 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-on-Graph: Zero-shot 3D Visual Grounding via Vision-Language Reasoning on Scene Graphs
Dec 10, 20253D visual grounding (3DVG) identifies objects in 3D scenes from language descriptions. Existing zero-shot approaches leverage 2D vision-language models (VLMs) by converting 3D spatial information (SI) into forms amenable to VLM processing, typically as composite inputs such as specified view renderings or video sequences with overlaid object markers. However, this VLM + SI paradigm yields entangled visual representations that compel the VLM to process entire cluttered cues, making it hard to exploit spatial semantic relationships effectively. In this work, we propose a new VLM x SI paradigm that externalizes the 3D SI into a form enabling the VLM to incrementally retrieve only what it needs during reasoning. We instantiate this paradigm with a novel View-on-Graph (VoG) method, which organizes the scene into a multi-modal, multi-layer scene graph and allows the VLM to operate as an active agent that selectively accesses necessary cues as it traverses the scene. This design offers two intrinsic advantages: (i) by structuring 3D context into a spatially and semantically coherent scene graph rather than confounding the VLM with densely entangled visual inputs, it lowers the VLM's reasoning difficulty; and (ii) by actively exploring and reasoning over the scene graph, it naturally produces transparent, step-by-step traces for interpretable 3DVG. Extensive experiments show that VoG achieves state-of-the-art zero-shot performance, establishing structured scene exploration as a promising strategy for advancing zero-shot 3DVG.
InterFeedback: Unveiling Interactive Intelligence of Large Multimodal Models via Human Feedback
Feb 20, 2025



Existing benchmarks do not test Large Multimodal Models (LMMs) on their interactive intelligence with human users which is vital for developing general-purpose AI assistants. We design InterFeedback, an interactive framework, which can be applied to any LMM and dataset to assess this ability autonomously. On top of this, we introduce InterFeedback-Bench which evaluates interactive intelligence using two representative datasets, MMMU-Pro and MathVerse, to test 10 different open-source LMMs. Additionally, we present InterFeedback-Human, a newly collected dataset of 120 cases designed for manually testing interactive performance in leading models such as OpenAI-o1 and Claude-3.5-Sonnet. Our evaluation results show that even state-of-the-art LMM (like OpenAI-o1) can correct their results through human feedback less than 50%. Our findings point to the need for methods that can enhance the LMMs' capability to interpret and benefit from feedback.
FedMLLM: Federated Fine-tuning MLLM on Multimodal Heterogeneity Data
Nov 22, 2024



Multimodal Large Language Models (MLLMs) have made significant advancements, demonstrating powerful capabilities in processing and understanding multimodal data. Fine-tuning MLLMs with Federated Learning (FL) allows for expanding the training data scope by including private data sources, thereby enhancing their practical applicability in privacy-sensitive domains. However, current research remains in the early stage, particularly in addressing the \textbf{multimodal heterogeneities} in real-world applications. In this paper, we introduce a benchmark for evaluating various downstream tasks in the federated fine-tuning of MLLMs within multimodal heterogeneous scenarios, laying the groundwork for the research in the field. Our benchmark encompasses two datasets, five comparison baselines, and four multimodal scenarios, incorporating over ten types of modal heterogeneities. To address the challenges posed by modal heterogeneity, we develop a general FedMLLM framework that integrates four representative FL methods alongside two modality-agnostic strategies. Extensive experimental results show that our proposed FL paradigm improves the performance of MLLMs by broadening the range of training data and mitigating multimodal heterogeneity. Code is available at https://github.com/1xbq1/FedMLLM
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos
Sep 29, 2024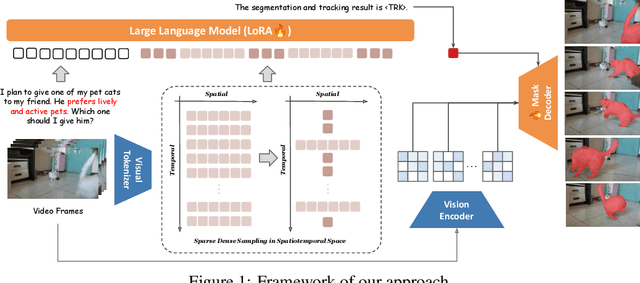
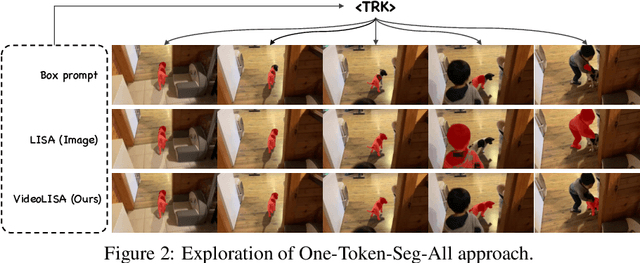


