 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
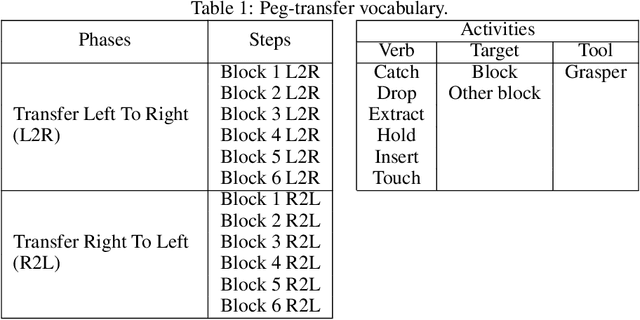
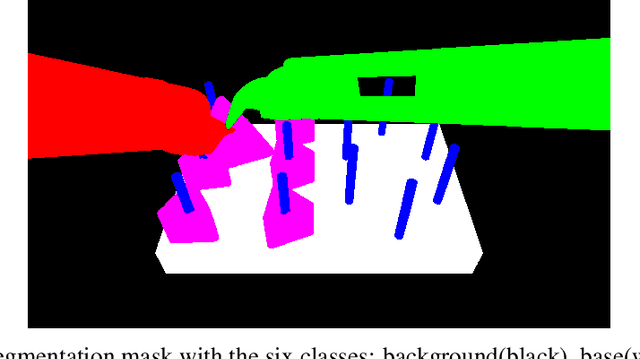
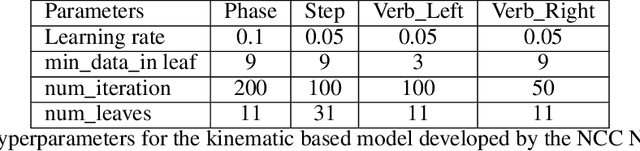
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
Car Pose in Context: Accurate Pose Estimation with Ground Plane Constraints
Dec 09, 2019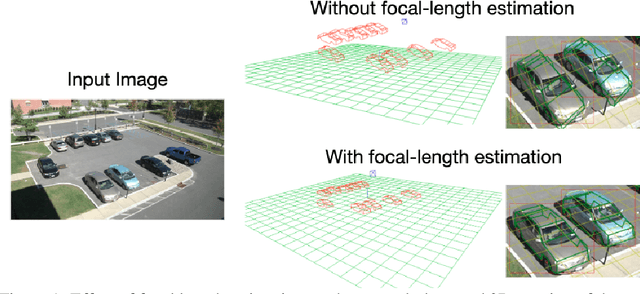
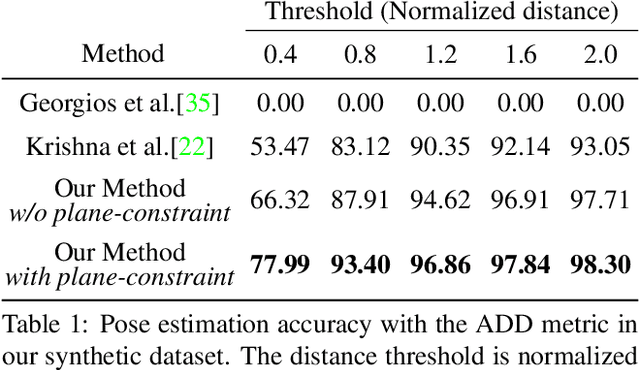
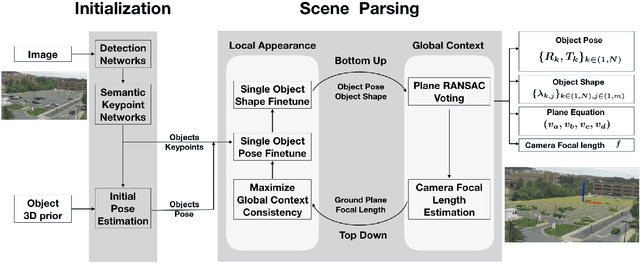
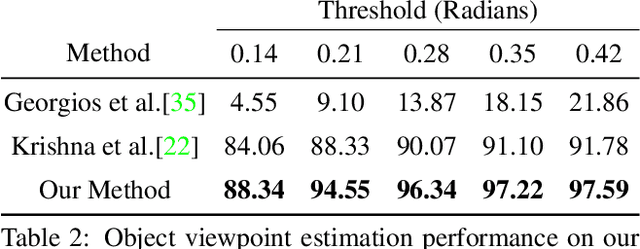
Scene context is a powerful constraint on the geometry of objects within the scene in cases, such as surveillance, where the camera geometry is unknown and image quality may be poor. In this paper, we describe a method for estimating the pose of cars in a scene jointly with the ground plane that supports them. We formulate this as a joint optimization that accounts for varying car shape using a statistical atlas, and which simultaneously computes geometry and internal camera parameters. We demonstrate that this method produces significant improvements for car pose estimation, and we show that the resulting 3D geometry, when computed over a video sequence, makes it possible to improve on state of the art classification of car behavior. We also show that introducing the planar constraint allows us to estimate camera focal length in a reliable manner.
