 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Nov 03, 2020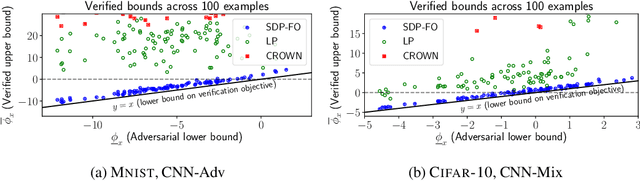
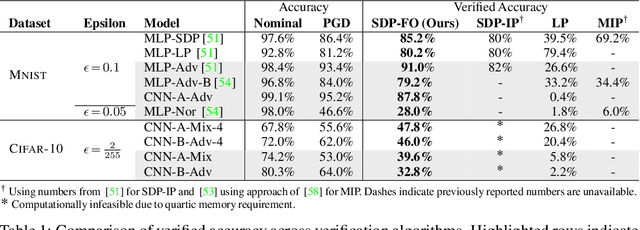
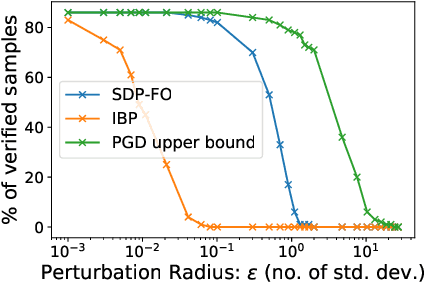

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Creating High Resolution Images with a Latent Adversarial Generator
Mar 04, 2020



Generating realistic images is difficult, and many formulations for this task have been proposed recently. If we restrict the task to that of generating a particular class of images, however, the task becomes more tractable. That is to say, instead of generating an arbitrary image as a sample from the manifold of natural images, we propose to sample images from a particular "subspace" of natural images, directed by a low-resolution image from the same subspace. The problem we address, while close to the formulation of the single-image super-resolution problem, is in fact rather different. Single image super-resolution is the task of predicting the image closest to the ground truth from a relatively low resolution image. We propose to produce samples of high resolution images given extremely small inputs with a new method called Latent Adversarial Generator (LAG). In our generative sampling framework, we only use the input (possibly of very low-resolution) to direct what class of samples the network should produce. As such, the output of our algorithm is not a unique image that relates to the input, but rather a possible se} of related images sampled from the manifold of natural images. Our method learns exclusively in the latent space of the adversary using perceptual loss -- it does not have a pixel loss.
MixMatch: A Holistic Approach to Semi-Supervised Learning
May 06, 2019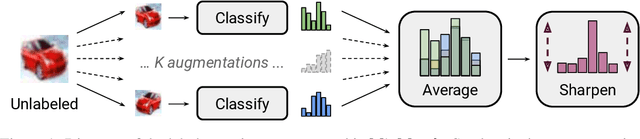

