 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
Mar 07, 2023



Denoising Diffusion models have demonstrated their proficiency for generative sampling. However, generating good samples often requires many iterations. Consequently, techniques such as binary time-distillation (BTD) have been proposed to reduce the number of network calls for a fixed architecture. In this paper, we introduce TRAnsitive Closure Time-distillation (TRACT), a new method that extends BTD. For single step diffusion,TRACT improves FID by up to 2.4x on the same architecture, and achieves new single-step Denoising Diffusion Implicit Models (DDIM) state-of-the-art FID (7.4 for ImageNet64, 3.8 for CIFAR10). Finally we tease apart the method through extended ablations. The PyTorch implementation will be released soon.
Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming
Jun 22, 2022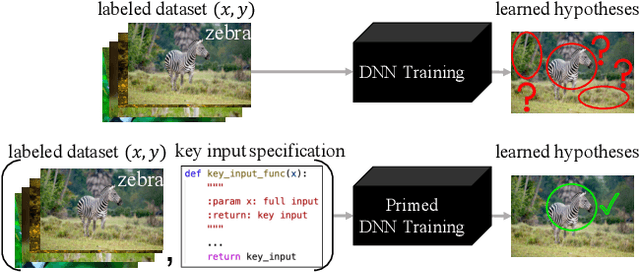

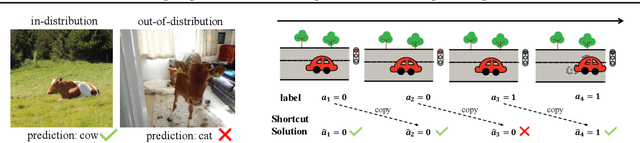
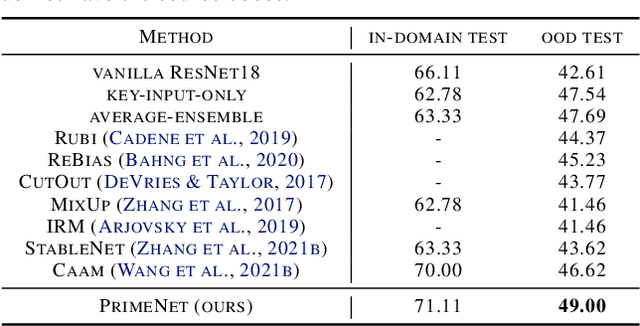
Across applications spanning supervised classification and sequential control, deep learning has been reported to find "shortcut" solutions that fail catastrophically under minor changes in the data distribution. In this paper, we show empirically that DNNs can be coaxed to avoid poor shortcuts by providing an additional "priming" feature computed from key input features, usually a coarse output estimate. Priming relies on approximate domain knowledge of these task-relevant key input features, which is often easy to obtain in practical settings. For example, one might prioritize recent frames over past frames in a video input for visual imitation learning, or salient foreground over background pixels for image classification. On NICO image classification, MuJoCo continuous control, and CARLA autonomous driving, our priming strategy works significantly better than several popular state-of-the-art approaches for feature selection and data augmentation. We connect these empirical findings to recent theoretical results on DNN optimization, and argue theoretically that priming distracts the optimizer away from poor shortcuts by creating better, simpler shortcuts.
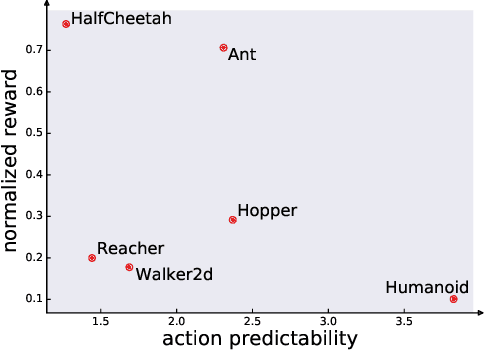
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021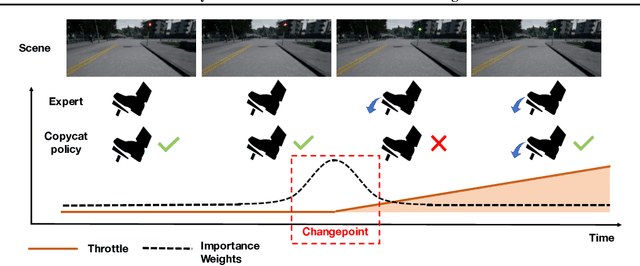
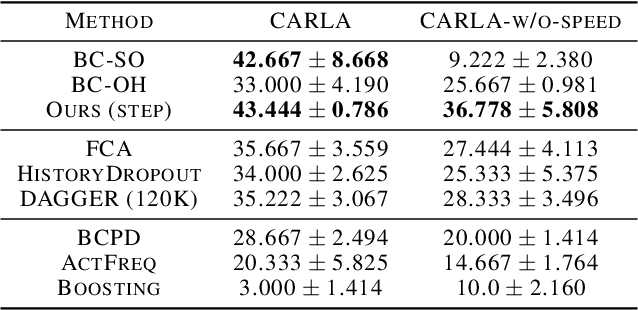

