 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyColor: An Efficient Heuristic Algorithm for Graph Coloring
Jun 09, 2025
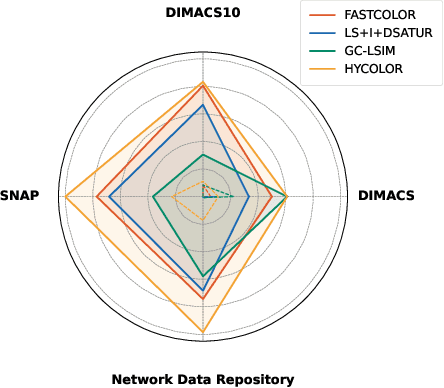

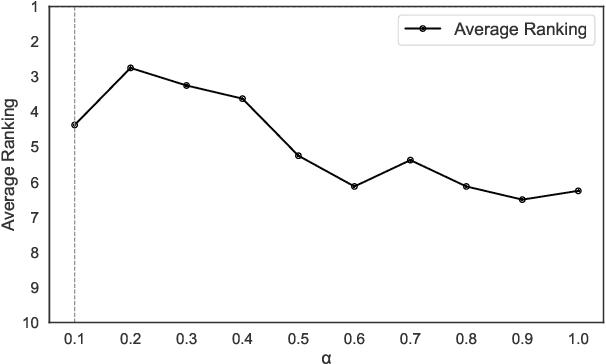
The graph coloring problem (GCP) is a classic combinatorial optimization problem that aims to find the minimum number of colors assigned to vertices of a graph such that no two adjacent vertices receive the same color. GCP has been extensively studied by researchers from various fields, including mathematics, computer science, and biological science. Due to the NP-hard nature, many heuristic algorithms have been proposed to solve GCP. However, existing GCP algorithms focus on either small hard graphs or large-scale sparse graphs (with up to 10^7 vertices). This paper presents an efficient hybrid heuristic algorithm for GCP, named HyColor, which excels in handling large-scale sparse graphs while achieving impressive results on small dense graphs. The efficiency of HyColor comes from the following three aspects: a local decision strategy to improve the lower bound on the chromatic number; a graph-reduction strategy to reduce the working graph; and a k-core and mixed degree-based greedy heuristic for efficiently coloring graphs. HyColor is evaluated against three state-of-the-art GCP algorithms across four benchmarks, comprising three large-scale sparse graph benchmarks and one small dense graph benchmark, totaling 209 instances. The results demonstrate that HyColor consistently outperforms existing heuristic algorithms in both solution accuracy and computational efficiency for the majority of instances. Notably, HyColor achieved the best solutions in 194 instances (over 93%), with 34 of these solutions significantly surpassing those of other algorithms. Furthermore, HyColor successfully determined the chromatic number and achieved optimal coloring in 128 instances.
Phasic Diversity Optimization for Population-Based Reinforcement Learning
Mar 17, 2024



Reviewing the previous work of diversity Rein-forcement Learning,diversity is often obtained via an augmented loss function,which requires a balance between reward and diversity.Generally,diversity optimization algorithms use Multi-armed Bandits algorithms to select the coefficient in the pre-defined space. However, the dynamic distribution of reward signals for MABs or the conflict between quality and diversity limits the performance of these methods. We introduce the Phasic Diversity Optimization (PDO) algorithm, a Population-Based Training framework that separates reward and diversity training into distinct phases instead of optimizing a multi-objective function. In the auxiliary phase, agents with poor performance diversified via determinants will not replace the better agents in the archive. The decoupling of reward and diversity allows us to use an aggressive diversity optimization in the auxiliary phase without performance degradation. Furthermore, we construct a dogfight scenario for aerial agents to demonstrate the practicality of the PDO algorithm. We introduce two implementations of PDO archive and conduct tests in the newly proposed adversarial dogfight and MuJoCo simulations. The results show that our proposed algorithm achieves better performance than baselines.
