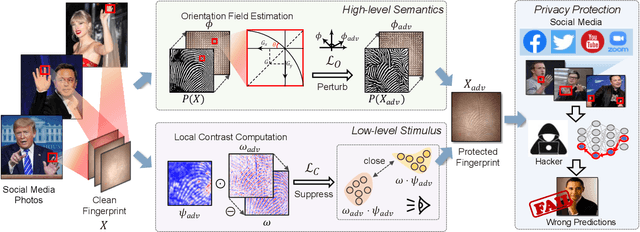
Billions of people are sharing their daily life images on social media every day. However, their biometric information (e.g., fingerprint) could be easily stolen from these images. The threat of fingerprint leakage from social media raises a strong desire for anonymizing shared images while maintaining image qualities, since fingerprints act as a lifelong individual biometric password. To guard the fingerprint leakage, adversarial attack emerges as a solution by adding imperceptible perturbations on images. However, existing works are either weak in black-box transferability or appear unnatural. Motivated by visual perception hierarchy (i.e., high-level perception exploits model-shared semantics that transfer well across models while low-level perception extracts primitive stimulus and will cause high visual sensitivities given suspicious stimulus), we propose FingerSafe, a hierarchical perceptual protective noise injection framework to address the mentioned problems. For black-box transferability, we inject protective noises on fingerprint orientation field to perturb the model-shared high-level semantics (i.e., fingerprint ridges). Considering visual naturalness, we suppress the low-level local contrast stimulus by regularizing the response of Lateral Geniculate Nucleus. Our FingerSafe is the first to provide feasible fingerprint protection in both digital (up to 94.12%) and realistic scenarios (Twitter and Facebook, up to 68.75%). Our code can be found at https://github.com/nlsde-safety-team/FingerSafe.