 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-GRPO: Permutation-Invariant Reinforcement Learning for Grounded Visual Reasoning
Jun 29, 2026Vision-Language Models (VLMs) often achieve high performance on benchmarks while remaining "black boxes", yet they remain prone to hallucination or rely on superficial shortcuts. In this work, we propose a framework designed to enhance both performance and interpretability through De-compositional Evidence Grounding. Unlike monolithic inference approaches, our approach forces the model to decompose a global query into a sequence of atomic sub-questions, each requiring an explicit sub-answer and critically a localized evidence bounding box. By grounding intermediate logical steps (e.g. identifying a container, analyzing liquid properties, and assessing environmental context) in specific visual regions, we construct a structured reasoning path that mirrors human-like deduction. This allows the final answer to emerge as a logical consequence of verified visual facts rather than a statistical guess.
ERQA-Plus: A Diagnostic Benchmark for Reasoning in Embodied AI
Jun 17, 2026Generalist embodied agents require more than object recognition: they must reason about spatial relations, actions, procedures, human intentions, environmental constraints, and commonsense consequences from situated visual observations. Yet existing visual and embodied question answering benchmarks often provide limited control over the reasoning dependencies being tested, making it difficult to distinguish grounded embodied reasoning from shortcut-driven visual or linguistic pattern matching. We present ERQA-Plus, a diagnostic benchmark for reasoning in embodied AI. ERQA-Plus contains 1,766 question-answer instances grounded in 711 robot-centric images and organized according to a structured taxonomy spanning perceptual, action-centric, social-interaction, navigation-environmental, and contextual commonsense reasoning. The dataset is constructed using a multi-stage generation and validation pipeline that combines taxonomy-guided question generation, automatic quality judging, iterative revision, and human assessment to improve visual grounding, answer validity, and reasoning quality. We benchmark representative general-purpose vision-language models and embodied models, including LLaVA-NeXT-8B, Prismatic-7B, MiniCPM-V-4.5-8B, Qwen3-VL, RoboRefer-8B, and RoboBrain2.5-8B. Although the strongest model, Qwen3-VL-32B, achieves 83.4% overall accuracy and 61.4 SBERT score, category-level results reveal persistent weaknesses in spatial reasoning, procedural reasoning, event prediction, and intention inference. ERQA-Plus therefore provides a fine-grained evaluation framework for measuring not only whether embodied agents answer correctly, but also which forms of embodied reasoning they can and cannot perform reliably. The dataset is available https://huggingface.co/datasets/huggingdas/erqa-plus and the project page at https://github.com/LUNAProject22/erqa-plus.
Improving Temporal Action Segmentation via Constraint-Aware Decoding
May 11, 2026Temporal action segmentation (TAS) divides untrimmed videos into labeled action segments. While fully supervised methods have advanced the field, challenges such as action variability, ambiguous boundaries, and high annotation costs remain, especially in new or low-resource domains. Grammar-based approaches improve segmentation with structural priors but rely on complex parsing limiting scalability. In this work, we propose a lightweight, constraint-based refinement framework that enhances TAS predictions by integrating statistical structural priors such as transition confidence, action boundary sets, and per-class duration, that can be directly extracted from annotated data. These constraints are integrated into a modified Viterbi decoding algorithm, allowing inference-time refinement without retraining or added model complexity. Our approach improves both fully and semi-supervised TAS models by correcting structural prediction errors while maintaining high efficiency. Code is available at https://github.com/LUNAProject22/CAD
Explicit World Models for Reliable Human-Robot Collaboration
Jan 05, 2026This paper addresses the topic of robustness under sensing noise, ambiguous instructions, and human-robot interaction. We take a radically different tack to the issue of reliable embodied AI: instead of focusing on formal verification methods aimed at achieving model predictability and robustness, we emphasise the dynamic, ambiguous and subjective nature of human-robot interactions that requires embodied AI systems to perceive, interpret, and respond to human intentions in a manner that is consistent, comprehensible and aligned with human expectations. We argue that when embodied agents operate in human environments that are inherently social, multimodal, and fluid, reliability is contextually determined and only has meaning in relation to the goals and expectations of humans involved in the interaction. This calls for a fundamentally different approach to achieving reliable embodied AI that is centred on building and updating an accessible "explicit world model" representing the common ground between human and AI, that is used to align robot behaviours with human expectations.
