 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhasic Diversity Optimization for Population-Based Reinforcement Learning
Mar 17, 2024



Reviewing the previous work of diversity Rein-forcement Learning,diversity is often obtained via an augmented loss function,which requires a balance between reward and diversity.Generally,diversity optimization algorithms use Multi-armed Bandits algorithms to select the coefficient in the pre-defined space. However, the dynamic distribution of reward signals for MABs or the conflict between quality and diversity limits the performance of these methods. We introduce the Phasic Diversity Optimization (PDO) algorithm, a Population-Based Training framework that separates reward and diversity training into distinct phases instead of optimizing a multi-objective function. In the auxiliary phase, agents with poor performance diversified via determinants will not replace the better agents in the archive. The decoupling of reward and diversity allows us to use an aggressive diversity optimization in the auxiliary phase without performance degradation. Furthermore, we construct a dogfight scenario for aerial agents to demonstrate the practicality of the PDO algorithm. We introduce two implementations of PDO archive and conduct tests in the newly proposed adversarial dogfight and MuJoCo simulations. The results show that our proposed algorithm achieves better performance than baselines.
Multiform Evolution for High-Dimensional Problems with Low Effective Dimensionality
Dec 30, 2023In this paper, we scale evolutionary algorithms to high-dimensional optimization problems that deceptively possess a low effective dimensionality (certain dimensions do not significantly affect the objective function). To this end, an instantiation of the multiform optimization paradigm is presented, where multiple low-dimensional counterparts of a target high-dimensional task are generated via random embeddings. Since the exact relationship between the auxiliary (low-dimensional) tasks and the target is a priori unknown, a multiform evolutionary algorithm is developed for unifying all formulations into a single multi-task setting. The resultant joint optimization enables the target task to efficiently reuse solutions evolved across various low-dimensional searches via cross-form genetic transfers, hence speeding up overall convergence characteristics. To validate the overall efficacy of our proposed algorithmic framework, comprehensive experimental studies are carried out on well-known continuous benchmark functions as well as a set of practical problems in the hyper-parameter tuning of machine learning models and deep learning models in classification tasks and Predator-Prey games, respectively.
OVD-Explorer: Optimism Should Not Be the Sole Pursuit of Exploration in Noisy Environments
Dec 20, 2023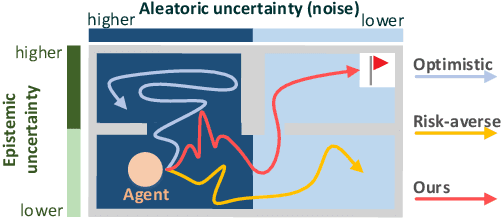



In reinforcement learning, the optimism in the face of uncertainty (OFU) is a mainstream principle for directing exploration towards less explored areas, characterized by higher uncertainty. However, in the presence of environmental stochasticity (noise), purely optimistic exploration may lead to excessive probing of high-noise areas, consequently impeding exploration efficiency. Hence, in exploring noisy environments, while optimism-driven exploration serves as a foundation, prudent attention to alleviating unnecessary over-exploration in high-noise areas becomes beneficial. In this work, we propose Optimistic Value Distribution Explorer (OVD-Explorer) to achieve a noise-aware optimistic exploration for continuous control. OVD-Explorer proposes a new measurement of the policy's exploration ability considering noise in optimistic perspectives, and leverages gradient ascent to drive exploration. Practically, OVD-Explorer can be easily integrated with continuous control RL algorithms. Extensive evaluations on the MuJoCo and GridChaos tasks demonstrate the superiority of OVD-Explorer in achieving noise-aware optimistic exploration.
A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
Oct 10, 2023



Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
A Simple Unified Uncertainty-Guided Framework for Offline-to-Online Reinforcement Learning
Jun 13, 2023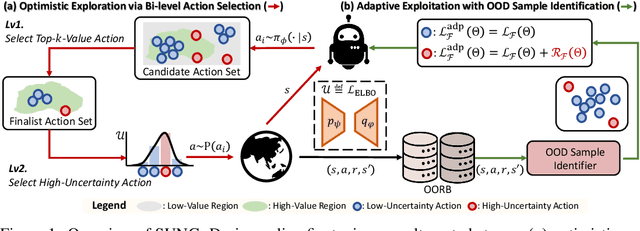
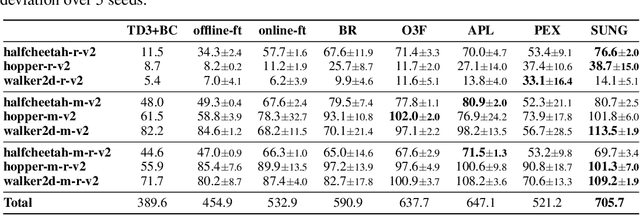
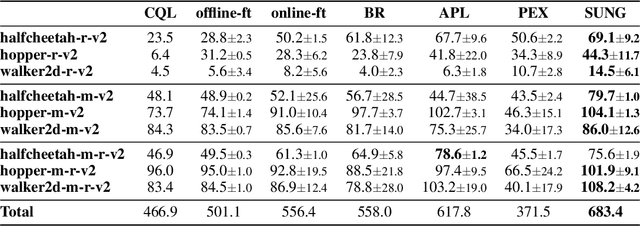
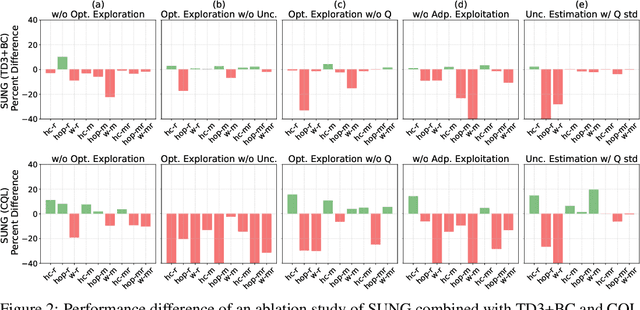
Offline reinforcement learning (RL) provides a promising solution to learning an agent fully relying on a data-driven paradigm. However, constrained by the limited quality of the offline dataset, its performance is often sub-optimal. Therefore, it is desired to further finetune the agent via extra online interactions before deployment. Unfortunately, offline-to-online RL can be challenging due to two main challenges: constrained exploratory behavior and state-action distribution shift. To this end, we propose a Simple Unified uNcertainty-Guided (SUNG) framework, which naturally unifies the solution to both challenges with the tool of uncertainty. Specifically, SUNG quantifies uncertainty via a VAE-based state-action visitation density estimator. To facilitate efficient exploration, SUNG presents a practical optimistic exploration strategy to select informative actions with both high value and high uncertainty. Moreover, SUNG develops an adaptive exploitation method by applying conservative offline RL objectives to high-uncertainty samples and standard online RL objectives to low-uncertainty samples to smoothly bridge offline and online stages. SUNG achieves state-of-the-art online finetuning performance when combined with different offline RL methods, across various environments and datasets in D4RL benchmark.
Sigmoidally Preconditioned Off-policy Learning:a new exploration method for reinforcement learning
May 20, 2022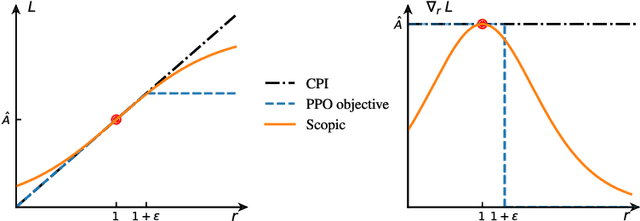
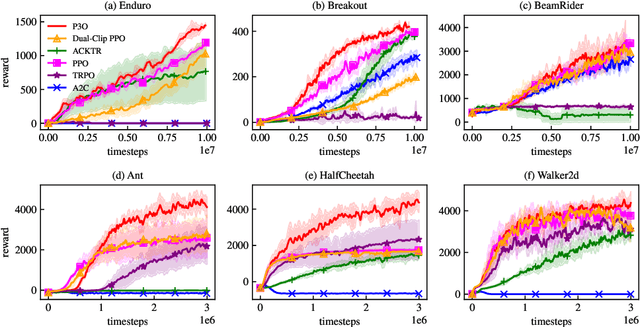