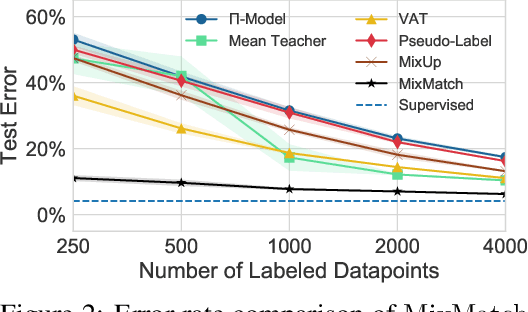

Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm, MixMatch, that works by guessing low-entropy labels for data-augmented unlabeled examples and mixing labeled and unlabeled data using MixUp. We show that MixMatch obtains state-of-the-art results by a large margin across many datasets and labeled data amounts. For example, on CIFAR-10 with 250 labels, we reduce error rate by a factor of 4 (from 38% to 11%) and by a factor of 2 on STL-10. We also demonstrate how MixMatch can help achieve a dramatically better accuracy-privacy trade-off for differential privacy. Finally, we perform an ablation study to tease apart which components of MixMatch are most important for its success.
Imperceptible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition
Mar 22, 2019
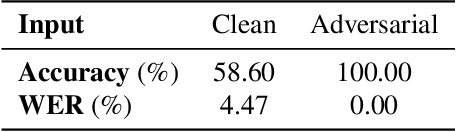
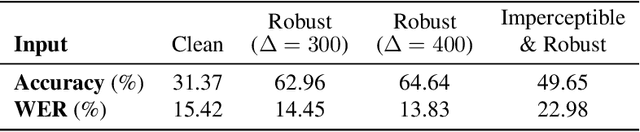
Adversarial examples are inputs to machine learning models designed by an adversary to cause an incorrect output. So far, adversarial examples have been studied most extensively in the image domain. In this domain, adversarial examples can be constructed by imperceptibly modifying images to cause misclassification, and are practical in the physical world. In contrast, current targeted adversarial examples applied to speech recognition systems have neither of these properties: humans can easily identify the adversarial perturbations, and they are not effective when played over-the-air. This paper makes advances on both of these fronts. First, we develop effectively imperceptible audio adversarial examples (verified through a human study) by leveraging the psychoacoustic principle of auditory masking, while retaining 100% targeted success rate on arbitrary full-sentence targets. Next, we make progress towards physical-world over-the-air audio adversarial examples by constructing perturbations which remain effective even after applying realistic simulated environmental distortions.
A Research Agenda: Dynamic Models to Defend Against Correlated Attacks
Mar 14, 2019In this article I describe a research agenda for securing machine learning models against adversarial inputs at test time. This article does not present results but instead shares some of my thoughts about where I think that the field needs to go. Modern machine learning works very well on I.I.D. data: data for which each example is drawn {\em independently} and for which the distribution generating each example is {\em identical}. When these assumptions are relaxed, modern machine learning can perform very poorly. When machine learning is used in contexts where security is a concern, it is desirable to design models that perform well even when the input is designed by a malicious adversary. So far most research in this direction has focused on an adversary who violates the {\em identical} assumption, and imposes some kind of restricted worst-case distribution shift. I argue that machine learning security researchers should also address the problem of relaxing the {\em independence} assumption and that current strategies designed for robustness to distribution shift will not do so. I recommend {\em dynamic models} that change each time they are run as a potential solution path to this problem, and show an example of a simple attack using correlated data that can be mitigated by a simple dynamic defense. This is not intended as a real-world security measure, but as a recommendation to explore this research direction and develop more realistic defenses.
On Evaluating Adversarial Robustness
Feb 20, 2019Correctly evaluating defenses against adversarial examples has proven to be extremely difficult. Despite the significant amount of recent work attempting to design defenses that withstand adaptive attacks, few have succeeded; most papers that propose defenses are quickly shown to be incorrect. We believe a large contributing factor is the difficulty of performing security evaluations. In this paper, we discuss the methodological foundations, review commonly accepted best practices, and suggest new methods for evaluating defenses to adversarial examples. We hope that both researchers developing defenses as well as readers and reviewers who wish to understand the completeness of an evaluation consider our advice in order to avoid common pitfalls.
New CleverHans Feature: Better Adversarial Robustness Evaluations with Attack Bundling
Nov 08, 2018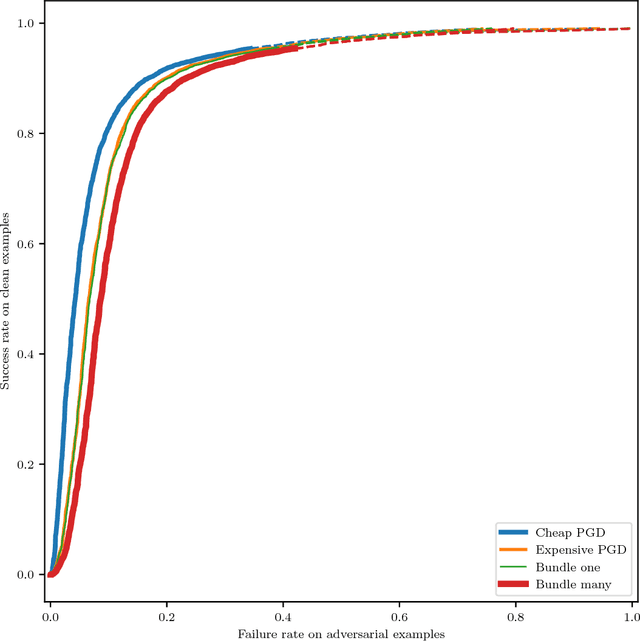

