 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows with Iterative Denoising
Apr 21, 2026Normalizing Flows (NFs) are a classical family of likelihood-based methods that have received revived attention. Recent efforts such as TARFlow have shown that NFs are capable of achieving promising performance on image modeling tasks, making them viable alternatives to other methods such as diffusion models. In this work, we further advance the state of Normalizing Flow generative models by introducing iterative TARFlow (iTARFlow). Unlike diffusion models, iTARFlow maintains a fully end-to-end, likelihood-based objective during training. During sampling, it performs autoregressive generation followed by an iterative denoising procedure inspired by diffusion-style methods. Through extensive experiments, we show that iTARFlow achieves competitive performance across ImageNet resolutions of 64, 128, and 256 pixels, demonstrating its potential as a strong generative model and advancing the frontier of Normalizing Flows. In addition, we analyze the characteristic artifacts produced by iTARFlow, offering insights that may shed light on future improvements. Code is available at https://github.com/apple/ml-itarflow.
The Coupling Within: Flow Matching via Distilled Normalizing Flows
Mar 09, 2026Flow models have rapidly become the go-to method for training and deploying large-scale generators, owing their success to inference-time flexibility via adjustable integration steps. A crucial ingredient in flow training is the choice of coupling measure for sampling noise/data pairs that define the flow matching (FM) regression loss. While FM training defaults usually to independent coupling, recent works show that adaptive couplings informed by noise/data distributions (e.g., via optimal transport, OT) improve both model training and inference. We radicalize this insight by shifting the paradigm: rather than computing adaptive couplings directly, we use distilled couplings from a different, pretrained model capable of placing noise and data spaces in bijection -- a property intrinsic to normalizing flows (NF) through their maximum likelihood and invertibility requirements. Leveraging recent advances in NF image generation via auto-regressive (AR) blocks, we propose Normalized Flow Matching (NFM), a new method that distills the quasi-deterministic coupling of pretrained NF models to train student flow models. These students achieve the best of both worlds: significantly outperforming flow models trained with independent or even OT couplings, while also improving on the teacher AR-NF model.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jun 06, 2025
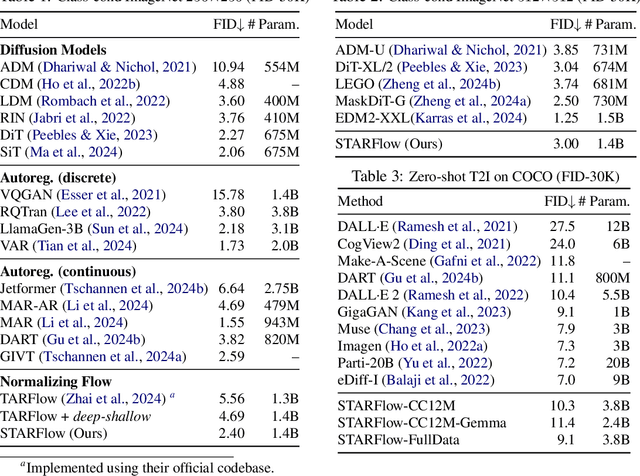
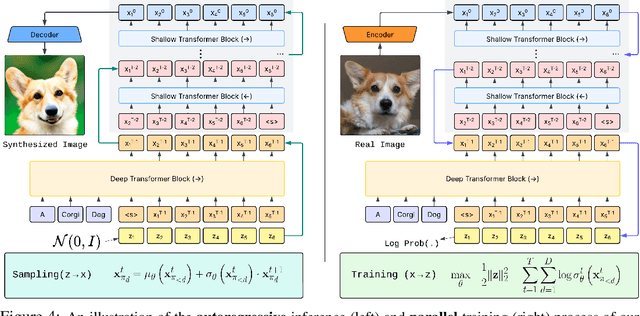
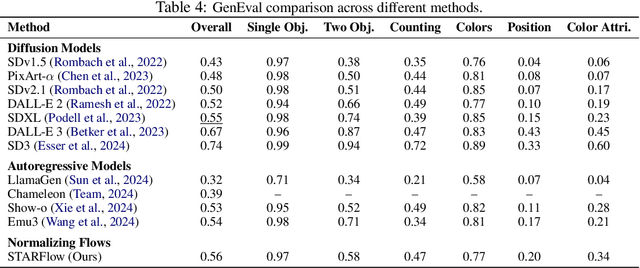
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
Mechanisms of Projective Composition of Diffusion Models
Feb 06, 2025

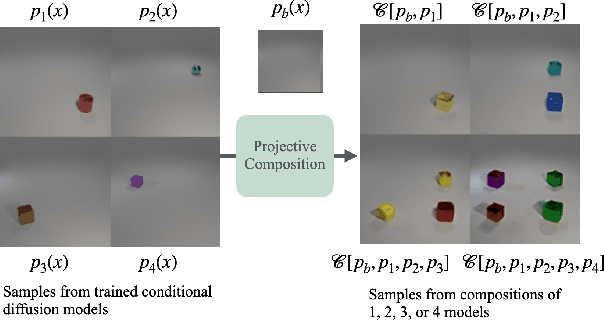
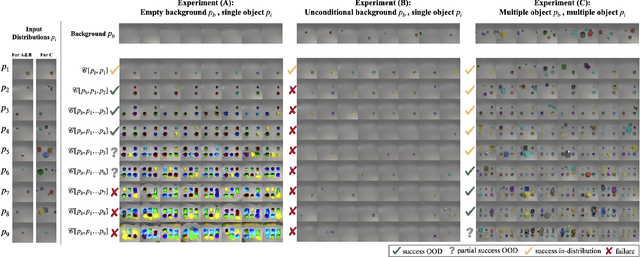
