 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Deepfake Detection with RL Enhanced Self-Blended Images
Jan 22, 2026Most prior deepfake detection methods lack explainable outputs. With the growing interest in multimodal large language models (MLLMs), researchers have started exploring their use in interpretable deepfake detection. However, a major obstacle in applying MLLMs to this task is the scarcity of high-quality datasets with detailed forgery attribution annotations, as textual annotation is both costly and challenging - particularly for high-fidelity forged images or videos. Moreover, multiple studies have shown that reinforcement learning (RL) can substantially enhance performance in visual tasks, especially in improving cross-domain generalization. To facilitate the adoption of mainstream MLLM frameworks in deepfake detection with reduced annotation cost, and to investigate the potential of RL in this context, we propose an automated Chain-of-Thought (CoT) data generation framework based on Self-Blended Images, along with an RL-enhanced deepfake detection framework. Extensive experiments validate the effectiveness of our CoT data construction pipeline, tailored reward mechanism, and feedback-driven synthetic data generation approach. Our method achieves performance competitive with state-of-the-art (SOTA) approaches across multiple cross-dataset benchmarks. Implementation details are available at https://github.com/deon1219/rlsbi.
Crack-EdgeSAM Self-Prompting Crack Segmentation System for Edge Devices
Dec 10, 2024Structural health monitoring (SHM) is essential for the early detection of infrastructure defects, such as cracks in concrete bridge pier. but often faces challenges in efficiency and accuracy in complex environments. Although the Segment Anything Model (SAM) achieves excellent segmentation performance, its computational demands limit its suitability for real-time applications on edge devices. To address these challenges, this paper proposes Crack-EdgeSAM, a self-prompting crack segmentation system that integrates YOLOv8 for generating prompt boxes and a fine-tuned EdgeSAM model for crack segmentation. To ensure computational efficiency, the method employs ConvLoRA, a Parameter-Efficient Fine-Tuning (PEFT) technique, along with DiceFocalLoss to fine-tune the EdgeSAM model. Our experimental results on public datasets and the climbing robot automatic inspections demonstrate that the system achieves high segmentation accuracy and significantly enhanced inference speed compared to the most recent methods. Notably, the system processes 1024 x 1024 pixels images at 46 FPS on our PC and 8 FPS on Jetson Orin Nano.