CoFFT: Chain of Foresight-Focus Thought for Visual Language Models
Sep 26, 2025Despite significant advances in Vision Language Models (VLMs), they remain constrained by the complexity and redundancy of visual input. When images contain large amounts of irrelevant information, VLMs are susceptible to interference, thus generating excessive task-irrelevant reasoning processes or even hallucinations. This limitation stems from their inability to discover and process the required regions during reasoning precisely. To address this limitation, we present the Chain of Foresight-Focus Thought (CoFFT), a novel training-free approach that enhances VLMs' visual reasoning by emulating human visual cognition. Each Foresight-Focus Thought consists of three stages: (1) Diverse Sample Generation: generates diverse reasoning samples to explore potential reasoning paths, where each sample contains several reasoning steps; (2) Dual Foresight Decoding: rigorously evaluates these samples based on both visual focus and reasoning progression, adding the first step of optimal sample to the reasoning process; (3) Visual Focus Adjustment: precisely adjust visual focus toward regions most beneficial for future reasoning, before returning to stage (1) to generate subsequent reasoning samples until reaching the final answer. These stages function iteratively, creating an interdependent cycle where reasoning guides visual focus and visual focus informs subsequent reasoning. Empirical results across multiple benchmarks using Qwen2.5-VL, InternVL-2.5, and Llava-Next demonstrate consistent performance improvements of 3.1-5.8\% with controllable increasing computational overhead.
ChainReaction! Structured Approach with Causal Chains as Intermediate Representations for Improved and Explainable Causal Video Question Answering
Aug 28, 2025Existing Causal-Why Video Question Answering (VideoQA) models often struggle with higher-order reasoning, relying on opaque, monolithic pipelines that entangle video understanding, causal inference, and answer generation. These black-box approaches offer limited interpretability and tend to depend on shallow heuristics. We propose a novel, modular framework that explicitly decouples causal reasoning from answer generation, introducing natural language causal chains as interpretable intermediate representations. Inspired by human cognitive models, these structured cause-effect sequences bridge low-level video content with high-level causal reasoning, enabling transparent and logically coherent inference. Our two-stage architecture comprises a Causal Chain Extractor (CCE) that generates causal chains from video-question pairs, and a Causal Chain-Driven Answerer (CCDA) that produces answers grounded in these chains. To address the lack of annotated reasoning traces, we introduce a scalable method for generating high-quality causal chains from existing datasets using large language models. We also propose CauCo, a new evaluation metric for causality-oriented captioning. Experiments on three large-scale benchmarks demonstrate that our approach not only outperforms state-of-the-art models, but also yields substantial gains in explainability, user trust, and generalization -- positioning the CCE as a reusable causal reasoning engine across diverse domains. Project page: https://paritoshparmar.github.io/chainreaction/
Neuro Symbolic Knowledge Reasoning for Procedural Video Question Answering
Mar 19, 2025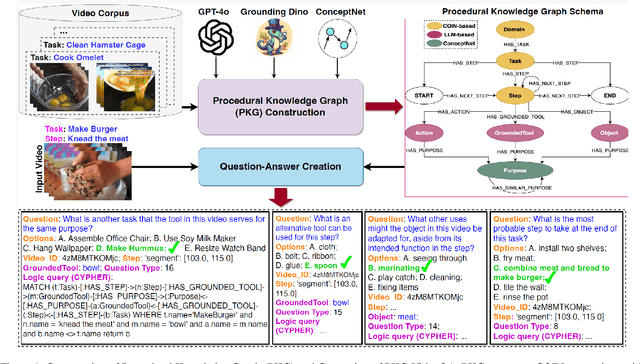
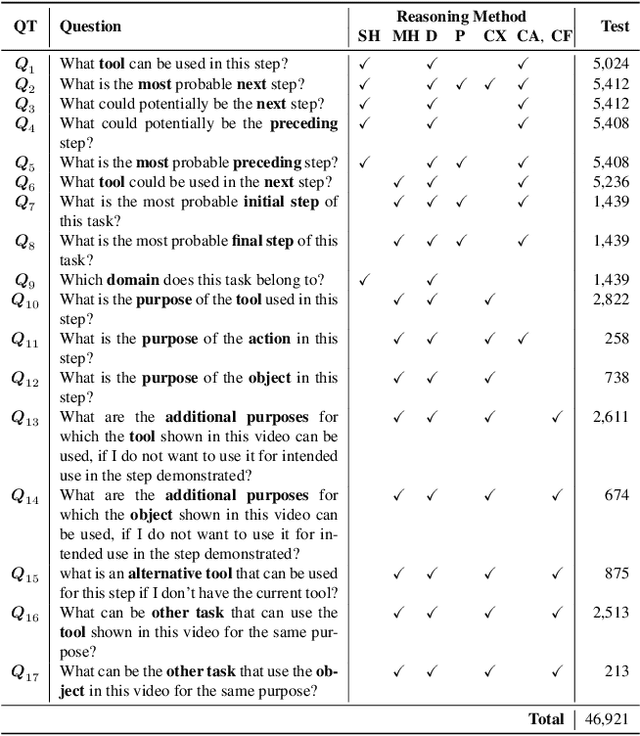

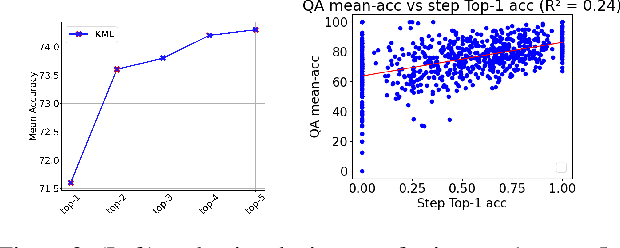
This paper introduces a new video question-answering (VQA) dataset that challenges models to leverage procedural knowledge for complex reasoning. It requires recognizing visual entities, generating hypotheses, and performing contextual, causal, and counterfactual reasoning. To address this, we propose neuro symbolic reasoning module that integrates neural networks and LLM-driven constrained reasoning over variables for interpretable answer generation. Results show that combining LLMs with structured knowledge reasoning with logic enhances procedural reasoning on the STAR benchmark and our dataset. Code and dataset at https://github.com/LUNAProject22/KML soon.