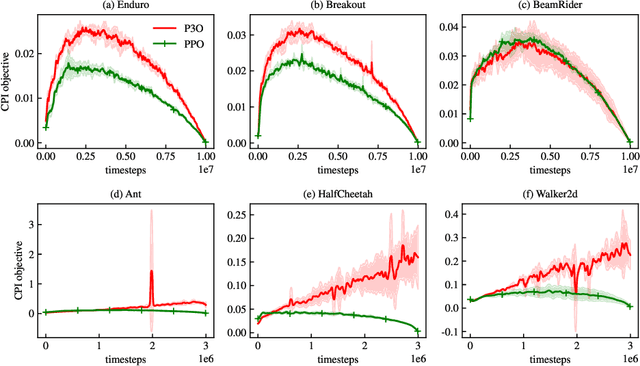
One of the major difficulties of reinforcement learning is learning from {\em off-policy} samples, which are collected by a different policy (behavior policy) from what the algorithm evaluates (the target policy). Off-policy learning needs to correct the distribution of the samples from the behavior policy towards that of the target policy. Unfortunately, important sampling has an inherent high variance issue which leads to poor gradient estimation in policy gradient methods. We focus on an off-policy Actor-Critic architecture, and propose a novel method, called Preconditioned Proximal Policy Optimization (P3O), which can control the high variance of importance sampling by applying a preconditioner to the Conservative Policy Iteration (CPI) objective. {\em This preconditioning uses the sigmoid function in a special way that when there is no policy change, the gradient is maximal and hence policy gradient will drive a big parameter update for an efficient exploration of the parameter space}. This is a novel exploration method that has not been studied before given that existing exploration methods are based on the novelty of states and actions. We compare with several best-performing algorithms on both discrete and continuous tasks and the results confirmed that {\em P3O is more off-policy than PPO} according to the "off-policyness" measured by the DEON metric, and P3O explores in a larger policy space than PPO. Results also show that our P3O maximizes the CPI objective better than PPO during the training process.
ED2: An Environment Dynamics Decomposition Framework for World Model Construction
Dec 06, 2021



Model-based reinforcement learning methods achieve significant sample efficiency in many tasks, but their performance is often limited by the existence of the model error. To reduce the model error, previous works use a single well-designed network to fit the entire environment dynamics, which treats the environment dynamics as a black box. However, these methods lack to consider the environmental decomposed property that the dynamics may contain multiple sub-dynamics, which can be modeled separately, allowing us to construct the world model more accurately. In this paper, we propose the Environment Dynamics Decomposition (ED2), a novel world model construction framework that models the environment in a decomposing manner. ED2 contains two key components: sub-dynamics discovery (SD2) and dynamics decomposition prediction (D2P). SD2 discovers the sub-dynamics in an environment and then D2P constructs the decomposed world model following the sub-dynamics. ED2 can be easily combined with existing MBRL algorithms and empirical results show that ED2 significantly reduces the model error and boosts the performance of the state-of-the-art MBRL algorithms on various tasks.
Coordinated Proximal Policy Optimization
Nov 07, 2021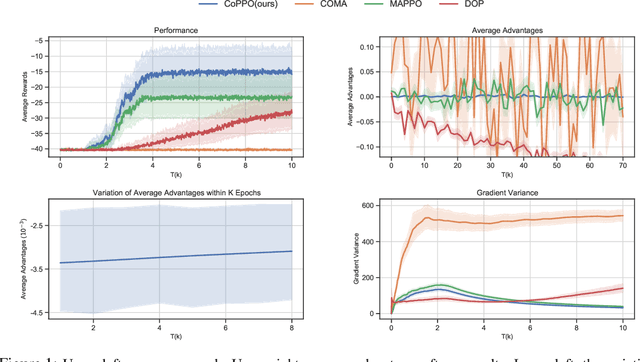
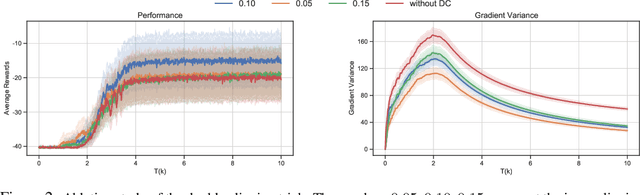
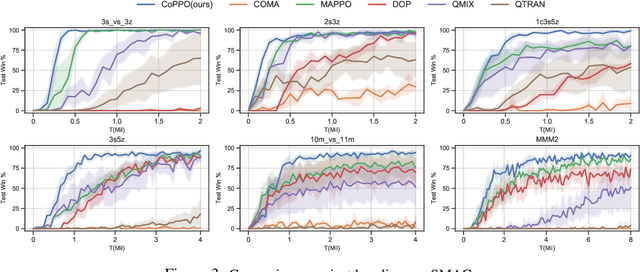
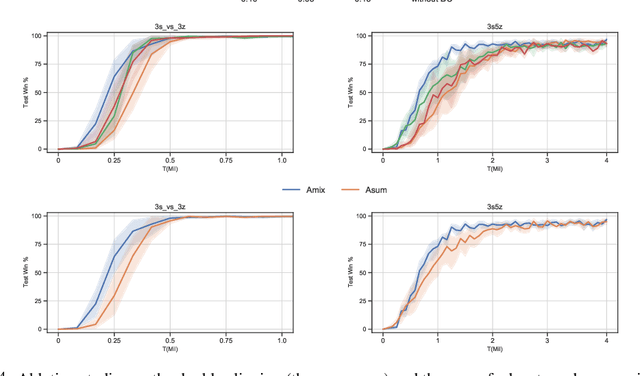
We present Coordinated Proximal Policy Optimization (CoPPO), an algorithm that extends the original Proximal Policy Optimization (PPO) to the multi-agent setting. The key idea lies in the coordinated adaptation of step size during the policy update process among multiple agents. We prove the monotonicity of policy improvement when optimizing a theoretically-grounded joint objective, and derive a simplified optimization objective based on a set of approximations. We then interpret that such an objective in CoPPO can achieve dynamic credit assignment among agents, thereby alleviating the high variance issue during the concurrent update of agent policies. Finally, we demonstrate that CoPPO outperforms several strong baselines and is competitive with the latest multi-agent PPO method (i.e. MAPPO) under typical multi-agent settings, including cooperative matrix games and the StarCraft II micromanagement tasks.
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 23, 2021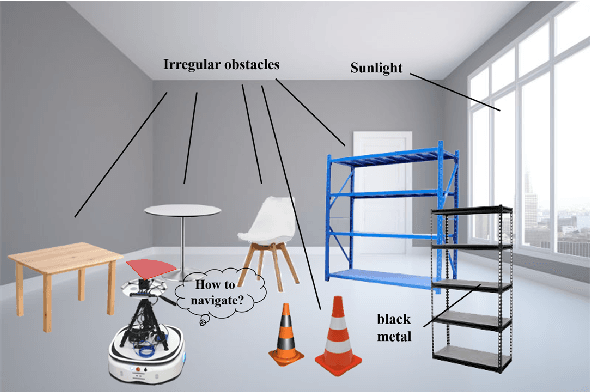
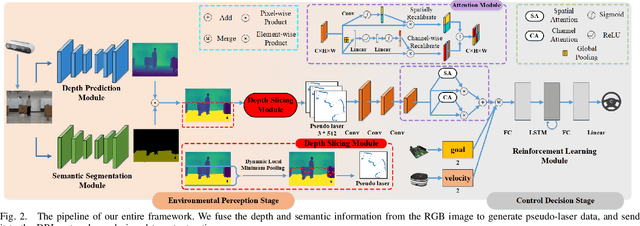

