 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Hierarchical Object Decomposition for Visuomotor Control
Paper and Code
Nov 02, 2024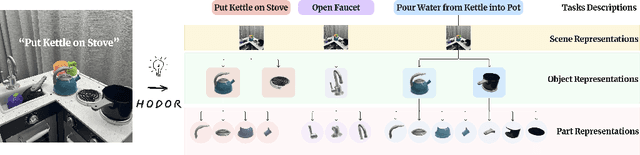
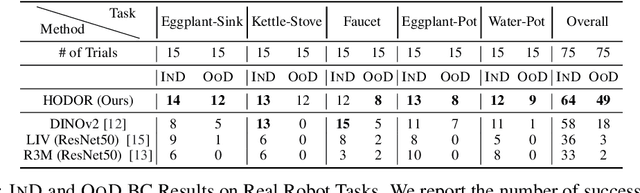
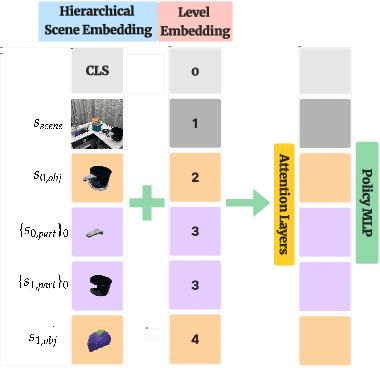
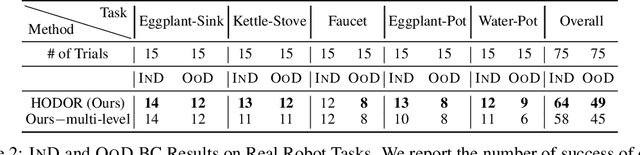
Good pre-trained visual representations could enable robots to learn visuomotor policy efficiently. Still, existing representations take a one-size-fits-all-tasks approach that comes with two important drawbacks: (1) Being completely task-agnostic, these representations cannot effectively ignore any task-irrelevant information in the scene, and (2) They often lack the representational capacity to handle unconstrained/complex real-world scenes. Instead, we propose to train a large combinatorial family of representations organized by scene entities: objects and object parts. This hierarchical object decomposition for task-oriented representations (HODOR) permits selectively assembling different representations specific to each task while scaling in representational capacity with the complexity of the scene and the task. In our experiments, we find that HODOR outperforms prior pre-trained representations, both scene vector representations and object-centric representations, for sample-efficient imitation learning across 5 simulated and 5 real-world manipulation tasks. We further find that the invariances captured in HODOR are inherited into downstream policies, which can robustly generalize to out-of-distribution test conditions, permitting zero-shot skill chaining. Appendix, code, and videos: https://sites.google.com/view/hodor-corl24.