We study the theoretical foundations of composition in diffusion models, with a particular focus on out-of-distribution extrapolation and length-generalization. Prior work has shown that composing distributions via linear score combination can achieve promising results, including length-generalization in some cases (Du et al., 2023; Liu et al., 2022). However, our theoretical understanding of how and why such compositions work remains incomplete. In fact, it is not even entirely clear what it means for composition to "work". This paper starts to address these fundamental gaps. We begin by precisely defining one possible desired result of composition, which we call projective composition. Then, we investigate: (1) when linear score combinations provably achieve projective composition, (2) whether reverse-diffusion sampling can generate the desired composition, and (3) the conditions under which composition fails. Finally, we connect our theoretical analysis to prior empirical observations where composition has either worked or failed, for reasons that were unclear at the time.
Normalizing Flows are Capable Generative Models
Dec 10, 2024Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
Mar 07, 2023



Denoising Diffusion models have demonstrated their proficiency for generative sampling. However, generating good samples often requires many iterations. Consequently, techniques such as binary time-distillation (BTD) have been proposed to reduce the number of network calls for a fixed architecture. In this paper, we introduce TRAnsitive Closure Time-distillation (TRACT), a new method that extends BTD. For single step diffusion,TRACT improves FID by up to 2.4x on the same architecture, and achieves new single-step Denoising Diffusion Implicit Models (DDIM) state-of-the-art FID (7.4 for ImageNet64, 3.8 for CIFAR10). Finally we tease apart the method through extended ablations. The PyTorch implementation will be released soon.
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
Jun 08, 2021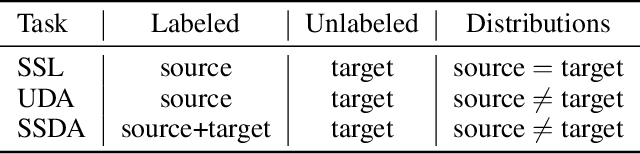
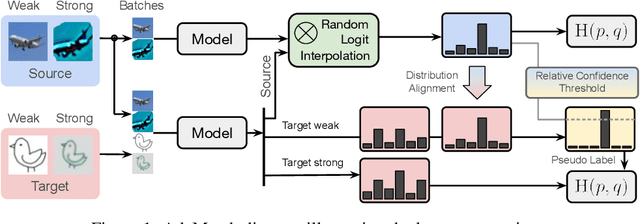

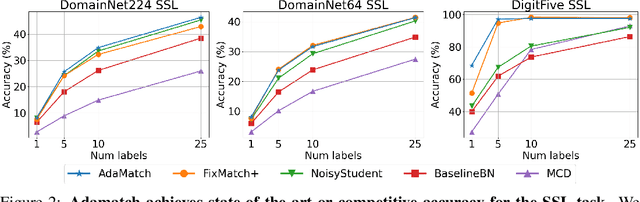
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a method that unifies the tasks of unsupervised domain adaptation (UDA), semi-supervised learning (SSL), and semi-supervised domain adaptation (SSDA). In an extensive experimental study, we compare its behavior with respective state-of-the-art techniques from SSL, SSDA, and UDA on vision classification tasks. We find AdaMatch either matches or significantly exceeds the state-of-the-art in each case using the same hyper-parameters regardless of the dataset or task. For example, AdaMatch nearly doubles the accuracy compared to that of the prior state-of-the-art on the UDA task for DomainNet and even exceeds the accuracy of the prior state-of-the-art obtained with pre-training by 6.4% when AdaMatch is trained completely from scratch. Furthermore, by providing AdaMatch with just one labeled example per class from the target domain (i.e., the SSDA setting), we increase the target accuracy by an additional 6.1%, and with 5 labeled examples, by 13.6%.
