 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Spatial and Temporal Context for Robotic Imitation Learning With Scene Graphs
May 31, 2026Imitation learning enables robots to learn how to execute tasks via observation. However, real-world environments like homes and offices are often severely partially observed due to their large spatial scales. In addition, many tasks involve executing a series of subtasks requiring autonomous robots to reason over extended time horizons. To address these challenges, we propose using scene graphs as an explicit and structured memory mechanism in imitation learning. By maintaining a dynamic scene graph that captures object-centric relationships and their evolution over time, our method allows the agent to retain relevant historical context during task execution to efficiently reason over incrementally accrued scene information. Our experiments on simulated mobile manipulation and real-world tabletop manipulation demonstrate that our approach substantially improves policy performance, particularly in settings that demand long-term reasoning and robust generalization under partial observability.
NovaPlan: Zero-Shot Long-Horizon Manipulation via Closed-Loop Video Language Planning
Feb 23, 2026Solving long-horizon tasks requires robots to integrate high-level semantic reasoning with low-level physical interaction. While vision-language models (VLMs) and video generation models can decompose tasks and imagine outcomes, they often lack the physical grounding necessary for real-world execution. We introduce NovaPlan, a hierarchical framework that unifies closed-loop VLM and video planning with geometrically grounded robot execution for zero-shot long-horizon manipulation. At the high level, a VLM planner decomposes tasks into sub-goals and monitors robot execution in a closed loop, enabling the system to recover from single-step failures through autonomous re-planning. To compute low-level robot actions, we extract and utilize both task-relevant object keypoints and human hand poses as kinematic priors from the generated videos, and employ a switching mechanism to choose the better one as a reference for robot actions, maintaining stable execution even under heavy occlusion or depth inaccuracy. We demonstrate the effectiveness of NovaPlan on three long-horizon tasks and the Functional Manipulation Benchmark (FMB). Our results show that NovaPlan can perform complex assembly tasks and exhibit dexterous error recovery behaviors without any prior demonstrations or training. Project page: https://nova-plan.github.io/
Task-Oriented Hierarchical Object Decomposition for Visuomotor Control
Nov 02, 2024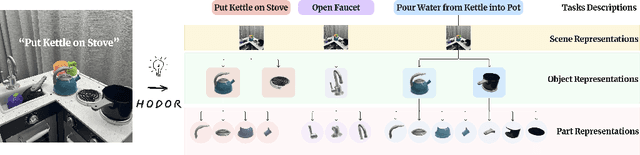
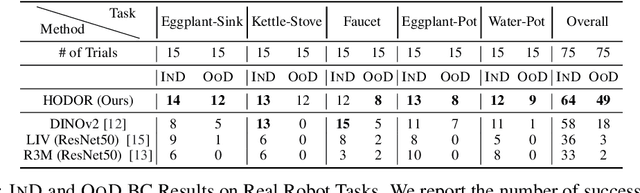
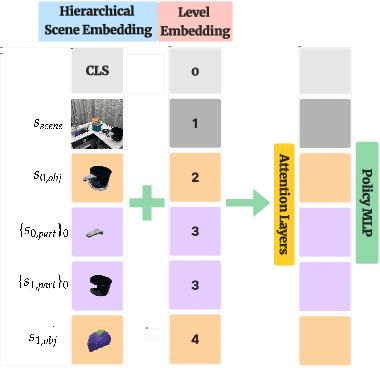
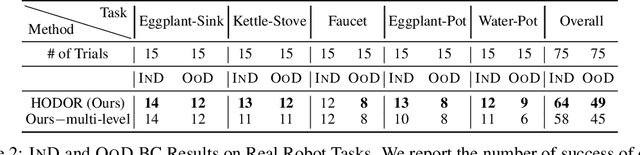
Good pre-trained visual representations could enable robots to learn visuomotor policy efficiently. Still, existing representations take a one-size-fits-all-tasks approach that comes with two important drawbacks: (1) Being completely task-agnostic, these representations cannot effectively ignore any task-irrelevant information in the scene, and (2) They often lack the representational capacity to handle unconstrained/complex real-world scenes. Instead, we propose to train a large combinatorial family of representations organized by scene entities: objects and object parts. This hierarchical object decomposition for task-oriented representations (HODOR) permits selectively assembling different representations specific to each task while scaling in representational capacity with the complexity of the scene and the task. In our experiments, we find that HODOR outperforms prior pre-trained representations, both scene vector representations and object-centric representations, for sample-efficient imitation learning across 5 simulated and 5 real-world manipulation tasks. We further find that the invariances captured in HODOR are inherited into downstream policies, which can robustly generalize to out-of-distribution test conditions, permitting zero-shot skill chaining. Appendix, code, and videos: https://sites.google.com/view/hodor-corl24.
