 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Hierarchical Object Decomposition for Visuomotor Control
Nov 02, 2024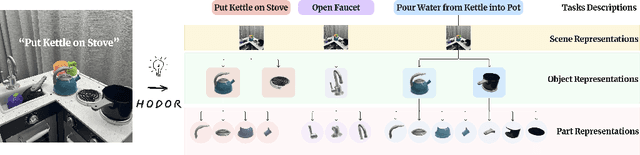
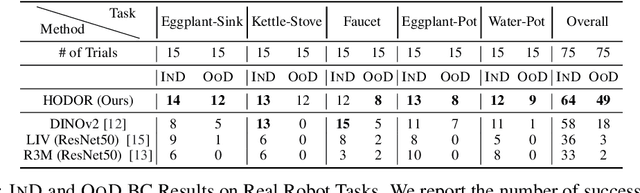
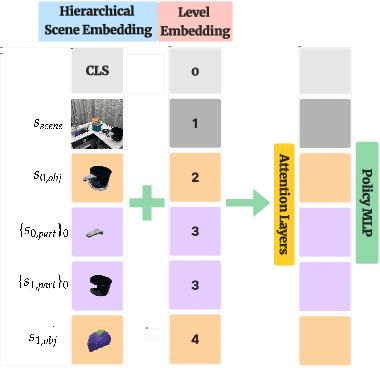
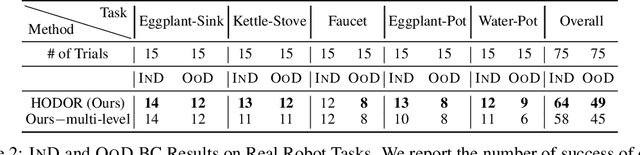
Good pre-trained visual representations could enable robots to learn visuomotor policy efficiently. Still, existing representations take a one-size-fits-all-tasks approach that comes with two important drawbacks: (1) Being completely task-agnostic, these representations cannot effectively ignore any task-irrelevant information in the scene, and (2) They often lack the representational capacity to handle unconstrained/complex real-world scenes. Instead, we propose to train a large combinatorial family of representations organized by scene entities: objects and object parts. This hierarchical object decomposition for task-oriented representations (HODOR) permits selectively assembling different representations specific to each task while scaling in representational capacity with the complexity of the scene and the task. In our experiments, we find that HODOR outperforms prior pre-trained representations, both scene vector representations and object-centric representations, for sample-efficient imitation learning across 5 simulated and 5 real-world manipulation tasks. We further find that the invariances captured in HODOR are inherited into downstream policies, which can robustly generalize to out-of-distribution test conditions, permitting zero-shot skill chaining. Appendix, code, and videos: https://sites.google.com/view/hodor-corl24.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Universal Visual Decomposer: Long-Horizon Manipulation Made Easy
Oct 12, 2023



Real-world robotic tasks stretch over extended horizons and encompass multiple stages. Learning long-horizon manipulation tasks, however, is a long-standing challenge, and demands decomposing the overarching task into several manageable subtasks to facilitate policy learning and generalization to unseen tasks. Prior task decomposition methods require task-specific knowledge, are computationally intensive, and cannot readily be applied to new tasks. To address these shortcomings, we propose Universal Visual Decomposer (UVD), an off-the-shelf task decomposition method for visual long horizon manipulation using