 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deepfake Detection with RL Enhanced Self-Blended Images
Jan 22, 2026Most prior deepfake detection methods lack explainable outputs. With the growing interest in multimodal large language models (MLLMs), researchers have started exploring their use in interpretable deepfake detection. However, a major obstacle in applying MLLMs to this task is the scarcity of high-quality datasets with detailed forgery attribution annotations, as textual annotation is both costly and challenging - particularly for high-fidelity forged images or videos. Moreover, multiple studies have shown that reinforcement learning (RL) can substantially enhance performance in visual tasks, especially in improving cross-domain generalization. To facilitate the adoption of mainstream MLLM frameworks in deepfake detection with reduced annotation cost, and to investigate the potential of RL in this context, we propose an automated Chain-of-Thought (CoT) data generation framework based on Self-Blended Images, along with an RL-enhanced deepfake detection framework. Extensive experiments validate the effectiveness of our CoT data construction pipeline, tailored reward mechanism, and feedback-driven synthetic data generation approach. Our method achieves performance competitive with state-of-the-art (SOTA) approaches across multiple cross-dataset benchmarks. Implementation details are available at https://github.com/deon1219/rlsbi.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025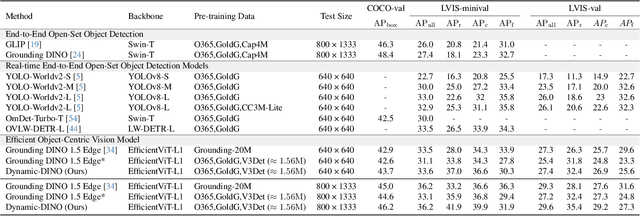
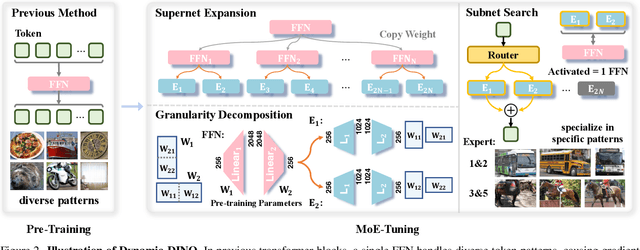

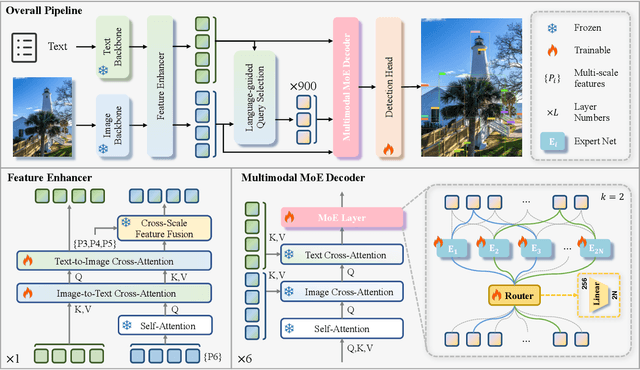
The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
Neural Radiance Fields with Torch Units
Apr 03, 2024



Neural Radiance Fields (NeRF) give rise to learning-based 3D reconstruction methods widely used in industrial applications. Although prevalent methods achieve considerable improvements in small-scale scenes, accomplishing reconstruction in complex and large-scale scenes is still challenging. First, the background in complex scenes shows a large variance among different views. Second, the current inference pattern, $i.e.$, a pixel only relies on an individual camera ray, fails to capture contextual information. To solve these problems, we propose to enlarge the ray perception field and build up the sample points interactions. In this paper, we design a novel inference pattern that encourages a single camera ray possessing more contextual information, and models the relationship among sample points on each camera ray. To hold contextual information,a camera ray in our proposed method can render a patch of pixels simultaneously. Moreover, we replace the MLP in neural radiance field models with distance-aware convolutions to enhance the feature propagation among sample points from the same camera ray. To summarize, as a torchlight, a ray in our proposed method achieves rendering a patch of image. Thus, we call the proposed method, Torch-NeRF. Extensive experiments on KITTI-360 and LLFF show that the Torch-NeRF exhibits excellent performance.