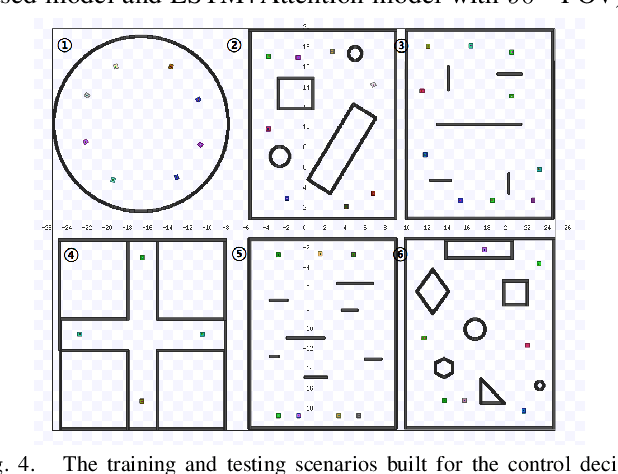
Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.
A Two-Stage Attentive Network for Single Image Super-Resolution
Apr 21, 2021



Recently, deep convolutional neural networks (CNNs) have been widely explored in single image super-resolution (SISR) and contribute remarkable progress. However, most of the existing CNNs-based SISR methods do not adequately explore contextual information in the feature extraction stage and pay little attention to the final high-resolution (HR) image reconstruction step, hence hindering the desired SR performance. To address the above two issues, in this paper, we propose a two-stage attentive network (TSAN) for accurate SISR in a coarse-to-fine manner. Specifically, we design a novel multi-context attentive block (MCAB) to make the network focus on more informative contextual features. Moreover, we present an essential refined attention block (RAB) which could explore useful cues in HR space for reconstructing fine-detailed HR image. Extensive evaluations on four benchmark datasets demonstrate the efficacy of our proposed TSAN in terms of quantitative metrics and visual effects. Code is available at https://github.com/Jee-King/TSAN.