 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Residuals
Mar 16, 2026Residual connections with PreNorm are standard in modern LLMs, yet they accumulate all layer outputs with fixed unit weights. This uniform aggregation causes uncontrolled hidden-state growth with depth, progressively diluting each layer's contribution. We propose Attention Residuals (AttnRes), which replaces this fixed accumulation with softmax attention over preceding layer outputs, allowing each layer to selectively aggregate earlier representations with learned, input-dependent weights. To address the memory and communication overhead of attending over all preceding layer outputs for large-scale model training, we introduce Block AttnRes, which partitions layers into blocks and attends over block-level representations, reducing the memory footprint while preserving most of the gains of full AttnRes. Combined with cache-based pipeline communication and a two-phase computation strategy, Block AttnRes becomes a practical drop-in replacement for standard residual connections with minimal overhead. Scaling law experiments confirm that the improvement is consistent across model sizes, and ablations validate the benefit of content-dependent depth-wise selection. We further integrate AttnRes into the Kimi Linear architecture (48B total / 3B activated parameters) and pre-train on 1.4T tokens, where AttnRes mitigates PreNorm dilution, yielding more uniform output magnitudes and gradient distribution across depth, and improves downstream performance across all evaluated tasks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Enhancing the Outcome Reward-based RL Training of MLLMs with Self-Consistency Sampling
Nov 13, 2025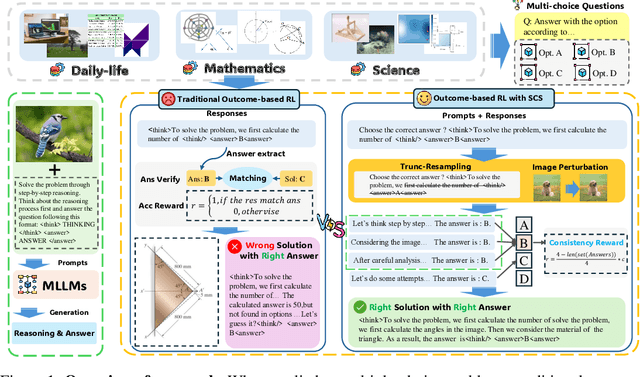
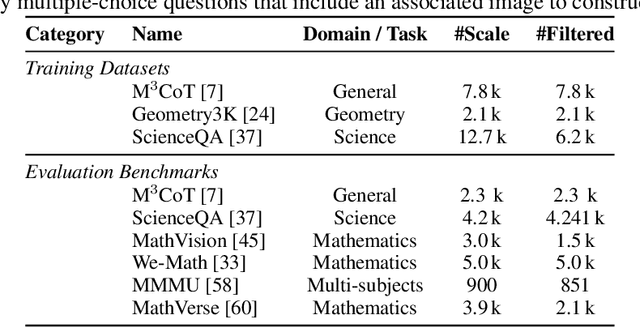
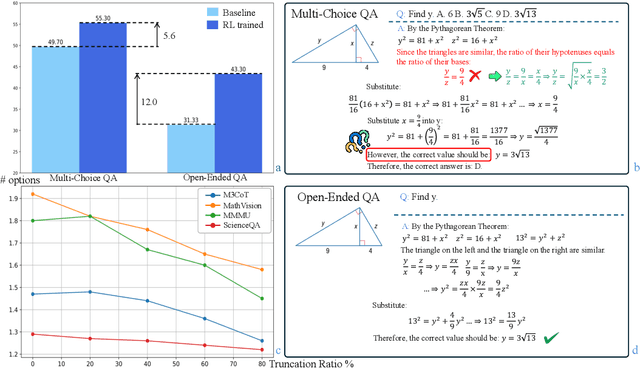
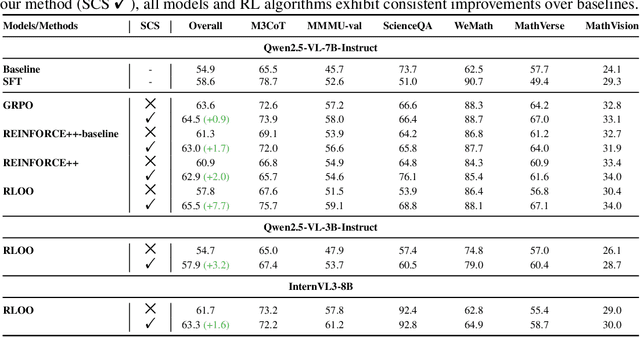
Outcome-reward reinforcement learning (RL) is a common and increasingly significant way to refine the step-by-step reasoning of multimodal large language models (MLLMs). In the multiple-choice setting - a dominant format for multimodal reasoning benchmarks - the paradigm faces a significant yet often overlooked obstacle: unfaithful trajectories that guess the correct option after a faulty chain of thought receive the same reward as genuine reasoning, which is a flaw that cannot be ignored. We propose Self-Consistency Sampling (SCS) to correct this issue. For each question, SCS (i) introduces small visual perturbations and (ii) performs repeated truncation and resampling of an initial trajectory; agreement among the resulting trajectories yields a differentiable consistency score that down-weights unreliable traces during policy updates. Based on Qwen2.5-VL-7B-Instruct, plugging SCS into RLOO, GRPO, and REINFORCE++ series improves accuracy by up to 7.7 percentage points on six multimodal benchmarks with negligible extra computation. SCS also yields notable gains on both Qwen2.5-VL-3B-Instruct and InternVL3-8B, offering a simple, general remedy for outcome-reward RL in MLLMs.
ZeroGUI: Automating Online GUI Learning at Zero Human Cost
May 29, 2025



