 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Self-Distillation via Previous Mini-batches for Fine-tuning Small Language Models
Nov 25, 2024



Knowledge distillation (KD) has become a widely adopted approach for compressing large language models (LLMs) to reduce computational costs and memory footprints. However, the availability of complex teacher models is a prerequisite for running most KD pipelines. Thus, the traditional KD procedure can be unachievable or budget-unfriendly, particularly when relying on commercial LLMs like GPT4. In this regard, Self-distillation (SelfD) emerges as an advisable alternative, enabling student models to learn without teachers' guidance. Nonetheless, existing SelfD approaches for LMs often involve architectural modifications, assuming the models are open-source, which may not always be practical. In this work, we introduce a model-agnostic and task-agnostic method named dynamic SelfD from the previous minibatch (DynSDPB), which realizes current iterations' distillation from the last ones' generated logits. Additionally, to address prediction inaccuracies during the early iterations, we dynamically adjust the distillation influence and temperature values to enhance the adaptability of fine-tuning. Furthermore, DynSDPB is a novel fine-tuning policy that facilitates the seamless integration of existing self-correction and self-training techniques for small language models (SLMs) because they all require updating SLMs' parameters. We demonstrate the superior performance of DynSDPB on both encoder-only LMs (e.g., BERT model families) and decoder-only LMs (e.g., LLaMA model families), validating its effectiveness across natural language understanding (NLU) and natural language generation (NLG) benchmarks.
Learning Coarse-Grained Dynamics on Graph
May 15, 2024We consider a Graph Neural Network (GNN) non-Markovian modeling framework to identify coarse-grained dynamical systems on graphs. Our main idea is to systematically determine the GNN architecture by inspecting how the leading term of the Mori-Zwanzig memory term depends on the coarse-grained interaction coefficients that encode the graph topology. Based on this analysis, we found that the appropriate GNN architecture that will account for $K$-hop dynamical interactions has to employ a Message Passing (MP) mechanism with at least $2K$ steps. We also deduce that the memory length required for an accurate closure model decreases as a function of the interaction strength under the assumption that the interaction strength exhibits a power law that decays as a function of the hop distance. Supporting numerical demonstrations on two examples, a heterogeneous Kuramoto oscillator model and a power system, suggest that the proposed GNN architecture can predict the coarse-grained dynamics under fixed and time-varying graph topologies.
Learning Koopman Operators with Control Using Bi-level Optimization
Jul 12, 2023The accurate modeling and control of nonlinear dynamical effects are crucial for numerous robotic systems. The Koopman formalism emerges as a valuable tool for linear control design in nonlinear systems within unknown environments. However, it still remains a challenging task to learn the Koopman operator with control from data, and in particular, the simultaneous identification of the Koopman linear dynamics and the mapping between the state and Koopman spaces. Conventional approaches, based on single-level unconstrained optimization, may lack model robustness, training efficiency, and long-term predictive accuracy. This paper presents a bi-level optimization framework that jointly learns the Koopman embedding mapping and Koopman dynamics with explicit multi-step dynamical constraints, eliminating the need for heuristically-tuned loss terms. Leveraging implicit differentiation, our formulation allows back-propagation in standard learning framework and the use of state-of-the-art optimizers, yielding more stable and robust system performance over various applications compared to conventional methods.