We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions. Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints. Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames. Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA's superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking. While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation. Code and model will be available at: https://github.com/showlab/VideoLISA.
Skip : A Simple Method to Reduce Hallucination in Large Vision-Language Models
Feb 12, 2024Recent advancements in large vision-language models (LVLMs) have demonstrated impressive capability in visual information understanding with human language. Despite these advances, LVLMs still face challenges with multimodal hallucination, such as generating text descriptions of objects that are not present in the visual information. However, the underlying fundamental reasons of multimodal hallucinations remain poorly explored. In this paper, we propose a new perspective, suggesting that the inherent biases in LVLMs might be a key factor in hallucinations. Specifically, we systematically identify a semantic shift bias related to paragraph breaks (\n\n), where the content before and after '\n\n' in the training data frequently exhibit significant semantic changes. This pattern leads the model to infer that the contents following '\n\n' should be obviously different from the preceding contents with less hallucinatory descriptions, thereby increasing the probability of hallucinatory descriptions subsequent to the '\n\n'. We have validated this hypothesis on multiple publicly available LVLMs. Besides, we find that deliberately inserting '\n\n' at the generated description can induce more hallucinations. A simple method is proposed to effectively mitigate the hallucination of LVLMs by skipping the output of '\n'.
Exploiting Polarized Material Cues for Robust Car Detection
Jan 05, 2024



Car detection is an important task that serves as a crucial prerequisite for many automated driving functions. The large variations in lighting/weather conditions and vehicle densities of the scenes pose significant challenges to existing car detection algorithms to meet the highly accurate perception demand for safety, due to the unstable/limited color information, which impedes the extraction of meaningful/discriminative features of cars. In this work, we present a novel learning-based car detection method that leverages trichromatic linear polarization as an additional cue to disambiguate such challenging cases. A key observation is that polarization, characteristic of the light wave, can robustly describe intrinsic physical properties of the scene objects in various imaging conditions and is strongly linked to the nature of materials for cars (e.g., metal and glass) and their surrounding environment (e.g., soil and trees), thereby providing reliable and discriminative features for robust car detection in challenging scenes. To exploit polarization cues, we first construct a pixel-aligned RGB-Polarization car detection dataset, which we subsequently employ to train a novel multimodal fusion network. Our car detection network dynamically integrates RGB and polarization features in a request-and-complement manner and can explore the intrinsic material properties of cars across all learning samples. We extensively validate our method and demonstrate that it outperforms state-of-the-art detection methods. Experimental results show that polarization is a powerful cue for car detection.
Event-Enhanced Multi-Modal Spiking Neural Network for Dynamic Obstacle Avoidance
Oct 03, 2023Autonomous obstacle avoidance is of vital importance for an intelligent agent such as a mobile robot to navigate in its environment. Existing state-of-the-art methods train a spiking neural network (SNN) with deep reinforcement learning (DRL) to achieve energy-efficient and fast inference speed in complex/unknown scenes. These methods typically assume that the environment is static while the obstacles in real-world scenes are often dynamic. The movement of obstacles increases the complexity of the environment and poses a great challenge to the existing methods. In this work, we approach robust dynamic obstacle avoidance twofold. First, we introduce the neuromorphic vision sensor (i.e., event camera) to provide motion cues complementary to the traditional Laser depth data for handling dynamic obstacles. Second, we develop an DRL-based event-enhanced multimodal spiking actor network (EEM-SAN) that extracts information from motion events data via unsupervised representation learning and fuses Laser and event camera data with learnable thresholding. Experiments demonstrate that our EEM-SAN outperforms state-of-the-art obstacle avoidance methods by a significant margin, especially for dynamic obstacle avoidance.
Large-Field Contextual Feature Learning for Glass Detection
Sep 10, 2022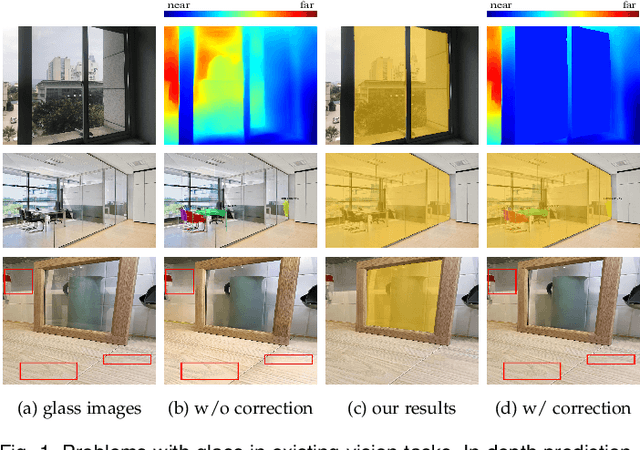
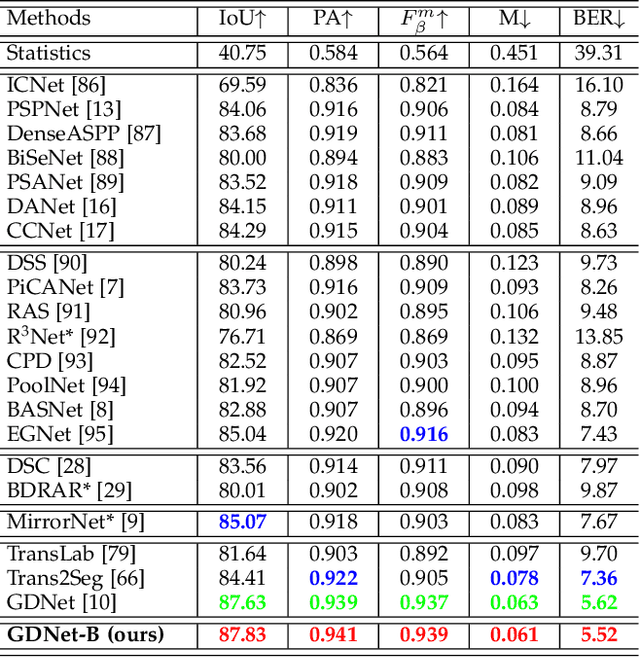