Exploiting Polarized Material Cues for Robust Car Detection
Jan 05, 2024



Car detection is an important task that serves as a crucial prerequisite for many automated driving functions. The large variations in lighting/weather conditions and vehicle densities of the scenes pose significant challenges to existing car detection algorithms to meet the highly accurate perception demand for safety, due to the unstable/limited color information, which impedes the extraction of meaningful/discriminative features of cars. In this work, we present a novel learning-based car detection method that leverages trichromatic linear polarization as an additional cue to disambiguate such challenging cases. A key observation is that polarization, characteristic of the light wave, can robustly describe intrinsic physical properties of the scene objects in various imaging conditions and is strongly linked to the nature of materials for cars (e.g., metal and glass) and their surrounding environment (e.g., soil and trees), thereby providing reliable and discriminative features for robust car detection in challenging scenes. To exploit polarization cues, we first construct a pixel-aligned RGB-Polarization car detection dataset, which we subsequently employ to train a novel multimodal fusion network. Our car detection network dynamically integrates RGB and polarization features in a request-and-complement manner and can explore the intrinsic material properties of cars across all learning samples. We extensively validate our method and demonstrate that it outperforms state-of-the-art detection methods. Experimental results show that polarization is a powerful cue for car detection.
Event-Enhanced Multi-Modal Spiking Neural Network for Dynamic Obstacle Avoidance
Oct 03, 2023Autonomous obstacle avoidance is of vital importance for an intelligent agent such as a mobile robot to navigate in its environment. Existing state-of-the-art methods train a spiking neural network (SNN) with deep reinforcement learning (DRL) to achieve energy-efficient and fast inference speed in complex/unknown scenes. These methods typically assume that the environment is static while the obstacles in real-world scenes are often dynamic. The movement of obstacles increases the complexity of the environment and poses a great challenge to the existing methods. In this work, we approach robust dynamic obstacle avoidance twofold. First, we introduce the neuromorphic vision sensor (i.e., event camera) to provide motion cues complementary to the traditional Laser depth data for handling dynamic obstacles. Second, we develop an DRL-based event-enhanced multimodal spiking actor network (EEM-SAN) that extracts information from motion events data via unsupervised representation learning and fuses Laser and event camera data with learnable thresholding. Experiments demonstrate that our EEM-SAN outperforms state-of-the-art obstacle avoidance methods by a significant margin, especially for dynamic obstacle avoidance.
Wider and Higher: Intensive Integration and Global Foreground Perception for Image Matting
Oct 13, 2022
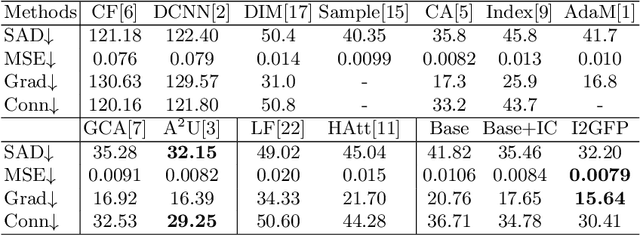
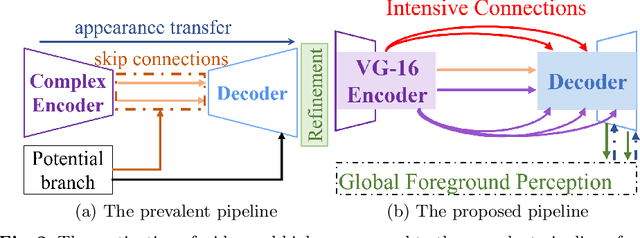
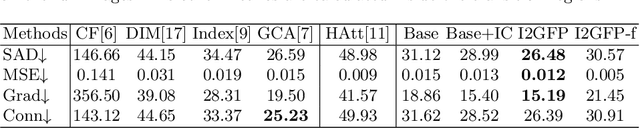
This paper reviews recent deep-learning-based matting research and conceives our wider and higher motivation for image matting. Many approaches achieve alpha mattes with complex encoders to extract robust semantics, then resort to the U-net-like decoder to concatenate or fuse encoder features. However, image matting is essentially a pixel-wise regression, and the ideal situation is to perceive the maximum opacity correspondence from the input image. In this paper, we argue that the high-resolution feature representation, perception and communication are more crucial for matting accuracy. Therefore, we propose an Intensive Integration and Global Foreground Perception network (I2GFP) to integrate wider and higher feature streams. Wider means we combine intensive features in each decoder stage, while higher suggests we retain high-resolution intermediate features and perceive large-scale foreground appearance. Our motivation sacrifices model depth for a significant performance promotion. We perform extensive experiments to prove the proposed I2GFP model, and state-of-the-art results can be achieved on different public datasets.