Recasting Generic Pretrained Vision Transformers As Object-Centric Scene Encoders For Manipulation Policies
May 24, 2024



Generic re-usable pre-trained image representation encoders have become a standard component of methods for many computer vision tasks. As visual representations for robots however, their utility has been limited, leading to a recent wave of efforts to pre-train robotics-specific image encoders that are better suited to robotic tasks than their generic counterparts. We propose Scene Objects From Transformers, abbreviated as SOFT, a wrapper around pre-trained vision transformer (PVT) models that bridges this gap without any further training. Rather than construct representations out of only the final layer activations, SOFT individuates and locates object-like entities from PVT attentions, and describes them with PVT activations, producing an object-centric embedding. Across standard choices of generic pre-trained vision transformers PVT, we demonstrate in each case that policies trained on SOFT(PVT) far outstrip standard PVT representations for manipulation tasks in simulated and real settings, approaching the state-of-the-art robotics-aware representations. Code, appendix and videos: https://sites.google.com/view/robot-soft/
Composing Pre-Trained Object-Centric Representations for Robotics From "What" and "Where" Foundation Models
Apr 20, 2024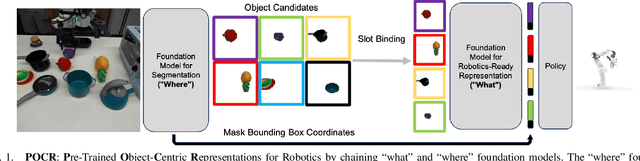
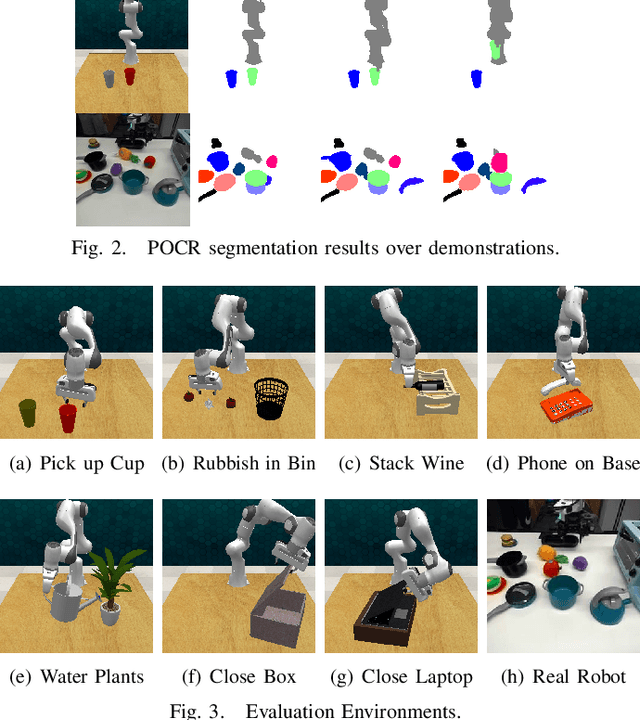


There have recently been large advances both in pre-training visual representations for robotic control and segmenting unknown category objects in general images. To leverage these for improved robot learning, we propose $\textbf{POCR}$, a new framework for building pre-trained object-centric representations for robotic control. Building on theories of "what-where" representations in psychology and computer vision, we use segmentations from a pre-trained model to stably locate across timesteps, various entities in the scene, capturing "where" information. To each such segmented entity, we apply other pre-trained models that build vector descriptions suitable for robotic control tasks, thus capturing "what" the entity is. Thus, our pre-trained object-centric representations for control are constructed by appropriately combining the outputs of off-the-shelf pre-trained models, with no new training. On various simulated and real robotic tasks, we show that imitation policies for robotic manipulators trained on POCR achieve better performance and systematic generalization than state of the art pre-trained representations for robotics, as well as prior object-centric representations that are typically trained from scratch.
Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming
Jun 22, 2022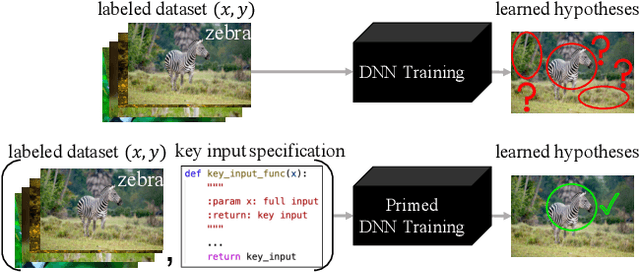

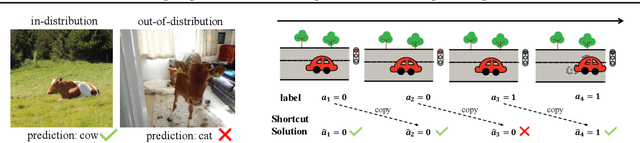
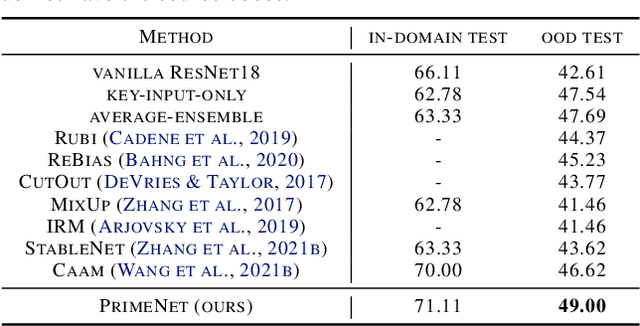
Across applications spanning supervised classification and sequential control, deep learning has been reported to find "shortcut" solutions that fail catastrophically under minor changes in the data distribution. In this paper, we show empirically that DNNs can be coaxed to avoid poor shortcuts by providing an additional "priming" feature computed from key input features, usually a coarse output estimate. Priming relies on approximate domain knowledge of these task-relevant key input features, which is often easy to obtain in practical settings. For example, one might prioritize recent frames over past frames in a video input for visual imitation learning, or salient foreground over background pixels for image classification. On NICO image classification, MuJoCo continuous control, and CARLA autonomous driving, our priming strategy works significantly better than several popular state-of-the-art approaches for feature selection and data augmentation. We connect these empirical findings to recent theoretical results on DNN optimization, and argue theoretically that priming distracts the optimizer away from poor shortcuts by creating better, simpler shortcuts.