Orthogonal Constrained Minimization with Tensor $\ell_{2,p}$ Regularization for HSI Denoising and Destriping
Jul 04, 2024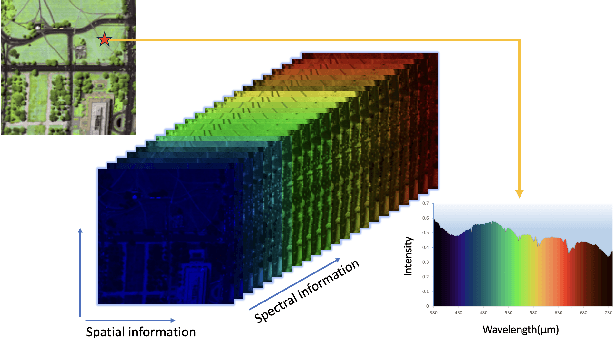
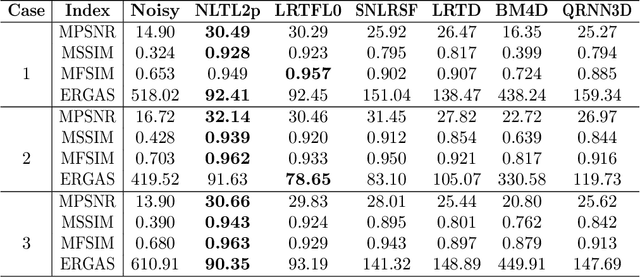
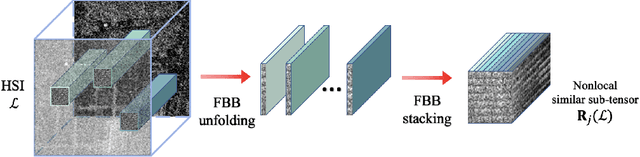
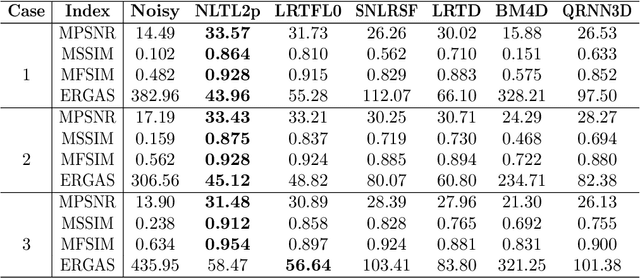
Hyperspectral images (HSIs) are often contaminated by a mixture of noises such as Gaussian noise, dead lines, stripes, and so on. In this paper, we propose a novel approach for HSI denoising and destriping, called NLTL2p, which consists of an orthogonal constrained minimization model and an iterative algorithm with convergence guarantees. The model of the proposed NLTL2p approach is built based on a new sparsity-enhanced Nonlocal Low-rank Tensor regularization and a tensor $\ell_{2,p}$ norm with $p\in(0,1)$. The low-rank constraints for HSI denoising utilize the spatial nonlocal self-similarity and spectral correlation of HSIs and are formulated based on independent higher-order singular value decomposition with sparsity enhancement on its core tensor to prompt more low-rankness. The tensor $\ell_{2,p}$ norm for HSI destriping is extended from the matrix $\ell_{2,p}$ norm. A proximal block coordinate descent algorithm is proposed in the NLTL2p approach to solve the resulting nonconvex nonsmooth minimization with orthogonal constraints. We show any accumulation point of the sequence generated by the proposed algorithm converges to a first-order stationary point, which is defined using three equalities of substationarity, symmetry, and feasibility for orthogonal constraints. In the numerical experiments, we compare the proposed method with state-of-the-art methods including a deep learning based method, and test the methods on both simulated and real HSI datasets. Our proposed NLTL2p method demonstrates outperformance in terms of metrics such as mean peak signal-to-noise ratio as well as visual quality.
Multiple Domain Experts Collaborative Learning: Multi-Source Domain Generalization For Person Re-Identification
May 26, 2021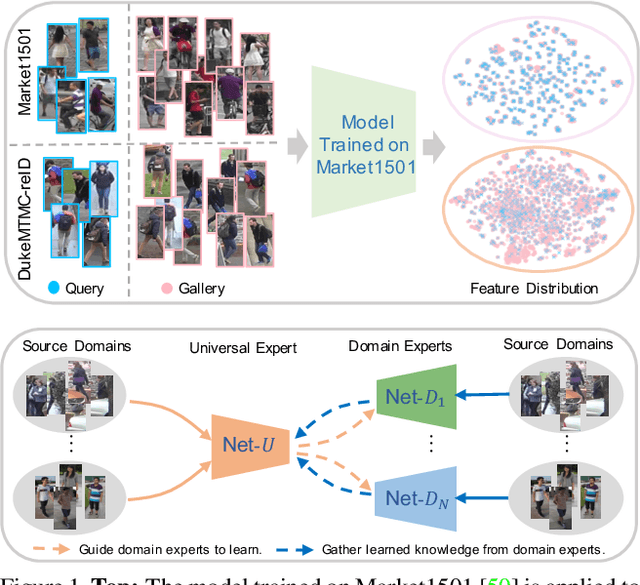
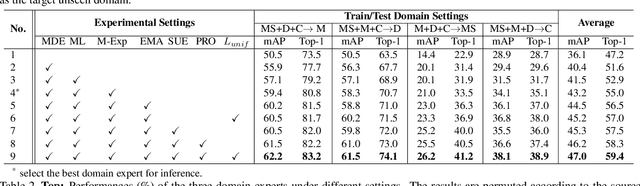
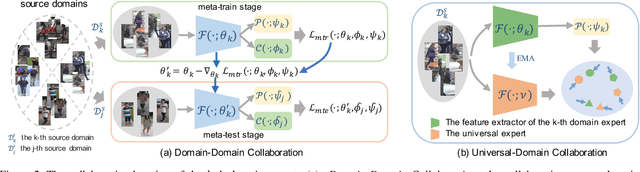
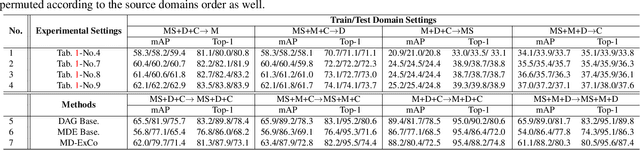
