 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigmoidally Preconditioned Off-policy Learning:a new exploration method for reinforcement learning
May 20, 2022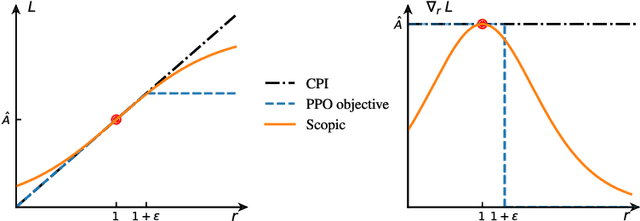
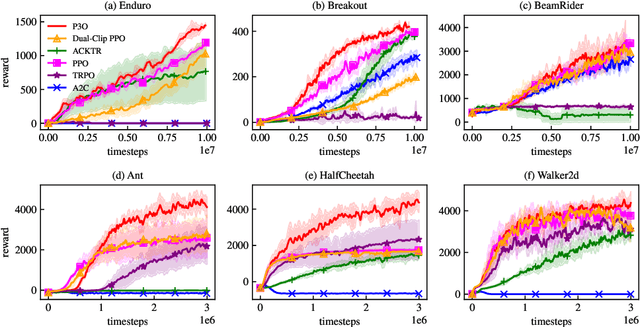

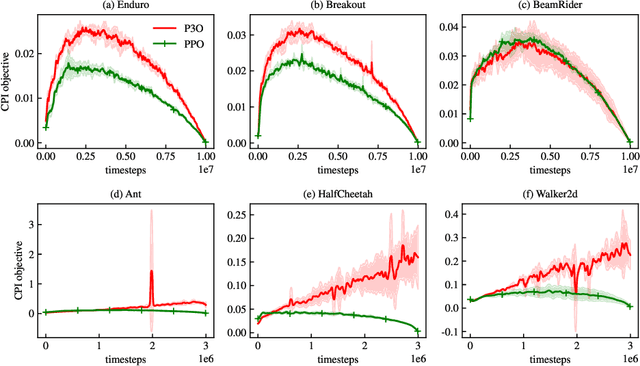
One of the major difficulties of reinforcement learning is learning from {\em off-policy} samples, which are collected by a different policy (behavior policy) from what the algorithm evaluates (the target policy). Off-policy learning needs to correct the distribution of the samples from the behavior policy towards that of the target policy. Unfortunately, important sampling has an inherent high variance issue which leads to poor gradient estimation in policy gradient methods. We focus on an off-policy Actor-Critic architecture, and propose a novel method, called Preconditioned Proximal Policy Optimization (P3O), which can control the high variance of importance sampling by applying a preconditioner to the Conservative Policy Iteration (CPI) objective. {\em This preconditioning uses the sigmoid function in a special way that when there is no policy change, the gradient is maximal and hence policy gradient will drive a big parameter update for an efficient exploration of the parameter space}. This is a novel exploration method that has not been studied before given that existing exploration methods are based on the novelty of states and actions. We compare with several best-performing algorithms on both discrete and continuous tasks and the results confirmed that {\em P3O is more off-policy than PPO} according to the "off-policyness" measured by the DEON metric, and P3O explores in a larger policy space than PPO. Results also show that our P3O maximizes the CPI objective better than PPO during the training process.
Multi-UAV Coverage Planning with Limited Endurance in Disaster Environment
Jan 25, 2022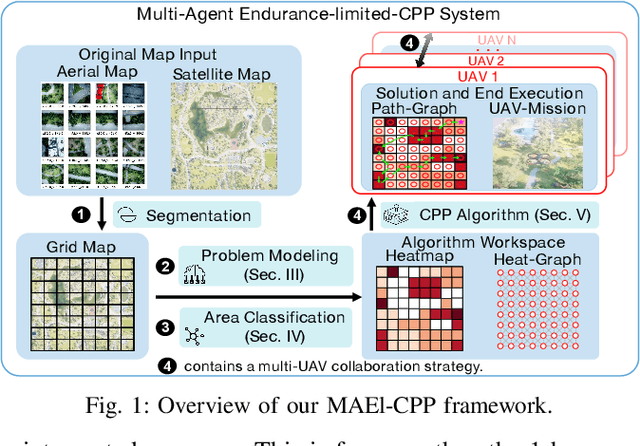
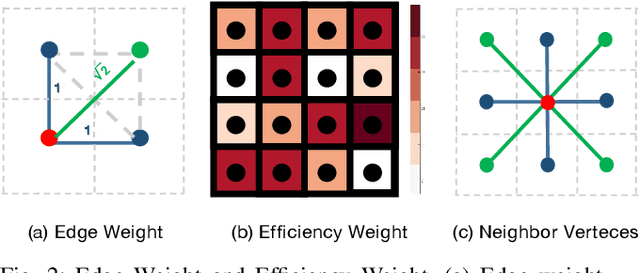
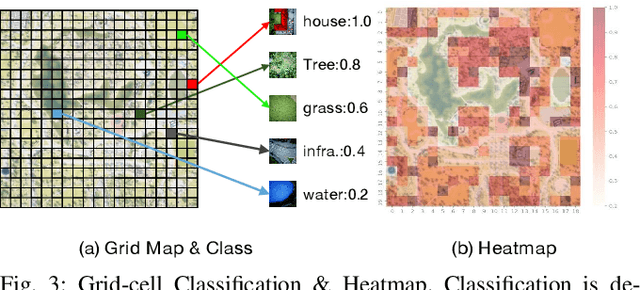

For scenes such as floods and earthquakes, the disaster area is large, and rescue time is tight. Multi-UAV exploration is more efficient than a single UAV. Existing UAV exploration work is modeled as a Coverage Path Planning (CPP) task to achieve full coverage of the area in the presence of obstacles. However, the endurance capability of UAV is limited, and the rescue time is urgent. Thus, even using multiple UAVs cannot achieve complete disaster area coverage in time. Therefore, in this paper we propose a multi-Agent Endurance-limited CPP (MAEl-CPP) problem based on a priori heatmap of the disaster area, which requires the exploration of more valuable areas under limited energy. Furthermore, we propose a path planning algorithm for the MAEl-CPP problem, by ranking the possible disaster areas according to their importance through satellite or remote aerial images and completing path planning according to the importance level. Experimental results show that our proposed algorithm is at least twice as effective as the existing method in terms of search efficiency.
ED2: An Environment Dynamics Decomposition Framework for World Model Construction
Dec 06, 2021



Model-based reinforcement learning methods achieve significant sample efficiency in many tasks, but their performance is often limited by the existence of the model error. To reduce the model error, previous works use a single well-designed network to fit the entire environment dynamics, which treats the environment dynamics as a black box. However, these methods lack to consider the environmental decomposed property that the dynamics may contain multiple sub-dynamics, which can be modeled separately, allowing us to construct the world model more accurately. In this paper, we propose the Environment Dynamics Decomposition (ED2), a novel world model construction framework that models the environment in a decomposing manner. ED2 contains two key components: sub-dynamics discovery (SD2) and dynamics decomposition prediction (D2P). SD2 discovers the sub-dynamics in an environment and then D2P constructs the decomposed world model following the sub-dynamics. ED2 can be easily combined with existing MBRL algorithms and empirical results show that ED2 significantly reduces the model error and boosts the performance of the state-of-the-art MBRL algorithms on various tasks.