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.
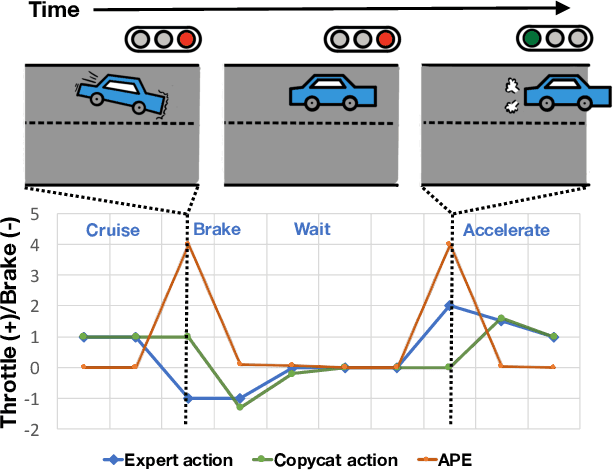
Fighting Copycat Agents in Behavioral Cloning from Observation Histories
Oct 28, 2020


Imitation learning trains policies to map from input observations to the actions that an expert would choose. In this setting, distribution shift frequently exacerbates the effect of misattributing expert actions to nuisance correlates among the observed variables. We observe that a common instance of this causal confusion occurs in partially observed settings when expert actions are strongly correlated over time: the imitator learns to cheat by predicting the expert's previous action, rather than the next action. To combat this "copycat problem", we propose an adversarial approach to learn a feature representation that removes excess information about the previous expert action nuisance correlate, while retaining the information necessary to predict the next action. In our experiments, our approach improves performance significantly across a variety of partially observed imitation learning tasks.
3D Shape Reconstruction from Free-Hand Sketches
Jun 17, 2020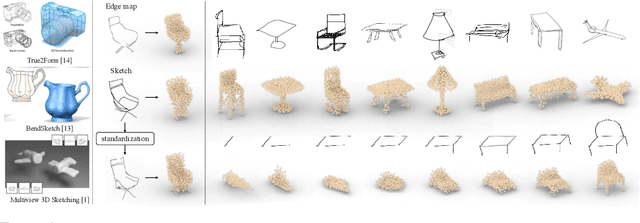

