 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
ComGS: Efficient 3D Object-Scene Composition via Surface Octahedral Probes
Oct 09, 2025Gaussian Splatting (GS) enables immersive rendering, but realistic 3D object-scene composition remains challenging. Baked appearance and shadow information in GS radiance fields cause inconsistencies when combining objects and scenes. Addressing this requires relightable object reconstruction and scene lighting estimation. For relightable object reconstruction, existing Gaussian-based inverse rendering methods often rely on ray tracing, leading to low efficiency. We introduce Surface Octahedral Probes (SOPs), which store lighting and occlusion information and allow efficient 3D querying via interpolation, avoiding expensive ray tracing. SOPs provide at least a 2x speedup in reconstruction and enable real-time shadow computation in Gaussian scenes. For lighting estimation, existing Gaussian-based inverse rendering methods struggle to model intricate light transport and often fail in complex scenes, while learning-based methods predict lighting from a single image and are viewpoint-sensitive. We observe that 3D object-scene composition primarily concerns the object's appearance and nearby shadows. Thus, we simplify the challenging task of full scene lighting estimation by focusing on the environment lighting at the object's placement. Specifically, we capture a 360 degrees reconstructed radiance field of the scene at the location and fine-tune a diffusion model to complete the lighting. Building on these advances, we propose ComGS, a novel 3D object-scene composition framework. Our method achieves high-quality, real-time rendering at around 28 FPS, produces visually harmonious results with vivid shadows, and requires only 36 seconds for editing. Code and dataset are available at https://nju-3dv.github.io/projects/ComGS/.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025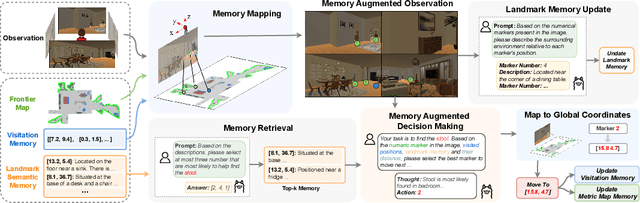
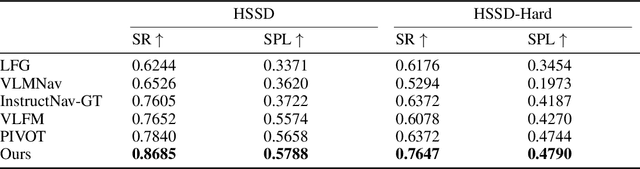
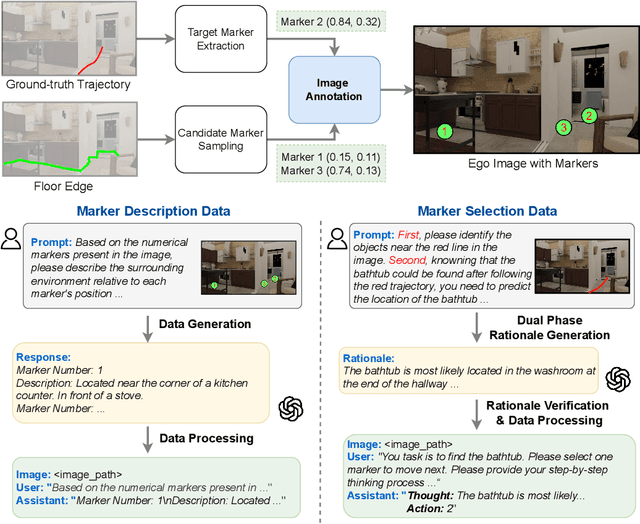