Learning to Generate Long-term Future Narrations Describing Activities of Daily Living
Mar 03, 2025Anticipating future events is crucial for various application domains such as healthcare, smart home technology, and surveillance. Narrative event descriptions provide context-rich information, enhancing a system's future planning and decision-making capabilities. We propose a novel task: $\textit{long-term future narration generation}$, which extends beyond traditional action anticipation by generating detailed narrations of future daily activities. We introduce a visual-language model, ViNa, specifically designed to address this challenging task. ViNa integrates long-term videos and corresponding narrations to generate a sequence of future narrations that predict subsequent events and actions over extended time horizons. ViNa extends existing multimodal models that perform only short-term predictions or describe observed videos by generating long-term future narrations for a broader range of daily activities. We also present a novel downstream application that leverages the generated narrations called future video retrieval to help users improve planning for a task by visualizing the future. We evaluate future narration generation on the largest egocentric dataset Ego4D.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Feb 17, 2025
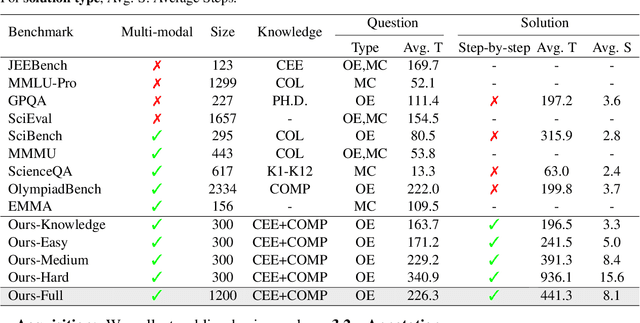


Large language models demonstrate remarkable capabilities across various domains, especially mathematics and logic reasoning. However, current evaluations overlook physics-based reasoning - a complex task requiring physics theorems and constraints. We present PhysReason, a 1,200-problem benchmark comprising knowledge-based (25%) and reasoning-based (75%) problems, where the latter are divided into three difficulty levels (easy, medium, hard). Notably, problems require an average of 8.1 solution steps, with hard requiring 15.6, reflecting the complexity of physics-based reasoning. We propose the Physics Solution Auto Scoring Framework, incorporating efficient answer-level and comprehensive step-level evaluations. Top-performing models like Deepseek-R1, Gemini-2.0-Flash-Thinking, and o3-mini-high achieve less than 60% on answer-level evaluation, with performance dropping from knowledge questions (75.11%) to hard problems (31.95%). Through step-level evaluation, we identified four key bottlenecks: Physics Theorem Application, Physics Process Understanding, Calculation, and Physics Condition Analysis. These findings position PhysReason as a novel and comprehensive benchmark for evaluating physics-based reasoning capabilities in large language models. Our code and data will be published at https:/dxzxy12138.github.io/PhysReason.
FedMLLM: Federated Fine-tuning MLLM on Multimodal Heterogeneity Data
Nov 22, 2024



Multimodal Large Language Models (MLLMs) have made significant advancements, demonstrating powerful capabilities in processing and understanding multimodal data. Fine-tuning MLLMs with Federated Learning (FL) allows for expanding the training data scope by including private data sources, thereby enhancing their practical applicability in privacy-sensitive domains. However, current research remains in the early stage, particularly in addressing the \textbf{multimodal heterogeneities} in real-world applications. In this paper, we introduce a benchmark for evaluating various downstream tasks in the federated fine-tuning of MLLMs within multimodal heterogeneous scenarios, laying the groundwork for the research in the field. Our benchmark encompasses two datasets, five comparison baselines, and four multimodal scenarios, incorporating over ten types of modal heterogeneities. To address the challenges posed by modal heterogeneity, we develop a general FedMLLM framework that integrates four representative FL methods alongside two modality-agnostic strategies. Extensive experimental results show that our proposed FL paradigm improves the performance of MLLMs by broadening the range of training data and mitigating multimodal heterogeneity. Code is available at https://github.com/1xbq1/FedMLLM