 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Unified Uncertainty-Guided Framework for Offline-to-Online Reinforcement Learning
Paper and Code
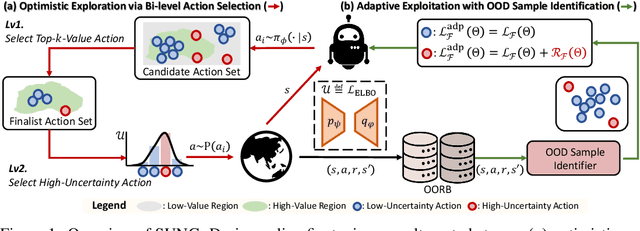
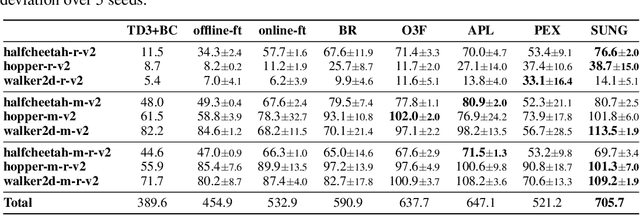
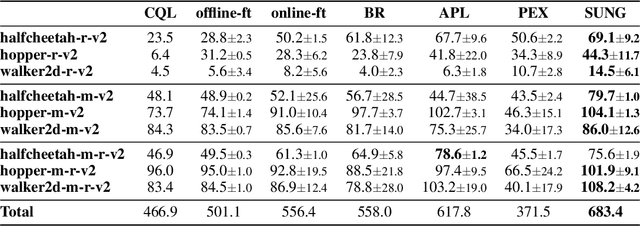
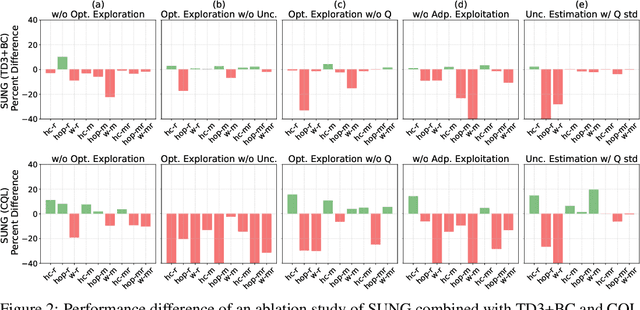
Offline reinforcement learning (RL) provides a promising solution to learning an agent fully relying on a data-driven paradigm. However, constrained by the limited quality of the offline dataset, its performance is often sub-optimal. Therefore, it is desired to further finetune the agent via extra online interactions before deployment. Unfortunately, offline-to-online RL can be challenging due to two main challenges: constrained exploratory behavior and state-action distribution shift. To this end, we propose a Simple Unified uNcertainty-Guided (SUNG) framework, which naturally unifies the solution to both challenges with the tool of uncertainty. Specifically, SUNG quantifies uncertainty via a VAE-based state-action visitation density estimator. To facilitate efficient exploration, SUNG presents a practical optimistic exploration strategy to select informative actions with both high value and high uncertainty. Moreover, SUNG develops an adaptive exploitation method by applying conservative offline RL objectives to high-uncertainty samples and standard online RL objectives to low-uncertainty samples to smoothly bridge offline and online stages. SUNG achieves state-of-the-art online finetuning performance when combined with different offline RL methods, across various environments and datasets in D4RL benchmark.