The rapid advancement of large Vision-Language Models (VLMs) has propelled the development of pure-vision-based GUI Agents, capable of perceiving and operating Graphical User Interfaces (GUI) to autonomously fulfill user instructions. However, existing approaches usually adopt an offline learning framework, which faces two core limitations: (1) heavy reliance on high-quality manual annotations for element grounding and action supervision, and (2) limited adaptability to dynamic and interactive environments. To address these limitations, we propose ZeroGUI, a scalable, online learning framework for automating GUI Agent training at Zero human cost. Specifically, ZeroGUI integrates (i) VLM-based automatic task generation to produce diverse training goals from the current environment state, (ii) VLM-based automatic reward estimation to assess task success without hand-crafted evaluation functions, and (iii) two-stage online reinforcement learning to continuously interact with and learn from GUI environments. Experiments on two advanced GUI Agents (UI-TARS and Aguvis) demonstrate that ZeroGUI significantly boosts performance across OSWorld and AndroidLab environments. The code is available at https://github.com/OpenGVLab/ZeroGUI.
VisuLogic: A Benchmark for Evaluating Visual Reasoning in Multi-modal Large Language Models
Apr 21, 2025



Visual reasoning is a core component of human intelligence and a critical capability for advanced multimodal models. Yet current reasoning evaluations of multimodal large language models (MLLMs) often rely on text descriptions and allow language-based reasoning shortcuts, failing to measure genuine vision-centric reasoning. To address this, we introduce VisuLogic: a benchmark of 1,000 human-verified problems across six categories (e.g., quantitative shifts, spatial relations, attribute comparisons). These various types of questions can be evaluated to assess the visual reasoning capabilities of MLLMs from multiple perspectives. We evaluate leading MLLMs on this benchmark and analyze their results to identify common failure modes. Most models score below 30% accuracy-only slightly above the 25% random baseline and far below the 51.4% achieved by humans-revealing significant gaps in visual reasoning. Furthermore, we provide a supplementary training dataset and a reinforcement-learning baseline to support further progress.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning
Mar 13, 2025



We introduce VisualPRM, an advanced multimodal Process Reward Model (PRM) with 8B parameters, which improves the reasoning abilities of existing Multimodal Large Language Models (MLLMs) across different model scales and families with Best-of-N (BoN) evaluation strategies. Specifically, our model improves the reasoning performance of three types of MLLMs and four different model scales. Even when applied to the highly capable InternVL2.5-78B, it achieves a 5.9-point improvement across seven multimodal reasoning benchmarks. Experimental results show that our model exhibits superior performance compared to Outcome Reward Models and Self-Consistency during BoN evaluation. To facilitate the training of multimodal PRMs, we construct a multimodal process supervision dataset VisualPRM400K using an automated data pipeline. For the evaluation of multimodal PRMs, we propose VisualProcessBench, a benchmark with human-annotated step-wise correctness labels, to measure the abilities of PRMs to detect erroneous steps in multimodal reasoning tasks. We hope that our work can inspire more future research and contribute to the development of MLLMs. Our model, data, and benchmark are released in https://internvl.github.io/blog/2025-03-13-VisualPRM/.
SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vision Experts and Token Folding
Dec 12, 2024



The remarkable success of Large Language Models (LLMs) has extended to the multimodal domain, achieving outstanding performance in image understanding and generation. Recent efforts to develop unified Multimodal Large Language Models (MLLMs) that integrate these capabilities have shown promising results. However, existing approaches often involve complex designs in model architecture or training pipeline, increasing the difficulty of model training and scaling. In this paper, we propose SynerGen-VL, a simple yet powerful encoder-free MLLM capable of both image understanding and generation. To address challenges identified in existing encoder-free unified MLLMs, we introduce the token folding mechanism and the vision-expert-based progressive alignment pretraining strategy, which effectively support high-resolution image understanding while reducing training complexity. After being trained on large-scale mixed image-text data with a unified next-token prediction objective, SynerGen-VL achieves or surpasses the performance of existing encoder-free unified MLLMs with comparable or smaller parameter sizes, and narrows the gap with task-specific state-of-the-art models, highlighting a promising path toward future unified MLLMs. Our code and models shall be released.
V2PE: Improving Multimodal Long-Context Capability of Vision-Language Models with Variable Visual Position Encoding
Dec 12, 2024



Vision-Language Models (VLMs) have shown promising capabilities in handling various multimodal tasks, yet they struggle in long-context scenarios, particularly in tasks involving videos, high-resolution images, or lengthy image-text documents. In our work, we first conduct an empirical analysis of the long-context capabilities of VLMs using our augmented long-context multimodal datasets. Our findings reveal that directly applying the positional encoding mechanism used for textual tokens to visual tokens is suboptimal, and VLM performance degrades sharply when the position encoding exceeds the model's context window. To address this, we propose Variable Visual Position Encoding (V2PE), a novel positional encoding approach that employs variable and smaller increments for visual tokens, enabling more efficient management of long multimodal sequences. Our experiments demonstrate the effectiveness of V2PE to enhances VLMs' ability to effectively understand and reason over long multimodal contexts. We further integrate V2PE with our augmented long-context multimodal datasets to fine-tune the open-source VLM, InternVL2. The fine-tuned model achieves strong performance on both standard and long-context multimodal tasks. Notably, when the sequence length of the training dataset is increased to 256K tokens, the model is capable of processing multimodal sequences up to 1M tokens, highlighting its potential for real-world long-context applications.