 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsallisPGD: Adaptive Gradient Weighting for Adversarial Attacks on Semantic Segmentation
May 05, 2026Attacking semantic segmentation models is significantly harder than image classification models because an attacker must flip thousands of pixel predictions simultaneously. Standard pixel-wise cross-entropy (CE) is ill-suited to this setting: it tends to overemphasize already-misclassified pixels, which slows optimization and overstates model robustness. To address these issues, we introduce TsallisPGD, an adversarial attack built on the Tsallis cross-entropy, a generalization of CE parameterized by $q$, which adaptively reshapes the gradient landscape by controlling gradient concentration across pixels. By varying $q$, we steer the attack toward pixels at different confidence levels. We first show that no single fixed-$q$ is universally optimal, as its effectiveness depends on the dataset, model architecture, and perturbation budget. Motivated by this, we propose a dynamic $q$-schedule that sweeps $q$ during optimization. Extensive experiments on Cityscapes, Pascal VOC, and ADE20K show that TsallisPGD, using a single validation-selected schedule, achieves the best average attack rank across all evaluated settings and improves over CEPGD, SegPGD, CosPGD, JSPGD, and MaskedPGD in reducing accuracy and mIoU on both standard and robust models.
Zero Shot Open-ended Video Inference
Jan 23, 2024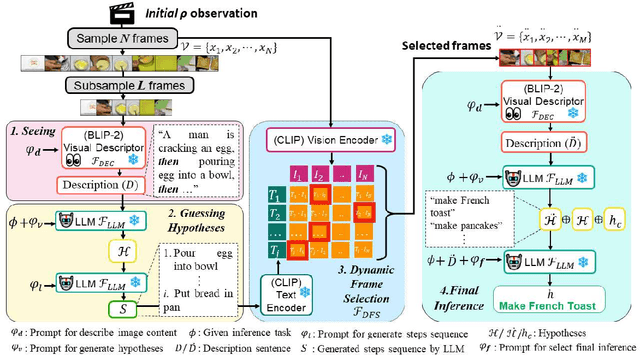
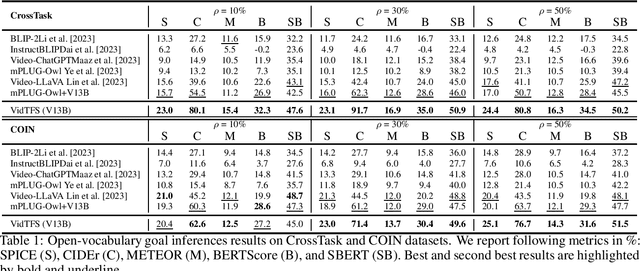

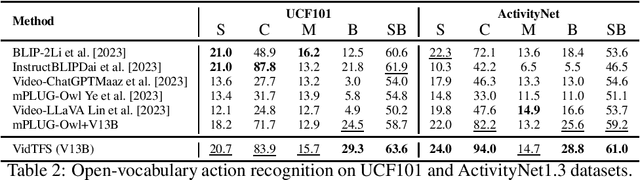
Zero-shot open-ended inference on untrimmed videos poses a significant challenge, especially when no annotated data is utilized to navigate the inference direction. In this work, we aim to address this underexplored domain by introducing an adaptable framework that efficiently combines both the frozen vision-language (VL) model and off-the-shelf large language model (LLM) for conducting zero-shot open-ended inference tasks without requiring any additional training or fine-tuning. Our comprehensive experiments span various video action datasets for goal inference and action recognition tasks. The results demonstrate the framework's superior performance in goal inference compared to conventional vision-language models in open-ended and close-ended scenarios. Notably, the proposed framework exhibits the capability to generalize effectively to action recognition tasks, underscoring its versatility and potential contributions to advancing the video-based zero-shot understanding.
PDPGD: Primal-Dual Proximal Gradient Descent Adversarial Attack
Jun 03, 2021
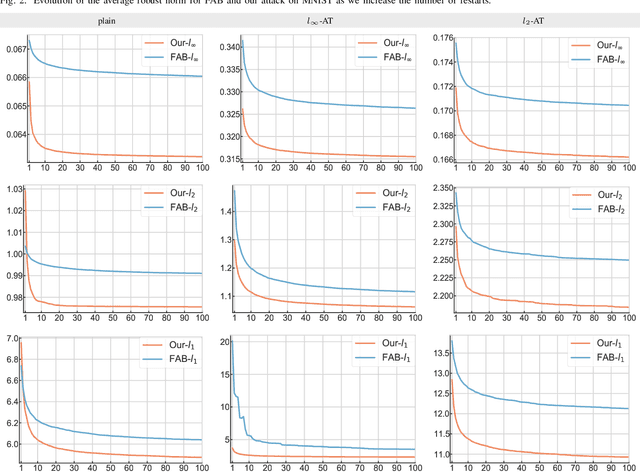
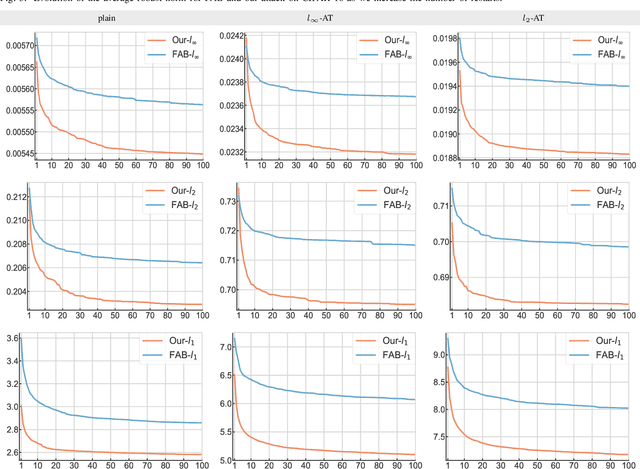
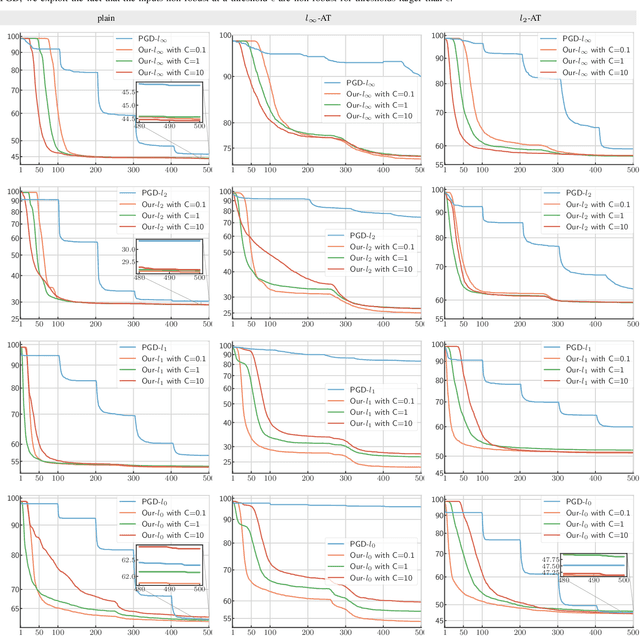