Assessing Post-Disaster Damage from Satellite Imagery using Semi-Supervised Learning Techniques
Nov 24, 2020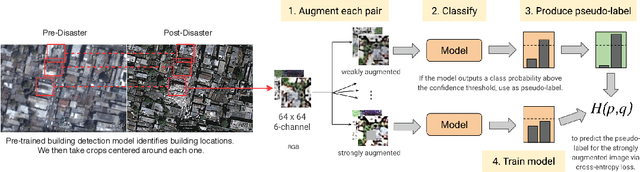
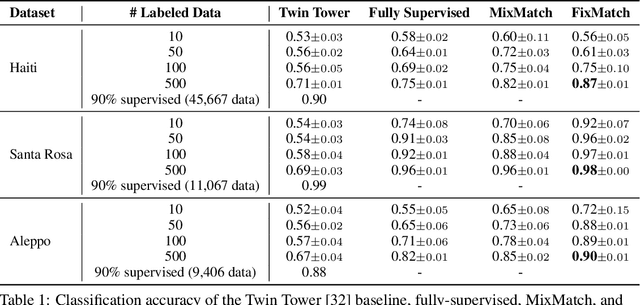
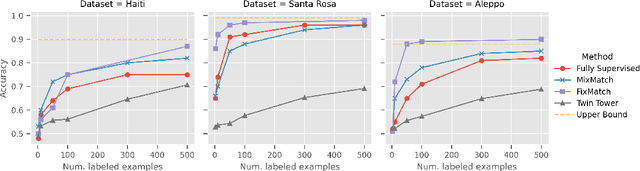
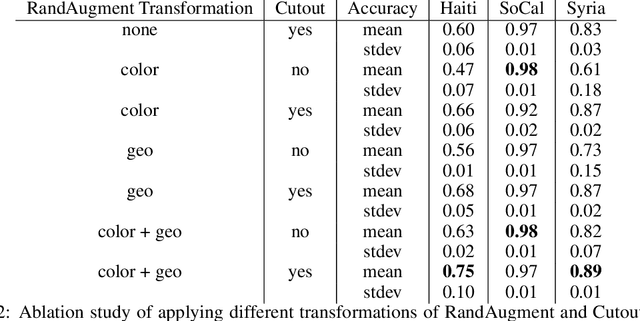
To respond to disasters such as earthquakes, wildfires, and armed conflicts, humanitarian organizations require accurate and timely data in the form of damage assessments, which indicate what buildings and population centers have been most affected. Recent research combines machine learning with remote sensing to automatically extract such information from satellite imagery, reducing manual labor and turn-around time. A major impediment to using machine learning methods in real disaster response scenarios is the difficulty of obtaining a sufficient amount of labeled data to train a model for an unfolding disaster. This paper shows a novel application of semi-supervised learning (SSL) to train models for damage assessment with a minimal amount of labeled data and large amount of unlabeled data. We compare the performance of state-of-the-art SSL methods, including MixMatch and FixMatch, to a supervised baseline for the 2010 Haiti earthquake, 2017 Santa Rosa wildfire, and 2016 armed conflict in Syria. We show how models trained with SSL methods can reach fully supervised performance despite using only a fraction of labeled data and identify areas for further improvements.
Creating High Resolution Images with a Latent Adversarial Generator
Mar 04, 2020



Generating realistic images is difficult, and many formulations for this task have been proposed recently. If we restrict the task to that of generating a particular class of images, however, the task becomes more tractable. That is to say, instead of generating an arbitrary image as a sample from the manifold of natural images, we propose to sample images from a particular "subspace" of natural images, directed by a low-resolution image from the same subspace. The problem we address, while close to the formulation of the single-image super-resolution problem, is in fact rather different. Single image super-resolution is the task of predicting the image closest to the ground truth from a relatively low resolution image. We propose to produce samples of high resolution images given extremely small inputs with a new method called Latent Adversarial Generator (LAG). In our generative sampling framework, we only use the input (possibly of very low-resolution) to direct what class of samples the network should produce. As such, the output of our algorithm is not a unique image that relates to the input, but rather a possible se} of related images sampled from the manifold of natural images. Our method learns exclusively in the latent space of the adversary using perceptual loss -- it does not have a pixel loss.