Keyframe-Focused Visual Imitation Learning
Jun 11, 2021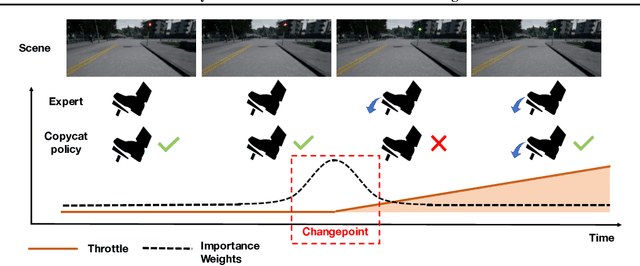
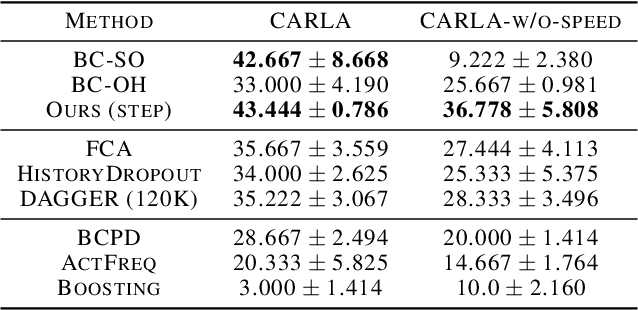
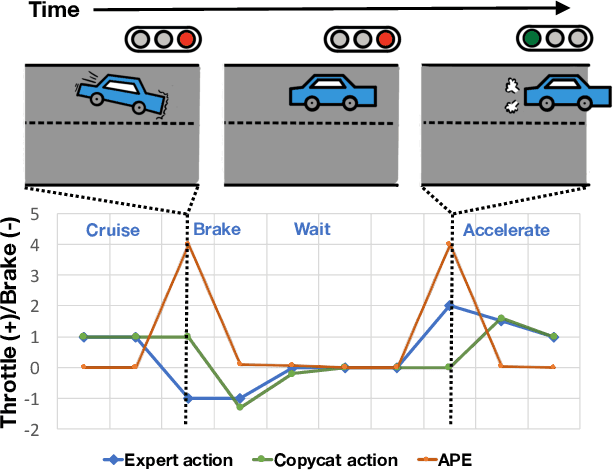

Imitation learning trains control policies by mimicking pre-recorded expert demonstrations. In partially observable settings, imitation policies must rely on observation histories, but many seemingly paradoxical results show better performance for policies that only access the most recent observation. Recent solutions ranging from causal graph learning to deep information bottlenecks have shown promising results, but failed to scale to realistic settings such as visual imitation. We propose a solution that outperforms these prior approaches by upweighting demonstration keyframes corresponding to expert action changepoints. This simple approach easily scales to complex visual imitation settings. Our experimental results demonstrate consistent performance improvements over all baselines on image-based Gym MuJoCo continuous control tasks. Finally, on the CARLA photorealistic vision-based urban driving simulator, we resolve a long-standing issue in behavioral cloning for driving by demonstrating effective imitation from observation histories. Supplementary materials and code at: \url{https://tinyurl.com/imitation-keyframes}.
Robust Instance Tracking via Uncertainty Flow
Oct 09, 2020
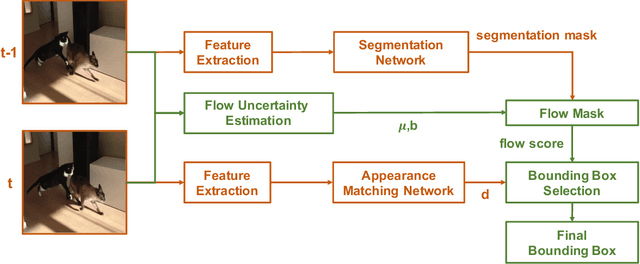
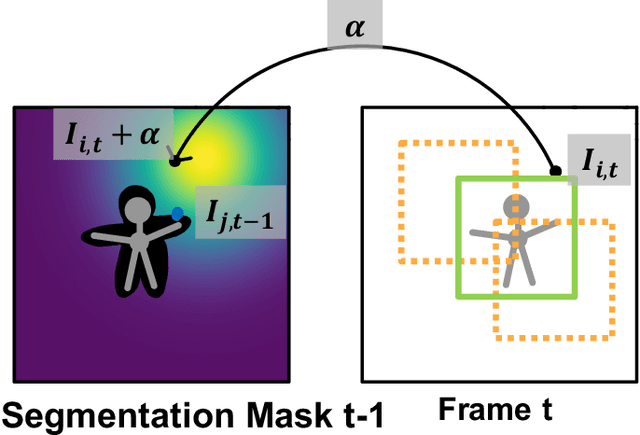
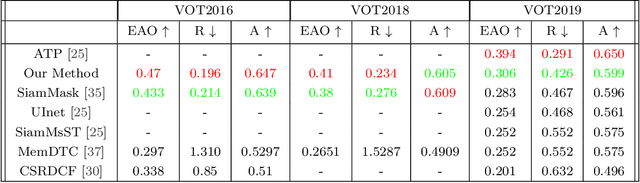
