 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained activity recognition for assembly videos
Dec 02, 2020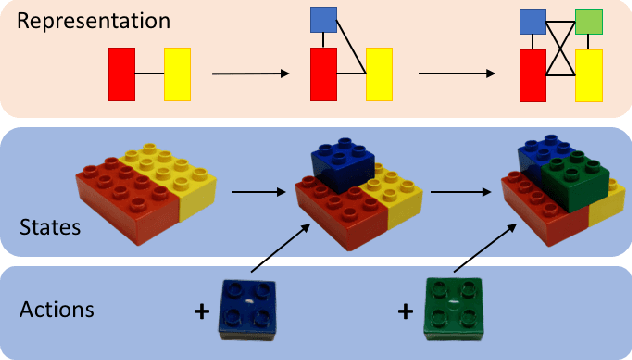
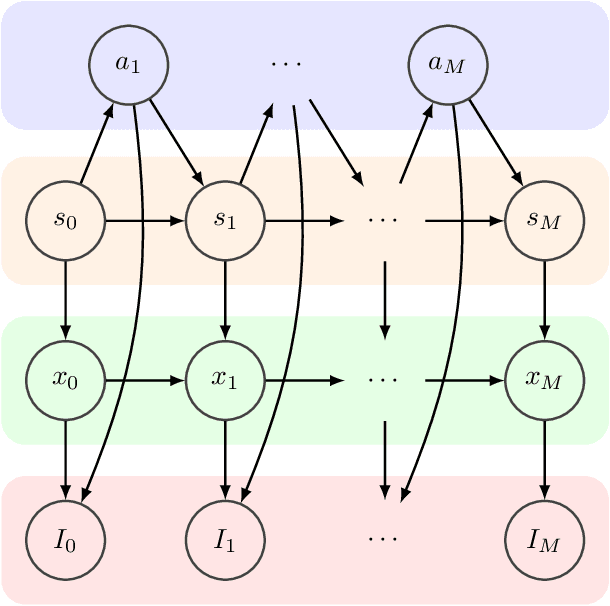

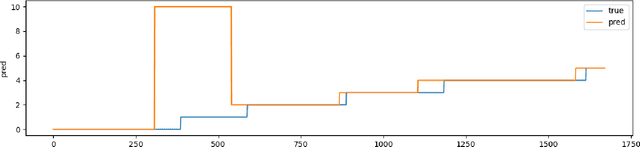
In this paper we address the task of recognizing assembly actions as a structure (e.g. a piece of furniture or a toy block tower) is built up from a set of primitive objects. Recognizing the full range of assembly actions requires perception at a level of spatial detail that has not been attempted in the action recognition literature to date. We extend the fine-grained activity recognition setting to address the task of assembly action recognition in its full generality by unifying assembly actions and kinematic structures within a single framework. We use this framework to develop a general method for recognizing assembly actions from observation sequences, along with observation features that take advantage of a spatial assembly's special structure. Finally, we evaluate our method empirically on two application-driven data sources: (1) An IKEA furniture-assembly dataset, and (2) A block-building dataset. On the first, our system recognizes assembly actions with an average framewise accuracy of 70% and an average normalized edit distance of 10%. On the second, which requires fine-grained geometric reasoning to distinguish between assemblies, our system attains an average normalized edit distance of 23% -- a relative improvement of 69% over prior work.
Zero-shot Recognition of Complex Action Sequences
Dec 08, 2019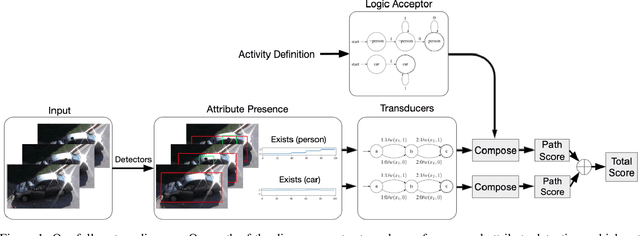
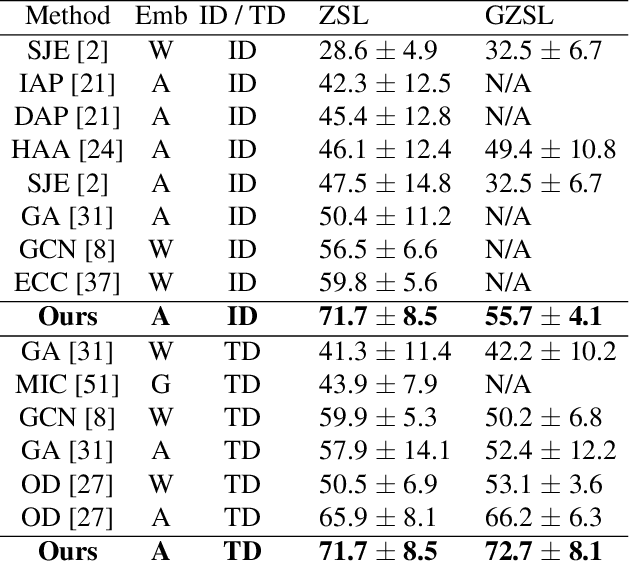
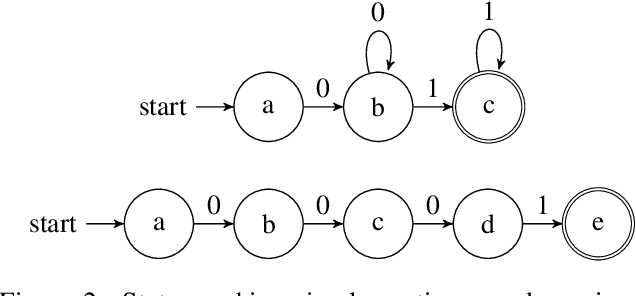
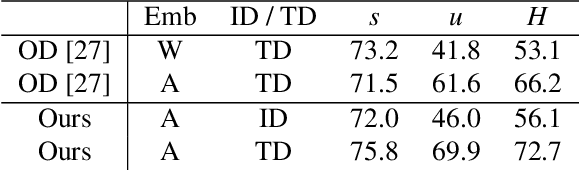
Zero-shot video classification for fine-grained activity recognition has largely been explored using methods similar to its image-based counterpart, namely by defining image-derived attributes that serve to discriminate among classes. However, such methods do not capture the fundamental dynamics of activities and are thus limited to cases where static image content alone suffices to classify an activity. For example, reversible actions such as entering and exiting a car are often indistinguishable. In this work, we present a framework for straightforward modeling of activities as a state machine of dynamic attributes. We show that encoding the temporal structure of attributes greatly increases our modeling power, allowing us to capture action direction, for example. Further, we can extend this to activity detection using dynamic programming, providing, to our knowledge, the first example of zero-shot joint segmentation and classification of complex action sequences in a larger video. We evaluate our method on the Olympic Sports dataset where our model establishes a new state of the art for standard zero-shot-learning (ZSL) evaluation as well as outperforming all other models in the inductive category for general (GZSL) zero-shot evaluation. Additionally, we are the first to demonstrate zero-shot decoding of complex action sequences on a widely used surgical dataset. Lastly, we show that that we can even eliminate the need to train attribute detectors by using off-the-shelf object detectors to recognize activities in challenging surveillance videos.