Hierarchical and Progressive Image Matting
Oct 13, 2022
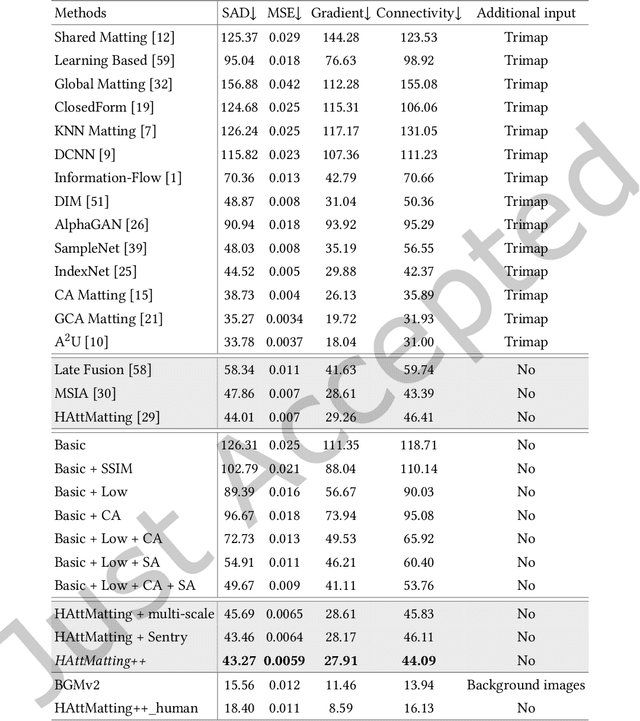
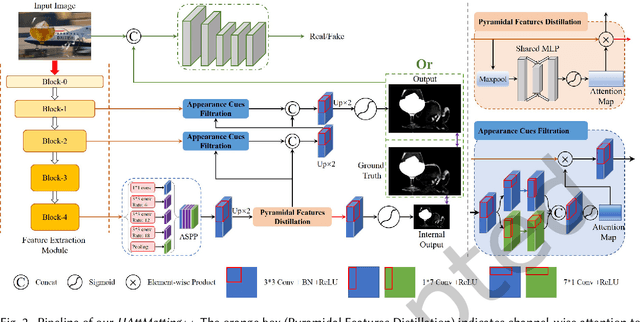
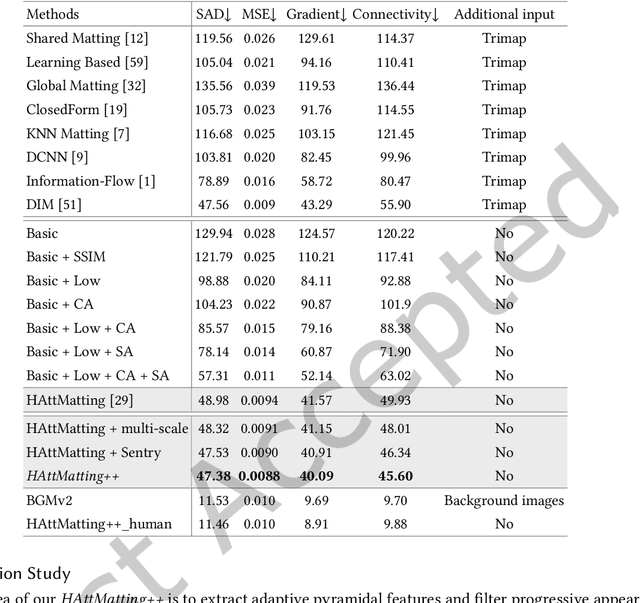
Most matting researches resort to advanced semantics to achieve high-quality alpha mattes, and direct low-level features combination is usually explored to complement alpha details. However, we argue that appearance-agnostic integration can only provide biased foreground details and alpha mattes require different-level feature aggregation for better pixel-wise opacity perception. In this paper, we propose an end-to-end Hierarchical and Progressive Attention Matting Network (HAttMatting++), which can better predict the opacity of the foreground from single RGB images without additional input. Specifically, we utilize channel-wise attention to distill pyramidal features and employ spatial attention at different levels to filter appearance cues. This progressive attention mechanism can estimate alpha mattes from adaptive semantics and semantics-indicated boundaries. We also introduce a hybrid loss function fusing Structural SIMilarity (SSIM), Mean Square Error (MSE), Adversarial loss, and sentry supervision to guide the network to further improve the overall foreground structure. Besides, we construct a large-scale and challenging image matting dataset comprised of 59, 600 training images and 1000 test images (a total of 646 distinct foreground alpha mattes), which can further improve the robustness of our hierarchical and progressive aggregation model. Extensive experiments demonstrate that the proposed HAttMatting++ can capture sophisticated foreground structures and achieve state-of-the-art performance with single RGB images as input.