Current state-of-the-art trackers often fail due to distractorsand large object appearance changes. In this work, we explore the use ofdense optical flow to improve tracking robustness. Our main insight is that, because flow estimation can also have errors, we need to incorporate an estimate of flow uncertainty for robust tracking. We present a novel tracking framework which combines appearance and flow uncertainty information to track objects in challenging scenarios. We experimentally verify that our framework improves tracking robustness, leading to new state-of-the-art results. Further, our experimental ablations shows the importance of flow uncertainty for robust tracking.
Cloth Region Segmentation for Robust Grasp Selection
Aug 13, 2020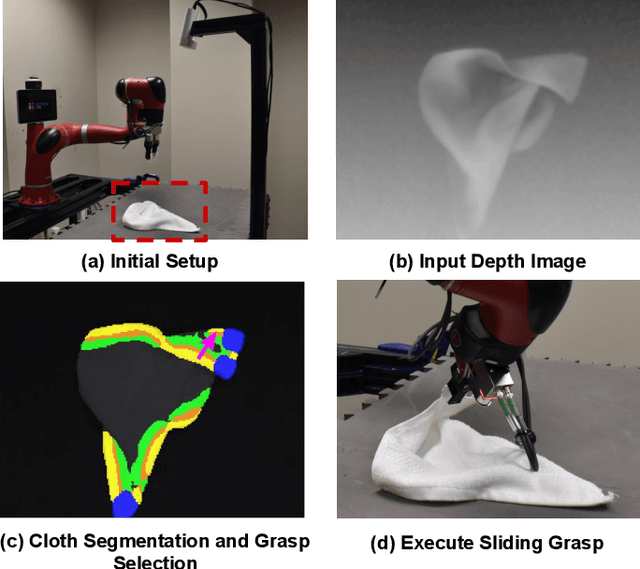
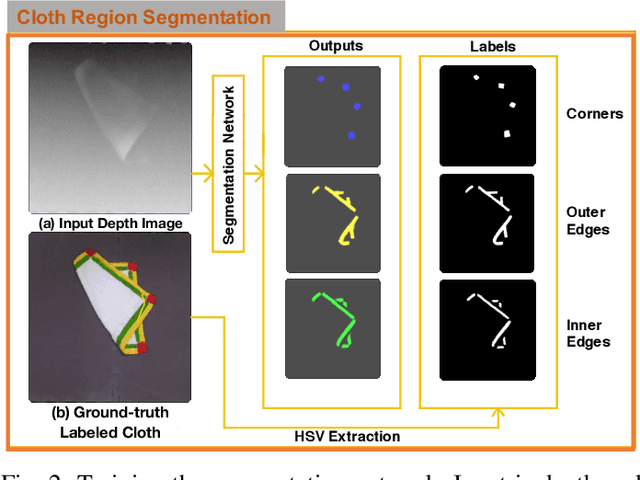
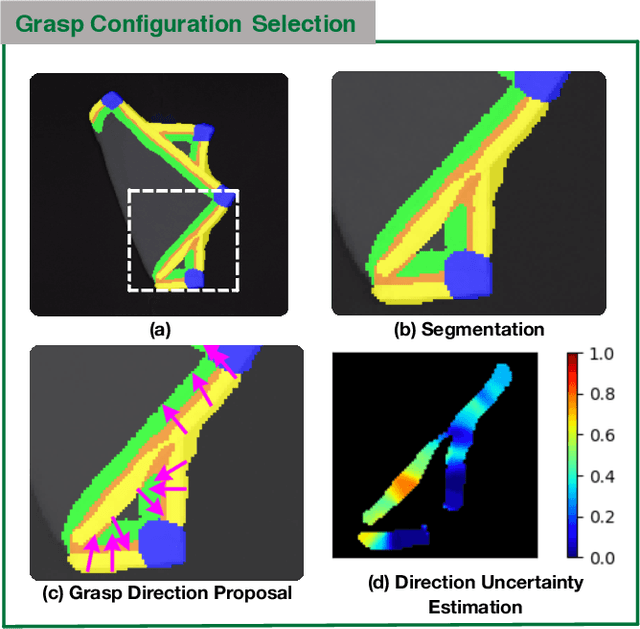

Cloth detection and manipulation is a common task in domestic and industrial settings, yet such tasks remain a challenge for robots due to cloth deformability. Furthermore, in many cloth-related tasks like laundry folding and bed making, it is crucial to manipulate specific regions like edges and corners, as opposed to folds. In this work, we focus on the problem of segmenting and grasping these key regions. Our approach trains a network to segment the edges and corners of a cloth from a depth image, distinguishing such regions from wrinkles or folds. We also provide a novel algorithm