pre-trained visual representations designed for robotic control. At a high level, UVD discovers subgoals by detecting phase shifts in the embedding space of the pre-trained representation. Operating purely on visual demonstrations without auxiliary information, UVD can effectively extract visual subgoals embedded in the videos, while incurring zero additional training cost on top of standard visuomotor policy training. Goal-conditioned policies learned with UVD-discovered subgoals exhibit significantly improved compositional generalization at test time to unseen tasks. Furthermore, UVD-discovered subgoals can be used to construct goal-based reward shaping that jump-starts temporally extended exploration for reinforcement learning. We extensively evaluate UVD on both simulation and real-world tasks, and in all cases, UVD substantially outperforms baselines across imitation and reinforcement learning settings on in-domain and out-of-domain task sequences alike, validating the clear advantage of automated visual task decomposition within the simple, compact UVD framework.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
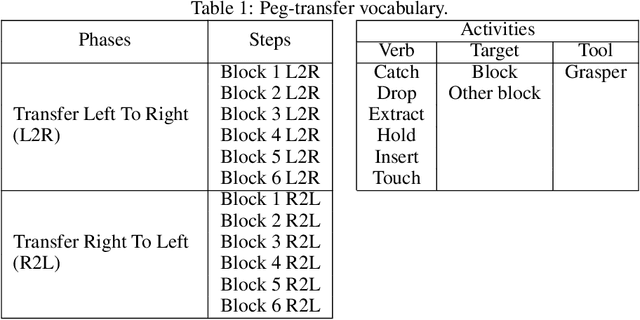
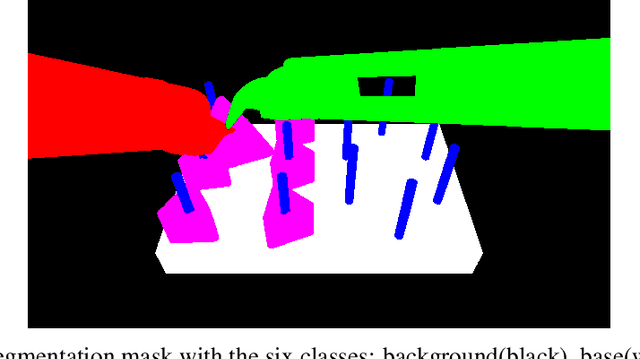
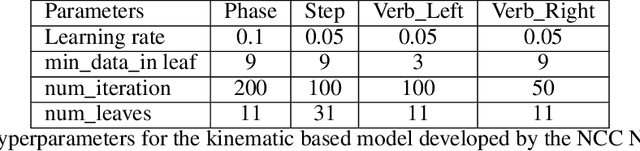
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
Control of Pneumatic Artificial Muscles with SNN-based Cerebellar-like Model
Sep 22, 2021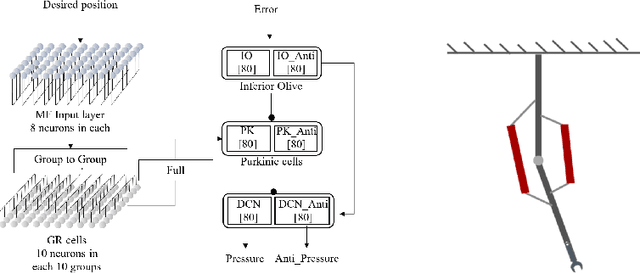
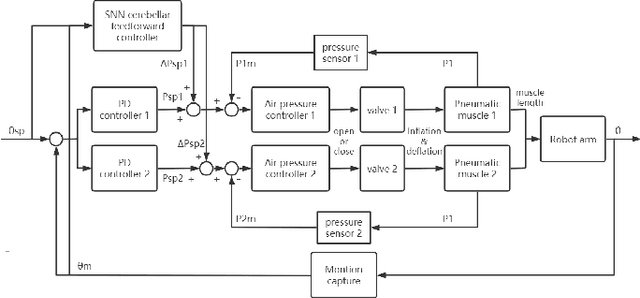
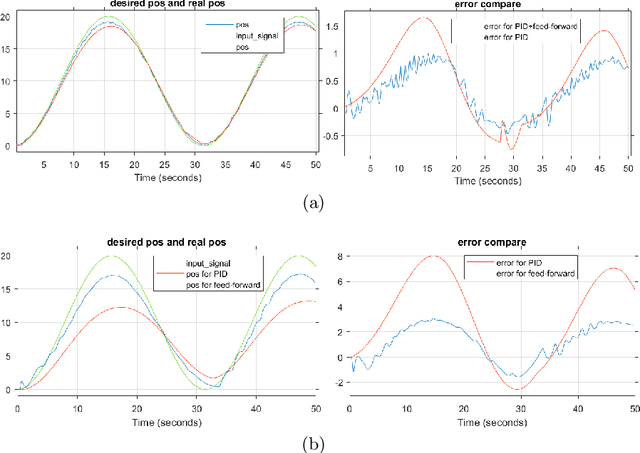
Soft robotics technologies have gained growing interest in recent years, which allows various applications from manufacturing to human-robot interaction. Pneumatic artificial muscle (PAM), a typical soft actuator, has been widely applied to soft robots. The compliance and resilience of soft actuators allow soft robots to behave compliant when interacting with unstructured environments, while the utilization of soft actuators also introduces nonlinearity and uncertainty. Inspired by Cerebellum's vital functions in control of human's physical movement, a neural network model of Cerebellum based on spiking neuron networks (SNNs) is designed. This model is used as a feed-forward controller in controlling a 1-DOF robot arm driven by PAMs. The simulation results show that this Cerebellar-based system achieves good performance and increases the system's response.