Progressive Glass Segmentation
Sep 06, 2022



Glass is very common in the real world. Influenced by the uncertainty about the glass region and the varying complex scenes behind the glass, the existence of glass poses severe challenges to many computer vision tasks, making glass segmentation as an important computer vision task. Glass does not have its own visual appearances but only transmit/reflect the appearances of its surroundings, making it fundamentally different from other common objects. To address such a challenging task, existing methods typically explore and combine useful cues from different levels of features in the deep network. As there exists a characteristic gap between level-different features, i.e., deep layer features embed more high-level semantics and are better at locating the target objects while shallow layer features have larger spatial sizes and keep richer and more detailed low-level information, fusing these features naively thus would lead to a sub-optimal solution. In this paper, we approach the effective features fusion towards accurate glass segmentation in two steps. First, we attempt to bridge the characteristic gap between different levels of features by developing a Discriminability Enhancement (DE) module which enables level-specific features to be a more discriminative representation, alleviating the features incompatibility for fusion. Second, we design a Focus-and-Exploration Based Fusion (FEBF) module to richly excavate useful information in the fusion process by highlighting the common and exploring the difference between level-different features.
Camouflaged Object Segmentation with Distraction Mining
Apr 21, 2021
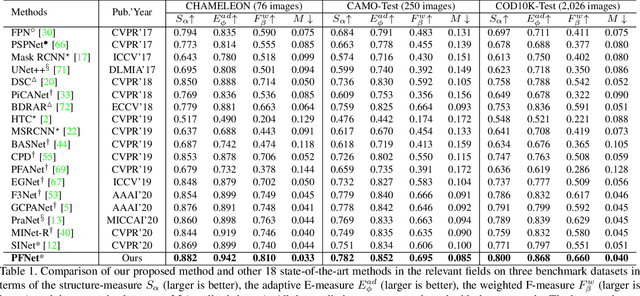
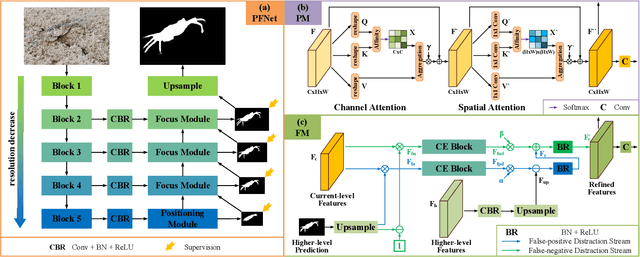
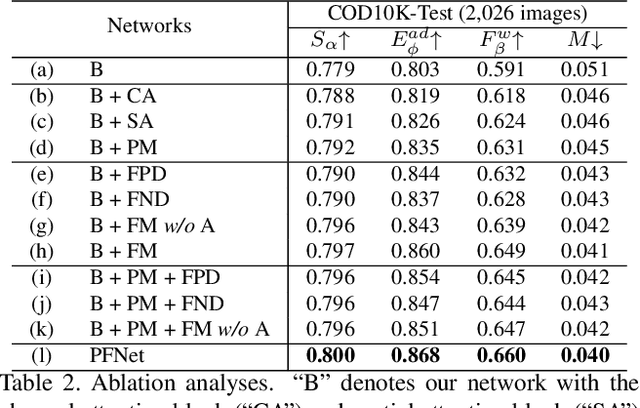
Camouflaged object segmentation (COS) aims to identify objects that are "perfectly" assimilate into their surroundings, which has a wide range of valuable applications. The key challenge of COS is that there exist high intrinsic similarities between the candidate objects and noise background. In this paper, we strive to embrace challenges towards effective and efficient COS. To this end, we develop a bio-inspired framework, termed Positioning and Focus Network (PFNet), which mimics the process of predation in nature. Specifically, our PFNet contains two key modules, i.e., the positioning module (PM) and the focus module (FM). The PM is designed to mimic the detection process in predation for positioning the potential target objects from a global perspective and the FM is then used to perform the identification process in predation for progressively refining the coarse prediction via focusing on the ambiguous regions. Notably, in the FM, we develop a novel distraction mining strategy for distraction discovery and removal, to benefit the performance of estimation. Extensive experiments demonstrate that our PFNet runs in real-time (72 FPS) and significantly outperforms 18 cutting-edge models on three challenging datasets under four standard metrics.