State-of-the-art deep neural networks are sensitive to small input perturbations. Since the discovery of this intriguing vulnerability, many defence methods have been proposed that attempt to improve robustness to adversarial noise. Fast and accurate attacks are required to compare various defence methods. However, evaluating adversarial robustness has proven to be extremely challenging. Existing norm minimisation adversarial attacks require thousands of iterations (e.g. Carlini & Wagner attack), are limited to the specific norms (e.g. Fast Adaptive Boundary), or produce sub-optimal results (e.g. Brendel & Bethge attack). On the other hand, PGD attack, which is fast, general and accurate, ignores the norm minimisation penalty and solves a simpler perturbation-constrained problem. In this work, we introduce a fast, general and accurate adversarial attack that optimises the original non-convex constrained minimisation problem. We interpret optimising the Lagrangian of the adversarial attack optimisation problem as a two-player game: the first player minimises the Lagrangian wrt the adversarial noise; the second player maximises the Lagrangian wrt the regularisation penalty. Our attack algorithm simultaneously optimises primal and dual variables to find the minimal adversarial perturbation. In addition, for non-smooth $l_p$-norm minimisation, such as $l_{\infty}$-, $l_1$-, and $l_0$-norms, we introduce primal-dual proximal gradient descent attack. We show in the experiments that our attack outperforms current state-of-the-art $l_{\infty}$-, $l_2$-, $l_1$-, and $l_0$-attacks on MNIST, CIFAR-10 and Restricted ImageNet datasets against unregularised and adversarially trained models.
Improved Network Robustness with Adversary Critic
Oct 30, 2018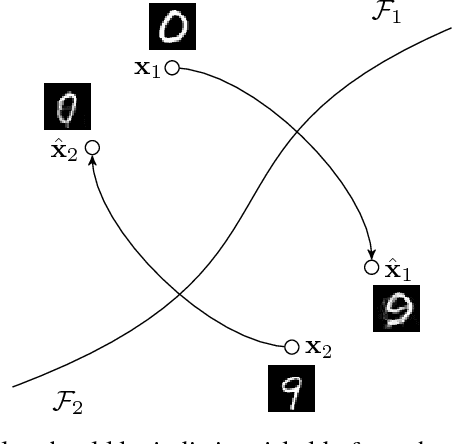
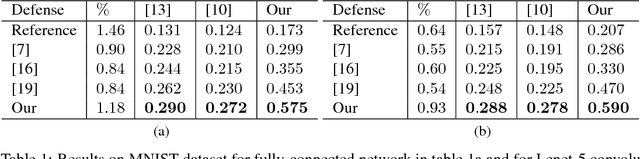


Ideally, what confuses neural network should be confusing to humans. However, recent experiments have shown that small, imperceptible perturbations can change the network prediction. To address this gap in perception, we propose a novel approach for learning robust classifier. Our main idea is: adversarial examples for the robust classifier should be indistinguishable from the regular data of the adversarial target. We formulate a problem of learning robust classifier in the framework of Generative Adversarial Networks (GAN), where the adversarial attack on classifier acts as a generator, and the critic network learns to distinguish between regular and adversarial images. The classifier cost is augmented with the objective that its adversarial examples should confuse the adversary critic. To improve the stability of the adversarial mapping, we introduce adversarial cycle-consistency constraint which ensures that the adversarial mapping of the adversarial examples is close to the original. In the experiments, we show the effectiveness of our defense. Our method surpasses in terms of robustness networks trained with adversarial training. Additionally, we verify in the experiments with human annotators on MTurk that adversarial examples are indeed visually confusing. Codes for the project are available at https://github.com/aam-at/adversary_critic.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.