 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhasic Diversity Optimization for Population-Based Reinforcement Learning
Mar 17, 2024



Reviewing the previous work of diversity Rein-forcement Learning,diversity is often obtained via an augmented loss function,which requires a balance between reward and diversity.Generally,diversity optimization algorithms use Multi-armed Bandits algorithms to select the coefficient in the pre-defined space. However, the dynamic distribution of reward signals for MABs or the conflict between quality and diversity limits the performance of these methods. We introduce the Phasic Diversity Optimization (PDO) algorithm, a Population-Based Training framework that separates reward and diversity training into distinct phases instead of optimizing a multi-objective function. In the auxiliary phase, agents with poor performance diversified via determinants will not replace the better agents in the archive. The decoupling of reward and diversity allows us to use an aggressive diversity optimization in the auxiliary phase without performance degradation. Furthermore, we construct a dogfight scenario for aerial agents to demonstrate the practicality of the PDO algorithm. We introduce two implementations of PDO archive and conduct tests in the newly proposed adversarial dogfight and MuJoCo simulations. The results show that our proposed algorithm achieves better performance than baselines.
Towards Comprehensive Testing on the Robustness of Cooperative Multi-agent Reinforcement Learning
Apr 17, 2022
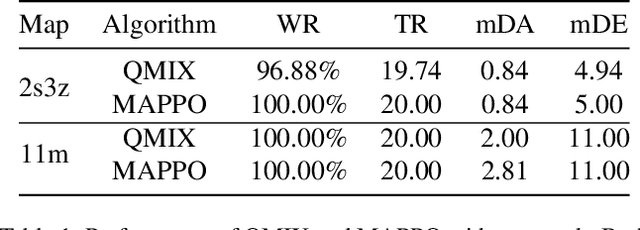

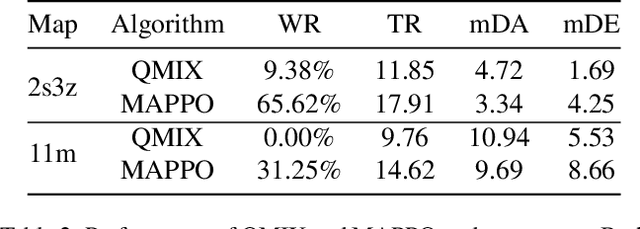
While deep neural networks (DNNs) have strengthened the performance of cooperative multi-agent reinforcement learning (c-MARL), the agent policy can be easily perturbed by adversarial examples. Considering the safety critical applications of c-MARL, such as traffic management, power management and unmanned aerial vehicle control, it is crucial to test the robustness of c-MARL algorithm before it was deployed in reality. Existing adversarial attacks for MARL could be used for testing, but is limited to one robustness aspects (e.g., reward, state, action), while c-MARL model could be attacked from any aspect. To overcome the challenge, we propose MARLSafe, the first robustness testing framework for c-MARL algorithms. First, motivated by Markov Decision Process (MDP), MARLSafe consider the robustness of c-MARL algorithms comprehensively from three aspects, namely state robustness, action robustness and reward robustness. Any c-MARL algorithm must simultaneously satisfy these robustness aspects to be considered secure. Second, due to the scarceness of c-MARL attack, we propose c-MARL attacks as robustness testing algorithms from multiple aspects. Experiments on \textit{SMAC} environment reveals that many state-of-the-art c-MARL algorithms are of low robustness in all aspect, pointing out the urgent need to test and enhance robustness of c-MARL algorithms.