Zero-shot Recognition of Complex Action Sequences
Dec 08, 2019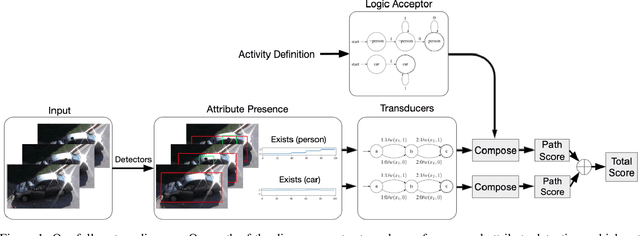
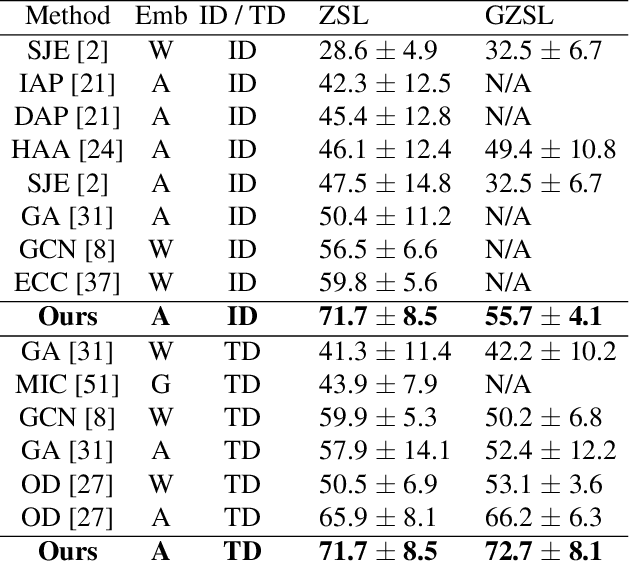
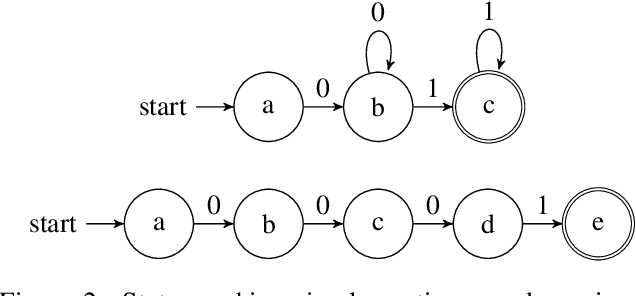
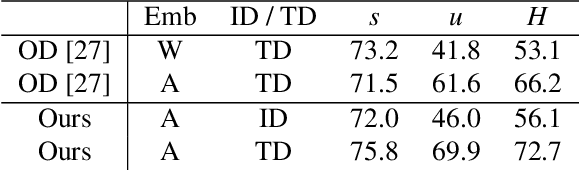
Zero-shot video classification for fine-grained activity recognition has largely been explored using methods similar to its image-based counterpart, namely by defining image-derived attributes that serve to discriminate among classes. However, such methods do not capture the fundamental dynamics of activities and are thus limited to cases where static image content alone suffices to classify an activity. For example, reversible actions such as entering and exiting a car are often indistinguishable. In this work, we present a framework for straightforward modeling of activities as a state machine of dynamic attributes. We show that encoding the temporal structure of attributes greatly increases our modeling power, allowing us to capture action direction, for example. Further, we can extend this to activity detection using dynamic programming, providing, to our knowledge, the first example of zero-shot joint segmentation and classification of complex action sequences in a larger video. We evaluate our method on the Olympic Sports dataset where our model establishes a new state of the art for standard zero-shot-learning (ZSL) evaluation as well as outperforming all other models in the inductive category for general (GZSL) zero-shot evaluation. Additionally, we are the first to demonstrate zero-shot decoding of complex action sequences on a widely used surgical dataset. Lastly, we show that that we can even eliminate the need to train attribute detectors by using off-the-shelf object detectors to recognize activities in challenging surveillance videos.