Expanding the Latent Space of StyleGAN for Real Face Editing
Apr 26, 2022
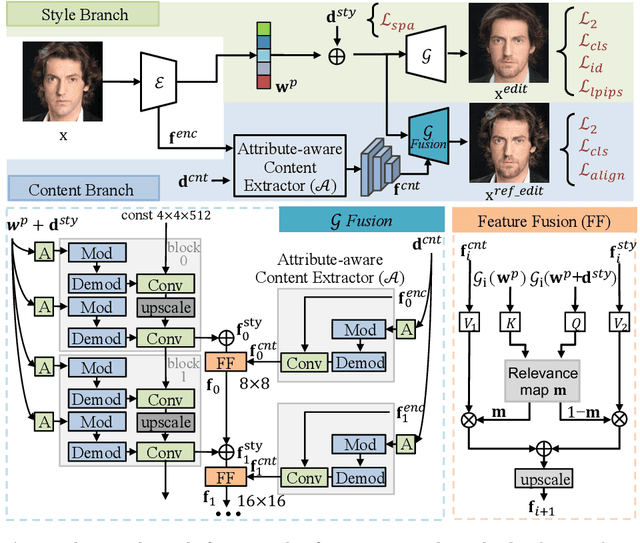

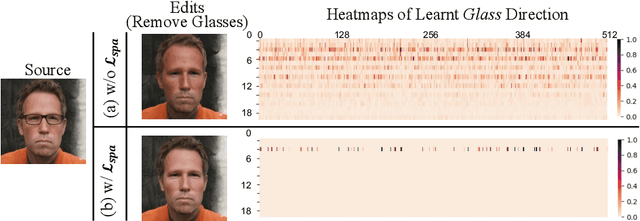
Recently, a surge of face editing techniques have been proposed to employ the pretrained StyleGAN for semantic manipulation. To successfully edit a real image, one must first convert the input image into StyleGAN's latent variables. However, it is still challenging to find latent variables, which have the capacity for preserving the appearance of the input subject (e.g., identity, lighting, hairstyles) as well as enabling meaningful manipulations. In this paper, we present a method to expand the latent space of StyleGAN with additional content features to break down the trade-off between low-distortion and high-editability. Specifically, we proposed a two-branch model, where the style branch first tackles the entanglement issue by the sparse manipulation of latent codes, and the content branch then mitigates the distortion issue by leveraging the content and appearance details from the input image. We confirm the effectiveness of our method using extensive qualitative and quantitative experiments on real face editing and reconstruction tasks.
Generating Topological Structure of Floorplans from Room Attributes
Apr 26, 2022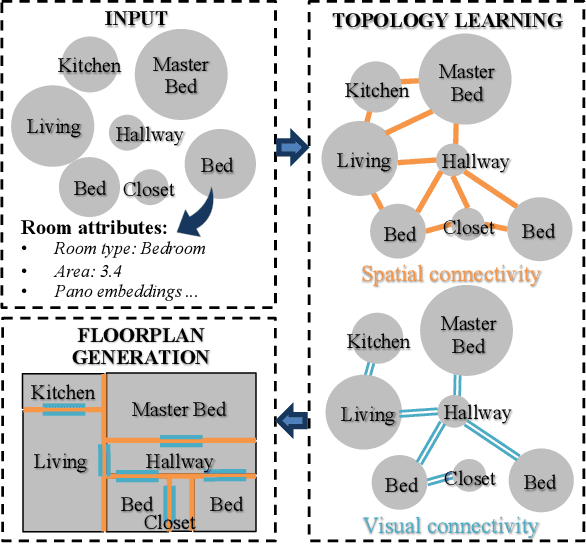
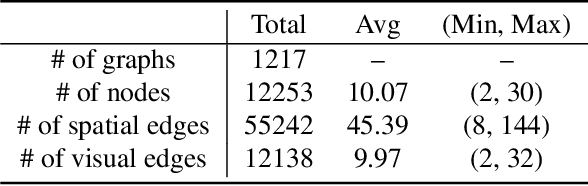
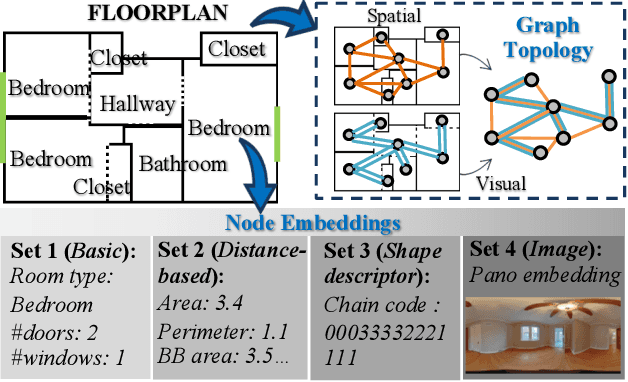
Analysis of indoor spaces requires topological information. In this paper, we propose to extract topological information from room attributes using what we call Iterative and adaptive graph Topology Learning (ITL). ITL progressively predicts multiple relations between rooms; at each iteration, it improves node embeddings, which in turn facilitates generation of a better topological graph structure. This notion of iterative improvement of node embeddings and topological graph structure is in the same spirit as \cite{chen2020iterative}. However, while \cite{chen2020iterative} computes the adjacency matrix based on node similarity, we learn the graph metric using a relational decoder to extract room correlations. Experiments using a new challenging indoor dataset validate our proposed method. Qualitative and quantitative evaluation for layout topology prediction and floorplan generation applications also demonstrate the effectiveness of ITL.