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
OmniBooth: Learning Latent Control for Image Synthesis with Multi-modal Instruction
Oct 07, 2024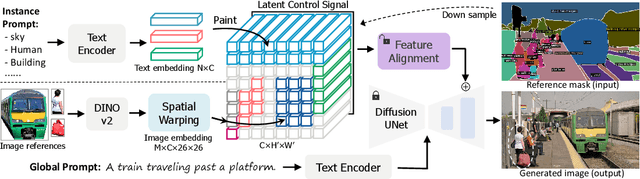
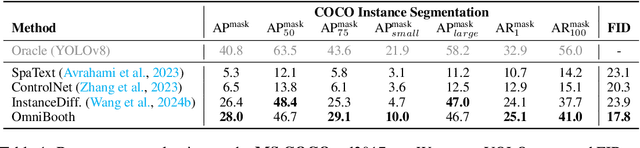
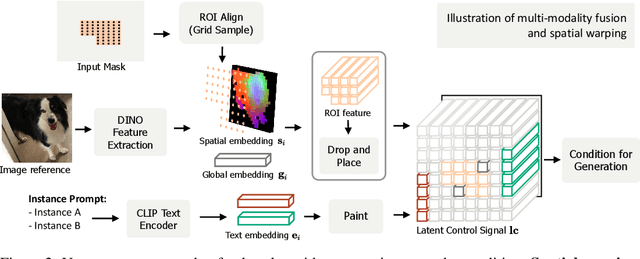
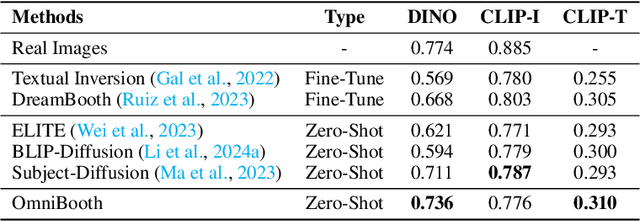
We present OmniBooth, an image generation framework that enables spatial control with instance-level multi-modal customization. For all instances, the multimodal instruction can be described through text prompts or image references. Given a set of user-defined masks and associated text or image guidance, our objective is to generate an image, where multiple objects are positioned at specified coordinates and their attributes are precisely aligned with the corresponding guidance. This approach significantly expands the scope of text-to-image generation, and elevates it to a more versatile and practical dimension in controllability. In this paper, our core contribution lies in the proposed latent control signals, a high-dimensional spatial feature that provides a unified representation to integrate the spatial, textual, and image conditions seamlessly. The text condition extends ControlNet to provide instance-level open-vocabulary generation. The image condition further enables fine-grained control with personalized identity. In practice, our method empowers users with more flexibility in controllable generation, as users can choose multi-modal conditions from text or images as needed. Furthermore, thorough experiments demonstrate our enhanced performance in image synthesis fidelity and alignment across different tasks and datasets. Project page: https://len-li.github.io/omnibooth-web/
DisEnvisioner: Disentangled and Enriched Visual Prompt for Customized Image Generation
Oct 02, 2024In the realm of image generation, creating customized images from visual prompt with additional textual instruction emerges as a promising endeavor. However, existing methods, both tuning-based and tuning-free, struggle with interpreting the subject-essential attributes from the visual prompt. This leads to subject-irrelevant attributes infiltrating the generation process, ultimately compromising the personalization quality in both editability and ID preservation. In this paper, we present DisEnvisioner, a novel approach for effectively extracting and enriching the subject-essential features while filtering out -irrelevant information, enabling exceptional customization performance, in a tuning-free manner and using only a single image. Specifically, the feature of the subject and other irrelevant components are effectively separated into distinctive visual tokens, enabling a much more accurate customization. Aiming to further improving the ID consistency, we enrich the disentangled features, sculpting them into more granular representations. Experiments demonstrate the superiority of our approach over existing methods in instruction response (editability), ID consistency, inference speed, and the overall image quality, highlighting the effectiveness and efficiency of DisEnvisioner. Project page: https://disenvisioner.github.io/.
Efficient Depth-Guided Urban View Synthesis
Jul 17, 2024