Recent years have witnessed significant progress in person re-identification (ReID). However, current ReID approaches suffer from considerable performance degradation when the test target domains exhibit different characteristics from the training ones, known as the domain shift problem. To make ReID more practical and generalizable, we formulate person re-identification as a Domain Generalization (DG) problem and propose a novel training framework, named Multiple Domain Experts Collaborative Learning (MD-ExCo). Specifically, the MD-ExCo consists of a universal expert and several domain experts. Each domain expert focuses on learning from a specific domain, and periodically communicates with other domain experts to regulate its learning strategy in the meta-learning manner to avoid overfitting. Besides, the universal expert gathers knowledge from the domain experts, and also provides supervision to them as feedback. Extensive experiments on DG-ReID benchmarks show that our MD-ExCo outperforms the state-of-the-art methods by a large margin, showing its ability to improve the generalization capability of the ReID models.
Layerwise Optimization by Gradient Decomposition for Continual Learning
May 17, 2021
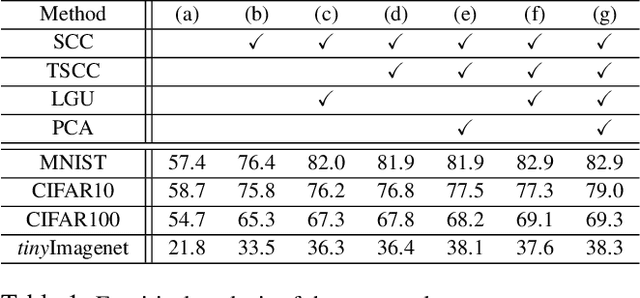


Deep neural networks achieve state-of-the-art and sometimes super-human performance across various domains. However, when learning tasks sequentially, the networks easily forget the knowledge of previous tasks, known as "catastrophic forgetting". To achieve the consistencies between the old tasks and the new task, one effective solution is to modify the gradient for update. Previous methods enforce independent gradient constraints for different tasks, while we consider these gradients contain complex information, and propose to leverage inter-task information by gradient decomposition. In particular, the gradient of an old task is decomposed into a part shared by all old tasks and a part specific to that task. The gradient for update should be close to the gradient of the new task, consistent with the gradients shared by all old tasks, and orthogonal to the space spanned by the gradients specific to the old tasks. In this way, our approach encourages common knowledge consolidation without impairing the task-specific knowledge. Furthermore, the optimization is performed for the gradients of each layer separately rather than the concatenation of all gradients as in previous works. This effectively avoids the influence of the magnitude variation of the gradients in different layers. Extensive experiments validate the effectiveness of both gradient-decomposed optimization and layer-wise updates. Our proposed method achieves state-of-the-art results on various benchmarks of continual learning.
Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
May 16, 2021
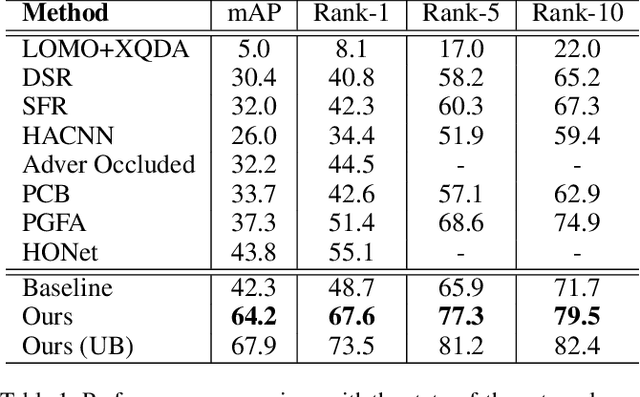
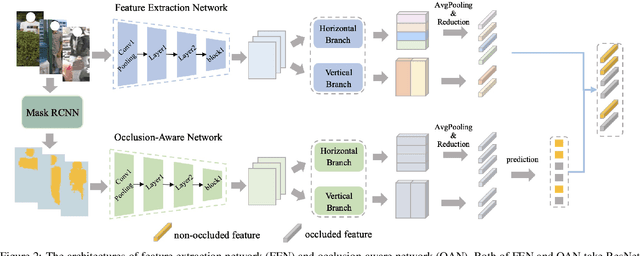
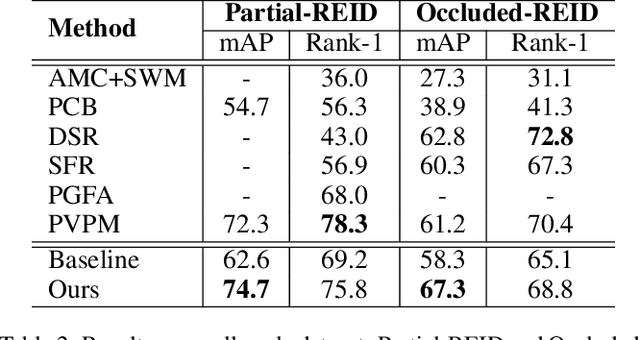
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance. To tackle this challenge, we propose to reconstruct the feature representation of occluded parts by fully exploiting the information of its neighborhood in a gallery image set. Specifically, we first introduce a visible part-based feature by body mask for each person image. Then we identify its neighboring samples using the visible features and reconstruct the representation of the full body by an outlier-removable graph neural network with all the neighboring samples as input. Extensive experiments show that the proposed approach obtains significant improvements. In the large-scale Occluded-DukeMTMC benchmark, our approach achieves 64.2% mAP and 67.6% rank-1 accuracy which outperforms the state-of-the-art approaches by large margins, i.e.,20.4% and 12.5%, respectively, indicating the effectiveness of our method on occluded Re-ID problem.
Complementary Relation Contrastive Distillation
Mar 29, 2021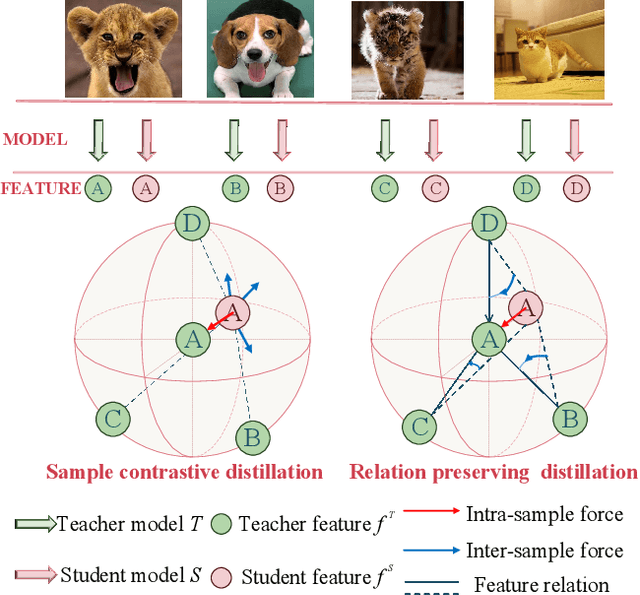
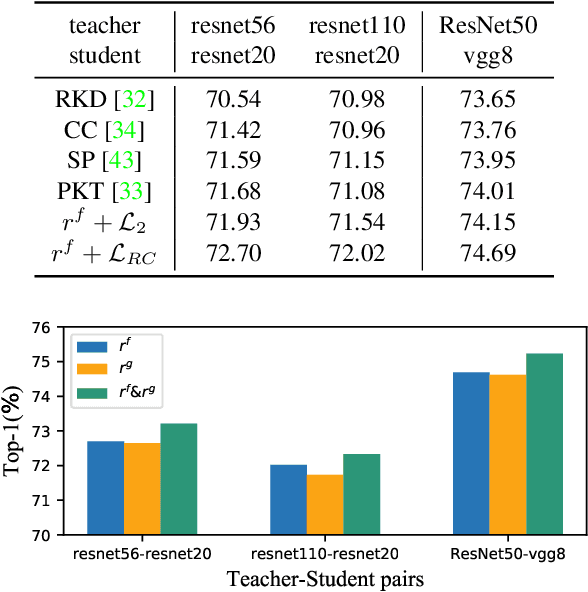
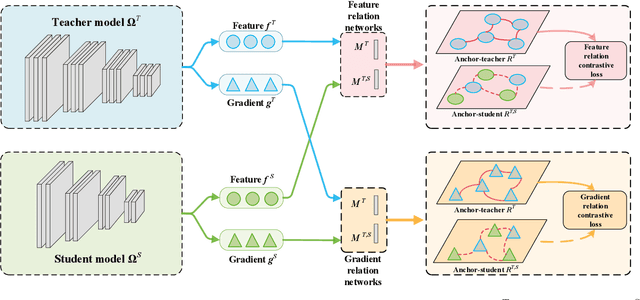

Knowledge distillation aims to transfer representation ability from a teacher model to a student model. Previous approaches focus on either individual representation distillation or inter-sample similarity preservation. While we argue that the inter-sample relation conveys abundant information and needs to be distilled in a more effective way. In this paper, we propose a novel knowledge distillation method, namely Complementary Relation Contrastive Distillation (CRCD), to transfer the structural knowledge from the teacher to the student. Specifically, we estimate the mutual relation in an anchor-based way and distill the anchor-student relation under the supervision of its corresponding anchor-teacher relation. To make it more robust, mutual relations are modeled by two complementary elements: the feature and its gradient. Furthermore, the low bound of mutual information between the anchor-teacher relation distribution and the anchor-student relation distribution is maximized via relation contrastive loss, which can distill both the sample representation and the inter-sample relations. Experiments on different benchmarks demonstrate the effectiveness of our proposed CRCD.