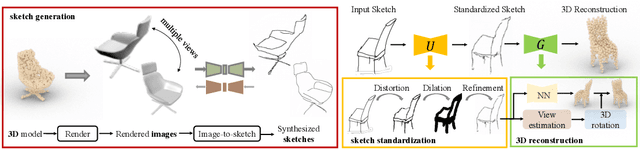

Sketches are the most abstract 2D representations of real-world objects. Although a sketch usually has geometrical distortion and lacks visual cues, humans can effortlessly envision a 3D object from it. This indicates that sketches encode the appropriate information to recover 3D shapes. Although great progress has been achieved in 3D reconstruction from distortion-free line drawings, such as CAD and edge maps, little effort has been made to reconstruct 3D shapes from free-hand sketches. We pioneer to study this task and aim to enhance the power of sketches in 3D-related applications such as interactive design and VR/AR games. Further, we propose an end-to-end sketch-based 3D reconstruction framework. Instead of well-used edge maps, synthesized sketches are adopted as training data. Additionally, we propose a sketch standardization module to handle different sketch styles and distortions. With extensive experiments, we demonstrate the effectiveness of our model and its strong generalizability to various free-hand sketches.
Free-riders in Federated Learning: Attacks and Defenses
Nov 28, 2019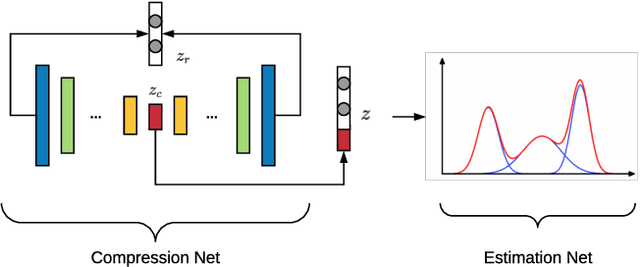
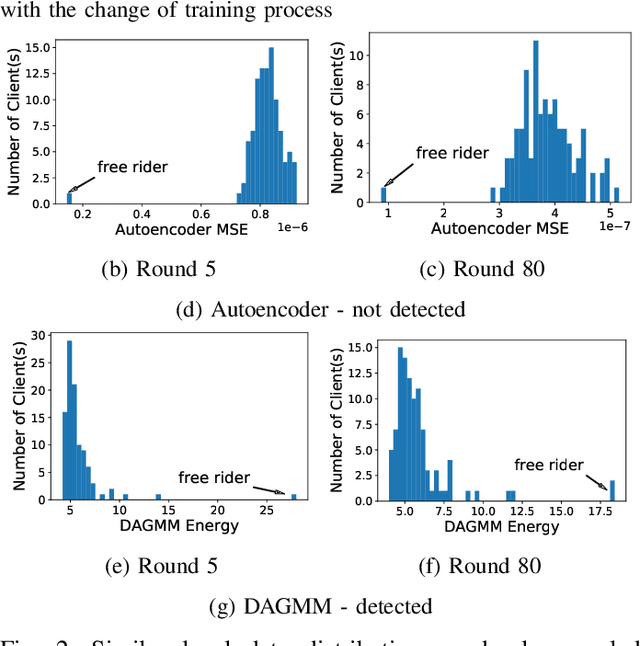
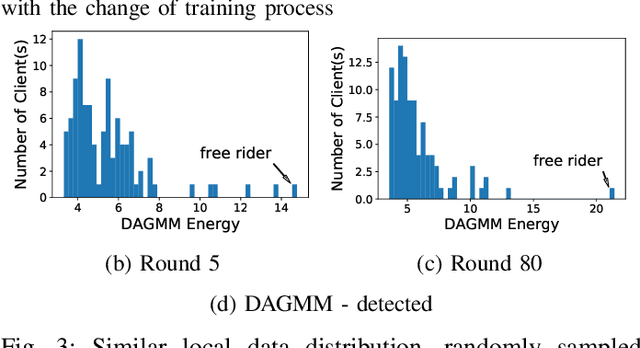
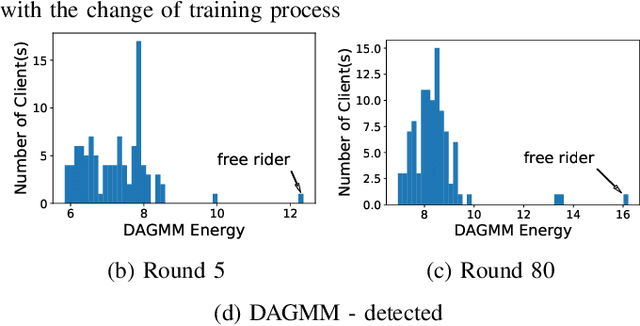
Federated learning is a recently proposed paradigm that enables multiple clients to collaboratively train a joint model. It allows clients to train models locally, and leverages the parameter server to generate a global model by aggregating the locally submitted gradient updates at each round. Although the incentive model for federated learning has not been fully developed, it is supposed that participants are able to get rewards or the privilege to use the final global model, as a compensation for taking efforts to train the model. Therefore, a client who does not have any local data has the incentive to construct local gradient updates in order to deceive for rewards. In this paper, we are the first to propose the notion of free rider attacks, to explore possible ways that an attacker may construct gradient updates, without any local training data. Furthermore, we explore possible defenses that could detect the proposed attacks, and propose a new high dimensional detection method called STD-DAGMM, which particularly works well for anomaly detection of model parameters. We extend the attacks and defenses to consider more free riders as well as differential privacy, which sheds light on and calls for future research in this field.