This technical report describes a new feature of the CleverHans library called "attack bundling". Many papers about adversarial examples present lists of error rates corresponding to different attack algorithms. A common approach is to take the maximum across this list and compare defenses against that error rate. We argue that a better approach is to use attack bundling: the max should be taken across many examples at the level of individual examples, then the error rate should be calculated by averaging after this maximization operation. Reporting the bundled attacker error rate provides a lower bound on the true worst-case error rate. The traditional approach of reporting the maximum error rate across attacks can underestimate the true worst-case error rate by an amount approaching 100\% as the number of attacks approaches infinity. Attack bundling can be used with different prioritization schemes to optimize quantities such as error rate on adversarial examples, perturbation size needed to cause misclassification, or failure rate when using a specific confidence threshold.
Sanity Checks for Saliency Maps
Oct 28, 2018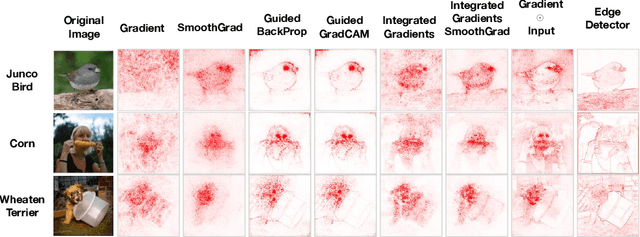
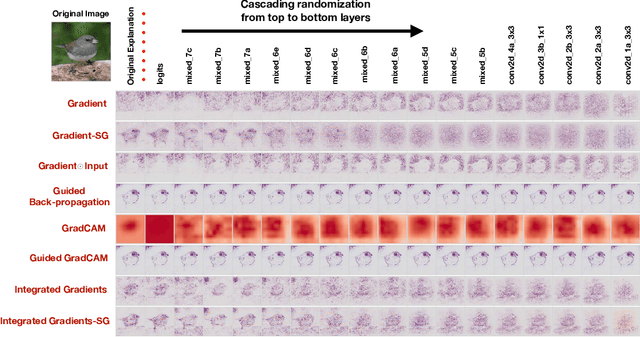
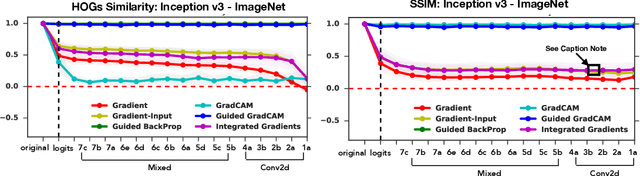
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.
Discriminator Rejection Sampling
Oct 18, 2018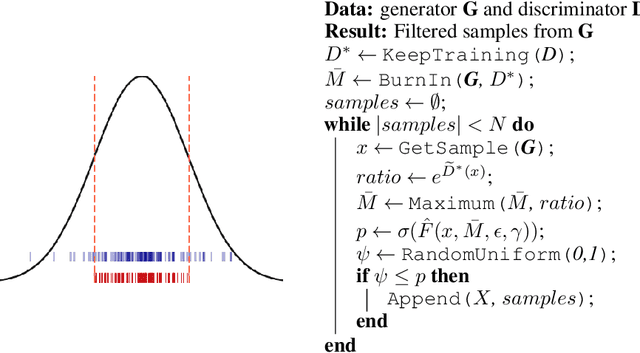