Improved Mutual Mean-Teaching for Unsupervised Domain Adaptive Re-ID
Aug 24, 2020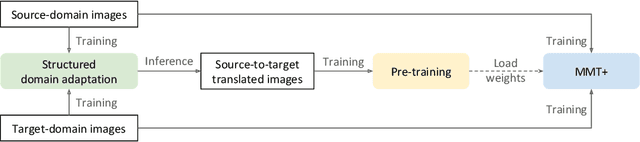



In this technical report, we present our submission to the VisDA Challenge in ECCV 2020 and we achieved one of the top-performing results on the leaderboard. Our solution is based on Structured Domain Adaptation (SDA) and Mutual Mean-Teaching (MMT) frameworks. SDA, a domain-translation-based framework, focuses on carefully translating the source-domain images to the target domain. MMT, a pseudo-label-based framework, focuses on conducting pseudo label refinery with robust soft labels. Specifically, there are three main steps in our training pipeline. (i) We adopt SDA to generate source-to-target translated images, and (ii) such images serve as informative training samples to pre-train the network. (iii) The pre-trained network is further fine-tuned by MMT on the target domain. Note that we design an improved MMT (dubbed MMT+) to further mitigate the label noise by modeling inter-sample relations across two domains and maintaining the instance discrimination. Our proposed method achieved 74.78% accuracies in terms of mAP, ranked the 2nd place out of 153 teams.
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
May 16, 2020



Recent years have witnessed great progress in person re-identification (re-id). Several academic benchmarks such as Market1501, CUHK03 and DukeMTMC play important roles to promote the re-id research. To our best knowledge, all the existing benchmarks assume the same person will have the same clothes. While in real-world scenarios, it is very often for a person to change clothes. To address the clothes changing person re-id problem, we construct a novel large-scale re-id benchmark named ClOthes ChAnging Person Set (COCAS), which provides multiple images of the same identity with different clothes. COCAS totally contains 62,382 body images from 5,266 persons. Based on COCAS, we introduce a new person re-id setting for clothes changing problem, where the query includes both a clothes template and a person image taking another clothes. Moreover, we propose a two-branch network named Biometric-Clothes Network (BC-Net) which can effectively integrate biometric and clothes feature for re-id under our setting. Experiments show that it is feasible for clothes changing re-id with clothes templates.