Towards Comprehensive Testing on the Robustness of Cooperative Multi-agent Reinforcement Learning
Apr 17, 2022
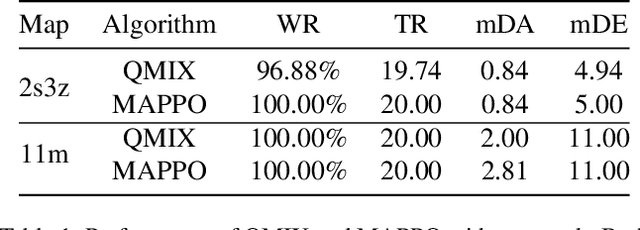

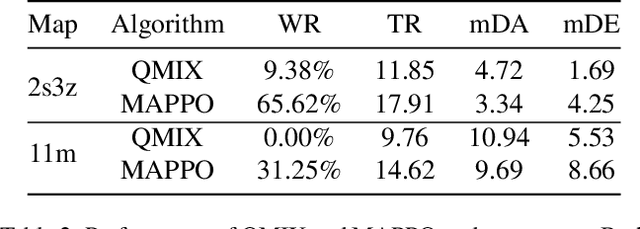
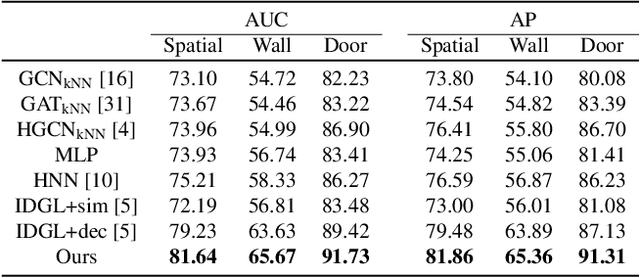
While deep neural networks (DNNs) have strengthened the performance of cooperative multi-agent reinforcement learning (c-MARL), the agent policy can be easily perturbed by adversarial examples. Considering the safety critical applications of c-MARL, such as traffic management, power management and unmanned aerial vehicle control, it is crucial to test the robustness of c-MARL algorithm before it was deployed in reality. Existing adversarial attacks for MARL could be used for testing, but is limited to one robustness aspects (e.g., reward, state, action), while c-MARL model could be attacked from any aspect. To overcome the challenge, we propose MARLSafe, the first robustness testing framework for c-MARL algorithms. First, motivated by Markov Decision Process (MDP), MARLSafe consider the robustness of c-MARL algorithms comprehensively from three aspects, namely state robustness, action robustness and reward robustness. Any c-MARL algorithm must simultaneously satisfy these robustness aspects to be considered secure. Second, due to the scarceness of c-MARL attack, we propose c-MARL attacks as robustness testing algorithms from multiple aspects. Experiments on \textit{SMAC} environment reveals that many state-of-the-art c-MARL algorithms are of low robustness in all aspect, pointing out the urgent need to test and enhance robustness of c-MARL algorithms.