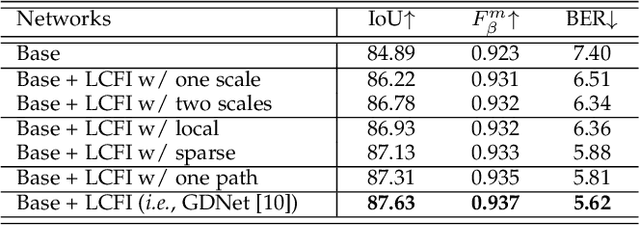
Glass is very common in our daily life. Existing computer vision systems neglect it and thus may have severe consequences, e.g., a robot may crash into a glass wall. However, sensing the presence of glass is not straightforward. The key challenge is that arbitrary objects/scenes can appear behind the glass. In this paper, we propose an important problem of detecting glass surfaces from a single RGB image. To address this problem, we construct the first large-scale glass detection dataset (GDD) and propose a novel glass detection network, called GDNet-B, which explores abundant contextual cues in a large field-of-view via a novel large-field contextual feature integration (LCFI) module and integrates both high-level and low-level boundary features with a boundary feature enhancement (BFE) module. Extensive experiments demonstrate that our GDNet-B achieves satisfying glass detection results on the images within and beyond the GDD testing set. We further validate the effectiveness and generalization capability of our proposed GDNet-B by applying it to other vision tasks, including mirror segmentation and salient object detection. Finally, we show the potential applications of glass detection and discuss possible future research directions.
Progressive Glass Segmentation
Sep 06, 2022



Glass is very common in the real world. Influenced by the uncertainty about the glass region and the varying complex scenes behind the glass, the existence of glass poses severe challenges to many computer vision tasks, making glass segmentation as an important computer vision task. Glass does not have its own visual appearances but only transmit/reflect the appearances of its surroundings, making it fundamentally different from other common objects. To address such a challenging task, existing methods typically explore and combine useful cues from different levels of features in the deep network. As there exists a characteristic gap between level-different features, i.e., deep layer features embed more high-level semantics and are better at locating the target objects while shallow layer features have larger spatial sizes and keep richer and more detailed low-level information, fusing these features naively thus would lead to a sub-optimal solution. In this paper, we approach the effective features fusion towards accurate glass segmentation in two steps. First, we attempt to bridge the characteristic gap between different levels of features by developing a Discriminability Enhancement (DE) module which enables level-specific features to be a more discriminative representation, alleviating the features incompatibility for fusion. Second, we design a Focus-and-Exploration Based Fusion (FEBF) module to richly excavate useful information in the fusion process by highlighting the common and exploring the difference between level-different features.
A Two-Stage Attentive Network for Single Image Super-Resolution
Apr 21, 2021



Recently, deep convolutional neural networks (CNNs) have been widely explored in single image super-resolution (SISR) and contribute remarkable progress. However, most of the existing CNNs-based SISR methods do not adequately explore contextual information in the feature extraction stage and pay little attention to the final high-resolution (HR) image reconstruction step, hence hindering the desired SR performance. To address the above two issues, in this paper, we propose a two-stage attentive network (TSAN) for accurate SISR in a coarse-to-fine manner. Specifically, we design a novel multi-context attentive block (MCAB) to make the network focus on more informative contextual features. Moreover, we present an essential refined attention block (RAB) which could explore useful cues in HR space for reconstructing fine-detailed HR image. Extensive evaluations on four benchmark datasets demonstrate the efficacy of our proposed TSAN in terms of quantitative metrics and visual effects. Code is available at https://github.com/Jee-King/TSAN.