Action Recognition Using Volumetric Motion Representations
Nov 19, 2019

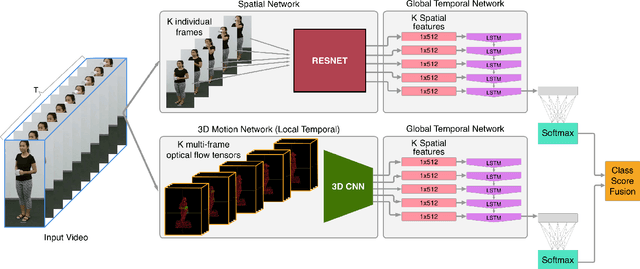
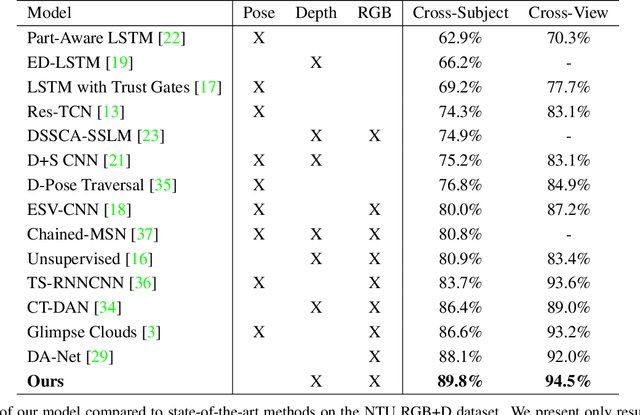
Traditional action recognition models are constructed around the paradigm of 2D perspective imagery. Though sophisticated time-series models have pushed the field forward, much of the information is still not exploited by confining the domain to 2D. In this work, we introduce a novel representation of motion as a voxelized 3D vector field and demonstrate how it can be used to improve performance of action recognition networks. This volumetric representation is a natural fit for 3D CNNs, and allows out-of-plane data augmentation techniques during training of these networks. Both the construction of this representation from RGB-D video and inference can be run in real time. We demonstrate superior results using this representation with our network design on the open-source NTU RGB+D dataset where it outperforms state-of-the-art on both of the defined evaluation metrics. Furthermore, we experimentally show how the out-of-plane augmentation techniques create viewpoint invariance and allow the model trained using this representation to generalize to unseen camera angles. Code is available here: https://github.com/mpeven/ntu_rgb.
Learning to See Forces: Surgical Force Prediction with RGB-Point Cloud Temporal Convolutional Networks
Jul 31, 2018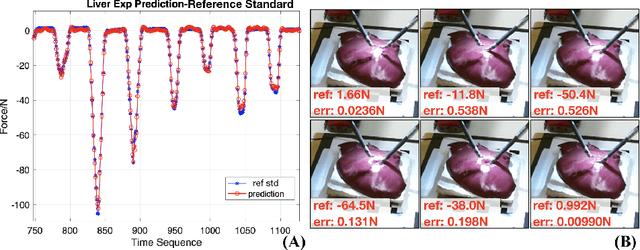
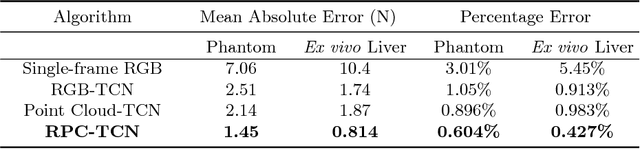

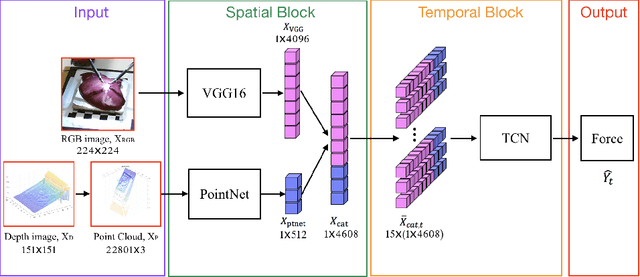
Robotic surgery has been proven to offer clear advantages during surgical procedures, however, one of the major limitations is obtaining haptic feedback. Since it is often challenging to devise a hardware solution with accurate force feedback, we propose the use of "visual cues" to infer forces from tissue deformation. Endoscopic video is a passive sensor that is freely available, in the sense that any minimally-invasive procedure already utilizes it. To this end, we employ deep learning to infer forces from video as an attractive low-cost and accurate alternative to typically complex and expensive hardware solutions. First, we demonstrate our approach in a phantom setting using the da Vinci Surgical System affixed with an OptoForce sensor. Second, we then validate our method on an ex vivo liver organ. Our method results in a mean absolute error of 0.814 N in the ex vivo study, suggesting that it may be a promising alternative to hardware based surgical force feedback in endoscopic procedures.