Semi-Supervised Class Discovery
Feb 22, 2020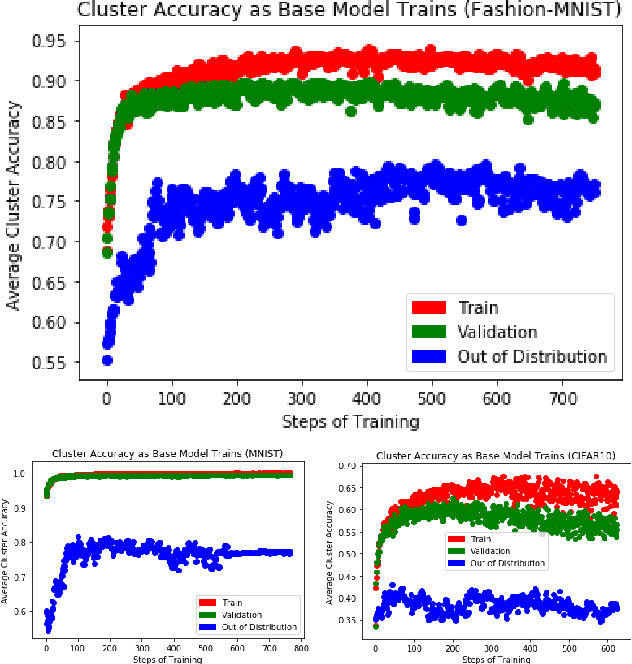
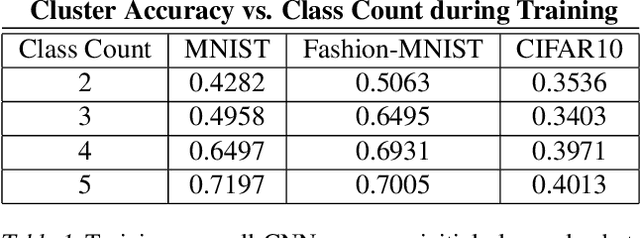
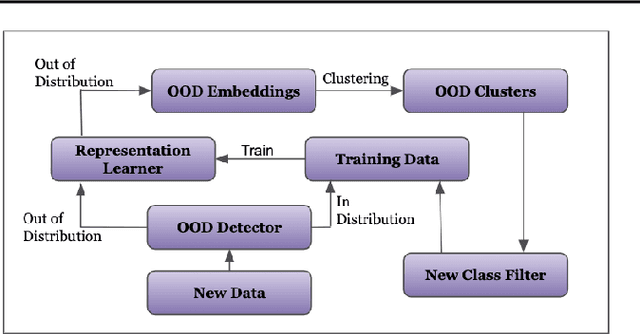
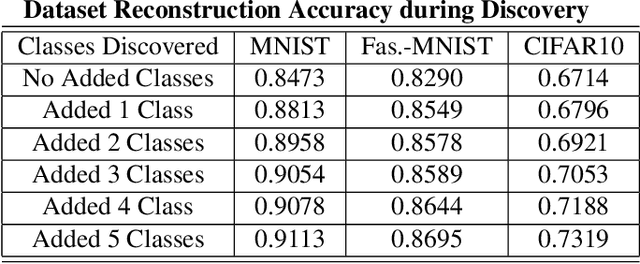
One promising approach to dealing with datapoints that are outside of the initial training distribution (OOD) is to create new classes that capture similarities in the datapoints previously rejected as uncategorizable. Systems that generate labels can be deployed against an arbitrary amount of data, discovering classification schemes that through training create a higher quality representation of data. We introduce the Dataset Reconstruction Accuracy, a new and important measure of the effectiveness of a model's ability to create labels. We introduce benchmarks against this Dataset Reconstruction metric. We apply a new heuristic, class learnability, for deciding whether a class is worthy of addition to the training dataset. We show that our class discovery system can be successfully applied to vision and language, and we demonstrate the value of semi-supervised learning in automatically discovering novel classes.