for estimating the grasp location, direction, and directional uncertainty from the segmentation. We demonstrate our method on a real robot system and show that it outperforms baseline methods on grasping success. Video and other supplementary materials are available at: https://sites.google.com/view/cloth-segmentation.
FusionMapping: Learning Depth Prediction with Monocular Images and 2D Laser Scans
Nov 29, 2019
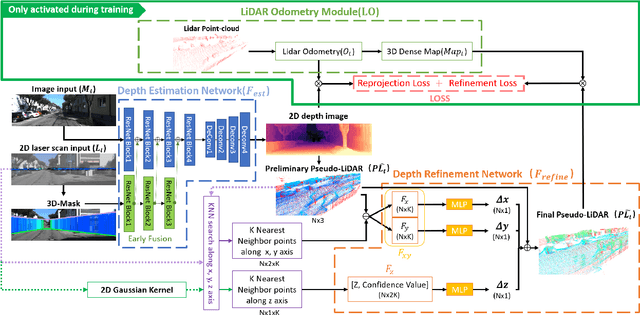

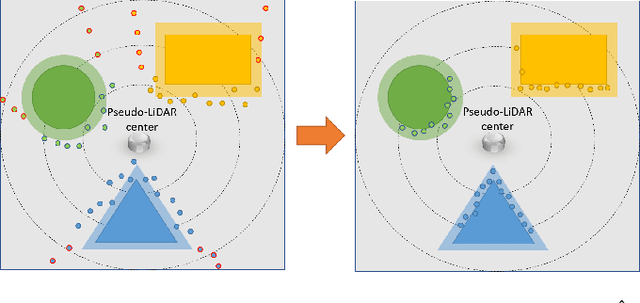
Acquiring accurate three-dimensional depth information conventionally requires expensive multibeam LiDAR devices. Recently, researchers have developed a less expensive option by predicting depth information from two-dimensional color imagery. However, there still exists a substantial gap in accuracy between depth information estimated from two-dimensional images and real LiDAR point-cloud. In this paper, we introduce a fusion-based depth prediction method, called FusionMapping. This is the first method that fuses colored imagery and two-dimensional laser scan to estimate depth in-formation. More specifically, we propose an autoencoder-based depth prediction network and a novel point-cloud refinement network for depth estimation. We analyze the performance of our FusionMapping approach on the KITTI LiDAR odometry dataset and an indoor mobile robot system. The results show that our introduced approach estimates depth with better accuracy when compared to existing methods.