Collaborative Recognition of Feasible region with Aerial and Ground Robots through DPCN
Mar 01, 2021
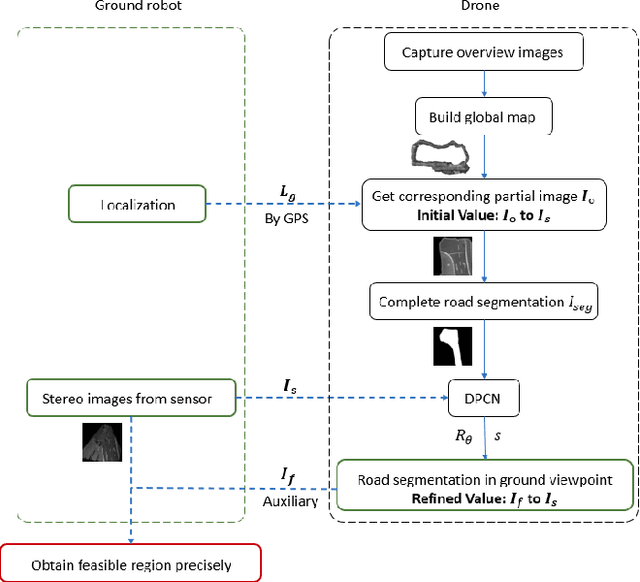
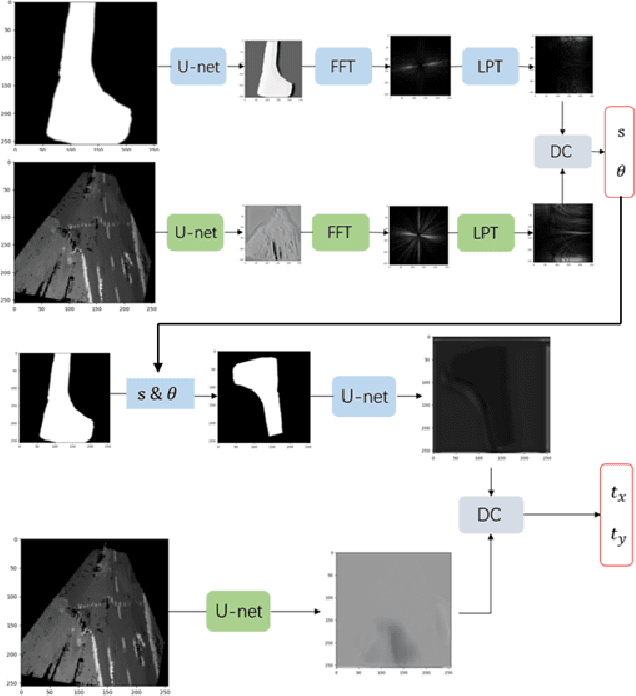

Ground robots always get collision in that only if they get close to the obstacles, can they sense the danger and take actions, which is usually too late to avoid the crash, causing severe damage to the robots. To address this issue, we present collaboration of aerial and ground robots in recognition of feasible region. Taking the aerial robots' advantages of having large scale variance of view points of the same route which the ground robots is on, the collaboration work provides global information of road segmentation for the ground robot, thus enabling it to obtain feasible region and adjust its pose ahead of time. Under normal circumstance, the transformation between these two devices can be obtained by GPS yet with much error, directly causing inferior influence on recognition of feasible region. Thereby, we utilize the state-of-the-art research achievements in matching heterogeneous sensor measurements called deep phase correlation network(DPCN), which has excellent performance on heterogeneous mapping, to refine the transformation. The network is light-weighted and promising for better generalization. We use Aero-Ground dataset which consists of heterogeneous sensor images and aerial road segmentation images. The results show that our collaborative system has great accuracy, speed and stability.