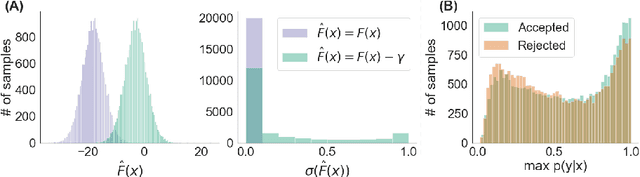

We propose a rejection sampling scheme using the discriminator of a GAN to approximately correct errors in the GAN generator distribution. We show that under quite strict assumptions, this will allow us to recover the data distribution exactly. We then examine where those strict assumptions break down and design a practical algorithm - called Discriminator Rejection Sampling (DRS) - that can be used on real data-sets. Finally, we demonstrate the efficacy of DRS on a mixture of Gaussians and on the SAGAN model, state-of-the-art in the image generation task at the time of developing this work. On ImageNet, we train an improved baseline that increases the Inception Score from 52.52 to 62.36 and reduces the Frechet Inception Distance from 18.65 to 14.79. We then use DRS to further improve on this baseline, improving the Inception Score to 76.08 and the FID to 13.75.
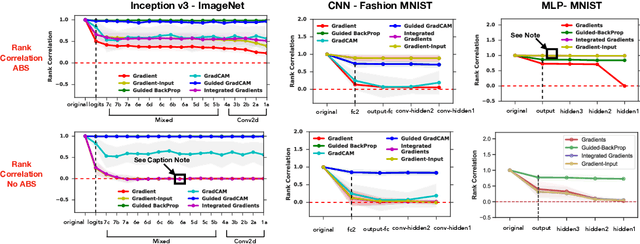
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
Oct 08, 2018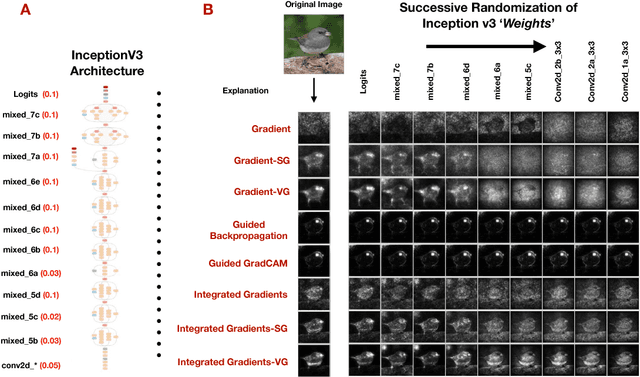
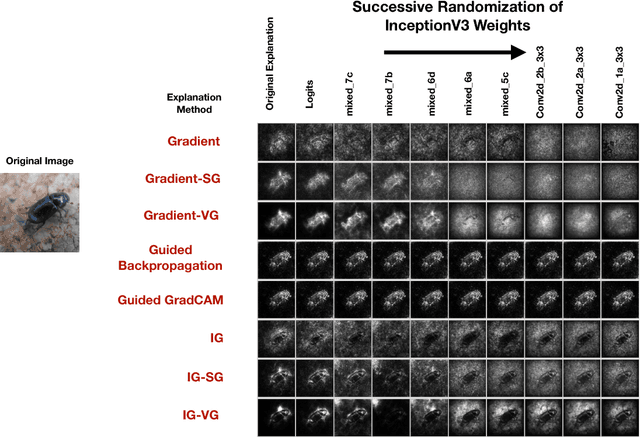
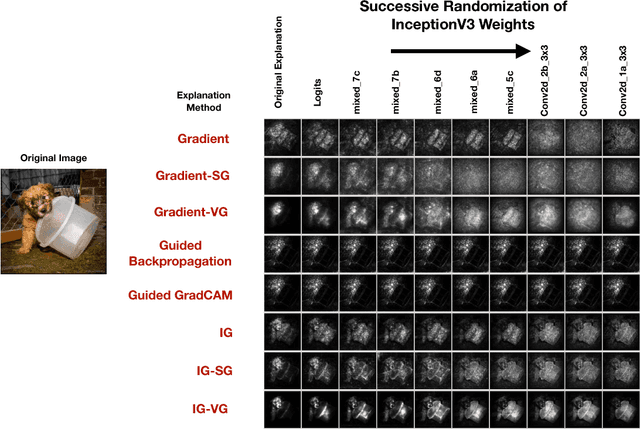
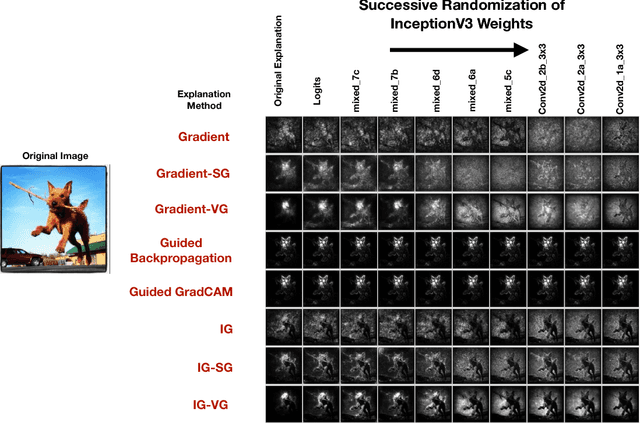
Explaining the output of a complicated machine learning model like a deep neural network (DNN) is a central challenge in machine learning. Several proposed local explanation methods address this issue by identifying what dimensions of a single input are most responsible for a DNN's output. The goal of this work is to assess the sensitivity of local explanations to DNN parameter values. Somewhat surprisingly, we find that DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Our conjecture is that this phenomenon occurs because these explanations are dominated by the lower level features of a DNN, and that a DNN's architecture provides a strong prior which significantly affects the representations learned at these lower layers. NOTE: This work is now subsumed by our recent manuscript, Sanity Checks for Saliency Maps (to appear NIPS 2018), where we expand on findings and address concerns raised in Sundararajan et. al. (2018).