Recent advances in implicit scene representation enable high-fidelity street view novel view synthesis. However, existing methods optimize a neural radiance field for each scene, relying heavily on dense training images and extensive computation resources. To mitigate this shortcoming, we introduce a new method called Efficient Depth-Guided Urban View Synthesis (EDUS) for fast feed-forward inference and efficient per-scene fine-tuning. Different from prior generalizable methods that infer geometry based on feature matching, EDUS leverages noisy predicted geometric priors as guidance to enable generalizable urban view synthesis from sparse input images. The geometric priors allow us to apply our generalizable model directly in the 3D space, gaining robustness across various sparsity levels. Through comprehensive experiments on the KITTI-360 and Waymo datasets, we demonstrate promising generalization abilities on novel street scenes. Moreover, our results indicate that EDUS achieves state-of-the-art performance in sparse view settings when combined with fast test-time optimization.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024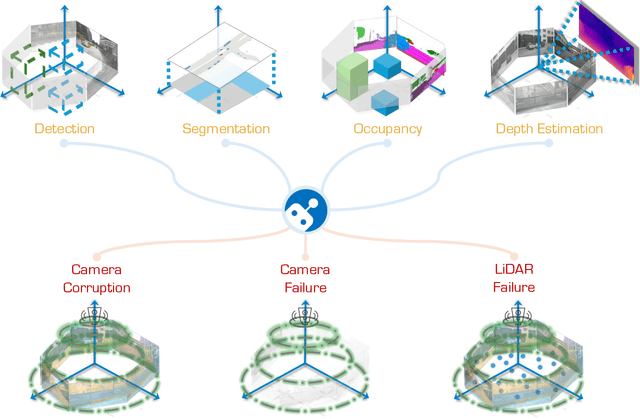


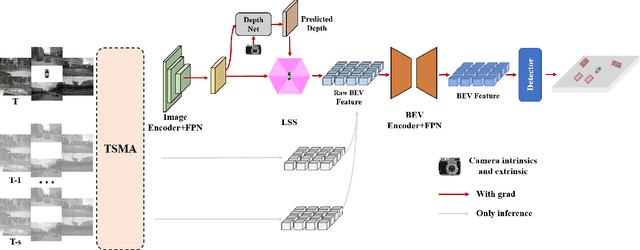
In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
Neural Radiance Fields with Torch Units
Apr 03, 2024



Neural Radiance Fields (NeRF) give rise to learning-based 3D reconstruction methods widely used in industrial applications. Although prevalent methods achieve considerable improvements in small-scale scenes, accomplishing reconstruction in complex and large-scale scenes is still challenging. First, the background in complex scenes shows a large variance among different views. Second, the current inference pattern, $i.e.$, a pixel only relies on an individual camera ray, fails to capture contextual information. To solve these problems, we propose to enlarge the ray perception field and build up the sample points interactions. In this paper, we design a novel inference pattern that encourages a single camera ray possessing more contextual information, and models the relationship among sample points on each camera ray. To hold contextual information,a camera ray in our proposed method can render a patch of pixels simultaneously. Moreover, we replace the MLP in neural radiance field models with distance-aware convolutions to enhance the feature propagation among sample points from the same camera ray. To summarize, as a torchlight, a ray in our proposed method achieves rendering a patch of image. Thus, we call the proposed method, Torch-NeRF. Extensive experiments on KITTI-360 and LLFF show that the Torch-NeRF exhibits excellent performance.
HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting
Mar 19, 2024



Holistic understanding of urban scenes based on RGB images is a challenging yet important problem. It encompasses understanding both the geometry and appearance to enable novel view synthesis, parsing semantic labels, and tracking moving objects. Despite considerable progress, existing approaches often focus on specific aspects of this task and require additional inputs such as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic urban scene understanding. Our main idea involves the joint optimization of geometry, appearance, semantics, and motion using a combination of static and dynamic 3D Gaussians, where moving object poses are regularized via physical constraints. Our approach offers the ability to render new viewpoints in real-time, yielding 2D and 3D semantic information with high accuracy, and reconstruct dynamic scenes, even in scenarios where 3D bounding box detection are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2 demonstrate the effectiveness of our approach.