 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro Symbolic Knowledge Reasoning for Procedural Video Question Answering
Mar 19, 2025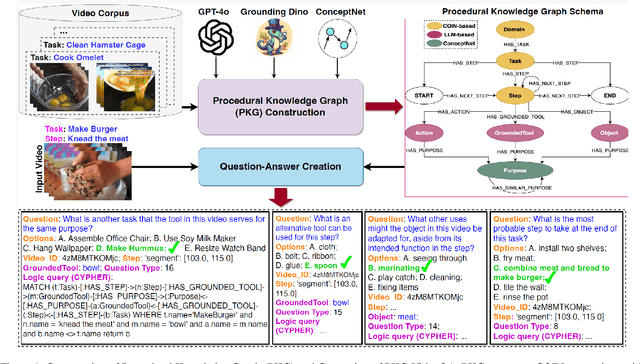
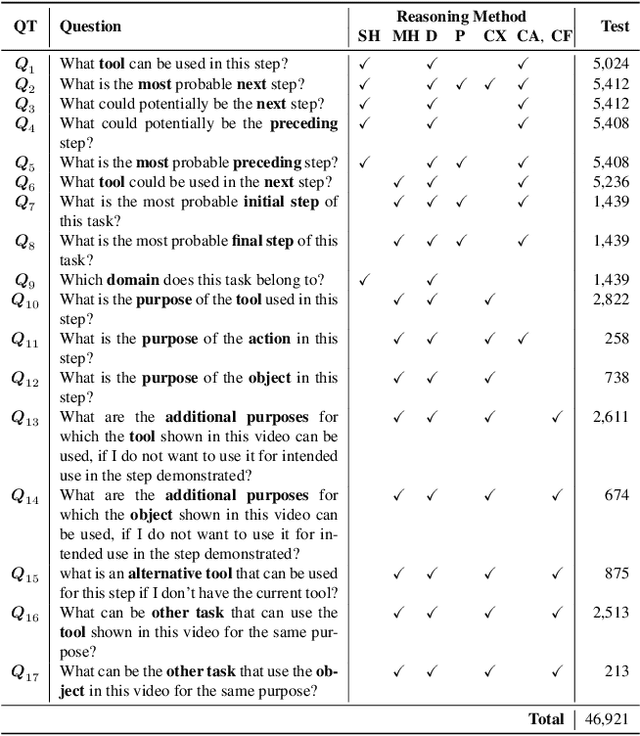

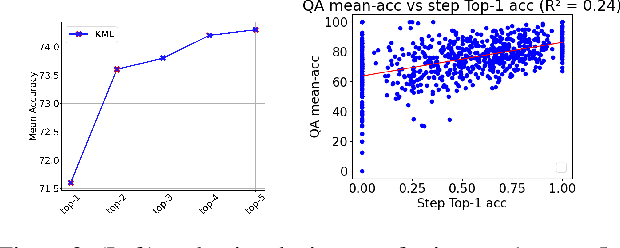
This paper introduces a new video question-answering (VQA) dataset that challenges models to leverage procedural knowledge for complex reasoning. It requires recognizing visual entities, generating hypotheses, and performing contextual, causal, and counterfactual reasoning. To address this, we propose neuro symbolic reasoning module that integrates neural networks and LLM-driven constrained reasoning over variables for interpretable answer generation. Results show that combining LLMs with structured knowledge reasoning with logic enhances procedural reasoning on the STAR benchmark and our dataset. Code and dataset at https://github.com/LUNAProject22/KML soon.
Zero Shot Open-ended Video Inference
Jan 23, 2024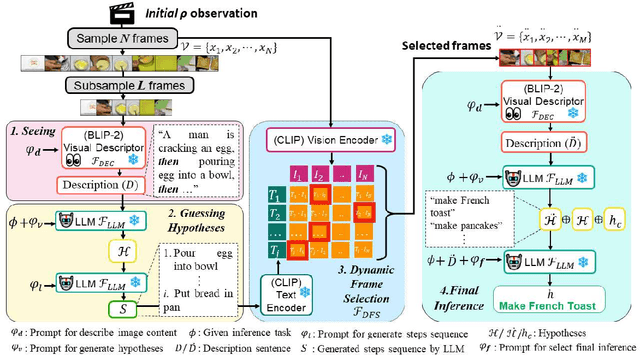
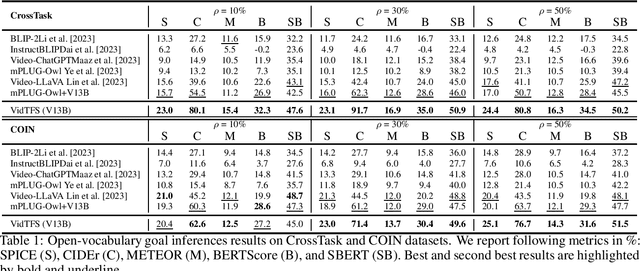

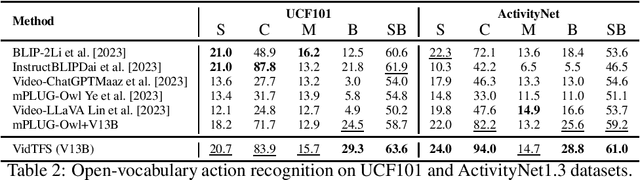
Zero-shot open-ended inference on untrimmed videos poses a significant challenge, especially when no annotated data is utilized to navigate the inference direction. In this work, we aim to address this underexplored domain by introducing an adaptable framework that efficiently combines both the frozen vision-language (VL) model and off-the-shelf large language model (LLM) for conducting zero-shot open-ended inference tasks without requiring any additional training or fine-tuning. Our comprehensive experiments span various video action datasets for goal inference and action recognition tasks. The results demonstrate the framework's superior performance in goal inference compared to conventional vision-language models in open-ended and close-ended scenarios. Notably, the proposed framework exhibits the capability to generalize effectively to action recognition tasks, underscoring its versatility and potential contributions to advancing the video-based zero-shot understanding.