 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Exploring the Limit of World Knowledge Capabilities for Unified Mulitmodal Models
Jan 02, 2026The capability of Unified Multimodal Models (UMMs) to apply world knowledge across diverse tasks remains a critical, unresolved challenge. Existing benchmarks fall short, offering only siloed, single-task evaluations with limited diagnostic power. To bridge this gap, we propose AEGIS (\emph{i.e.}, \textbf{A}ssessing \textbf{E}diting, \textbf{G}eneration, \textbf{I}nterpretation-Understanding for \textbf{S}uper-intelligence), a comprehensive multi-task benchmark covering visual understanding, generation, editing, and interleaved generation. AEGIS comprises 1,050 challenging, manually-annotated questions spanning 21 topics (including STEM, humanities, daily life, etc.) and 6 reasoning types. To concretely evaluate the performance of UMMs in world knowledge scope without ambiguous metrics, we further propose Deterministic Checklist-based Evaluation (DCE), a protocol that replaces ambiguous prompt-based scoring with atomic ``Y/N'' judgments, to enhance evaluation reliability. Our extensive experiments reveal that most UMMs exhibit severe world knowledge deficits and that performance degrades significantly with complex reasoning. Additionally, simple plug-in reasoning modules can partially mitigate these vulnerabilities, highlighting a promising direction for future research. These results highlight the importance of world-knowledge-based reasoning as a critical frontier for UMMs.
V2PE: Improving Multimodal Long-Context Capability of Vision-Language Models with Variable Visual Position Encoding
Dec 12, 2024



Vision-Language Models (VLMs) have shown promising capabilities in handling various multimodal tasks, yet they struggle in long-context scenarios, particularly in tasks involving videos, high-resolution images, or lengthy image-text documents. In our work, we first conduct an empirical analysis of the long-context capabilities of VLMs using our augmented long-context multimodal datasets. Our findings reveal that directly applying the positional encoding mechanism used for textual tokens to visual tokens is suboptimal, and VLM performance degrades sharply when the position encoding exceeds the model's context window. To address this, we propose Variable Visual Position Encoding (V2PE), a novel positional encoding approach that employs variable and smaller increments for visual tokens, enabling more efficient management of long multimodal sequences. Our experiments demonstrate the effectiveness of V2PE to enhances VLMs' ability to effectively understand and reason over long multimodal contexts. We further integrate V2PE with our augmented long-context multimodal datasets to fine-tune the open-source VLM, InternVL2. The fine-tuned model achieves strong performance on both standard and long-context multimodal tasks. Notably, when the sequence length of the training dataset is increased to 256K tokens, the model is capable of processing multimodal sequences up to 1M tokens, highlighting its potential for real-world long-context applications.
VLG: General Video Recognition with Web Textual Knowledge
Dec 03, 2022Video recognition in an open and dynamic world is quite challenging, as we need to handle different settings such as close-set, long-tail, few-shot and open-set. By leveraging semantic knowledge from noisy text descriptions crawled from the Internet, we focus on the general video recognition (GVR) problem of solving different recognition tasks within a unified framework. The core contribution of this paper is twofold. First, we build a comprehensive video recognition benchmark of Kinetics-GVR, including four sub-task datasets to cover the mentioned settings. To facilitate the research of GVR, we propose to utilize external textual knowledge from the Internet and provide multi-source text descriptions for all action classes. Second, inspired by the flexibility of language representation, we present a unified visual-linguistic framework (VLG) to solve the problem of GVR by an effective two-stage training paradigm. Our VLG is first pre-trained on video and language datasets to learn a shared feature space, and then devises a flexible bi-modal attention head to collaborate high-level semantic concepts under different settings. Extensive results show that our VLG obtains the state-of-the-art performance under four settings. The superior performance demonstrates the effectiveness and generalization ability of our proposed framework. We hope our work makes a step towards the general video recognition and could serve as a baseline for future research. The code and models will be available at https://github.com/MCG-NJU/VLG.
OCSampler: Compressing Videos to One Clip with Single-step Sampling
Jan 12, 2022
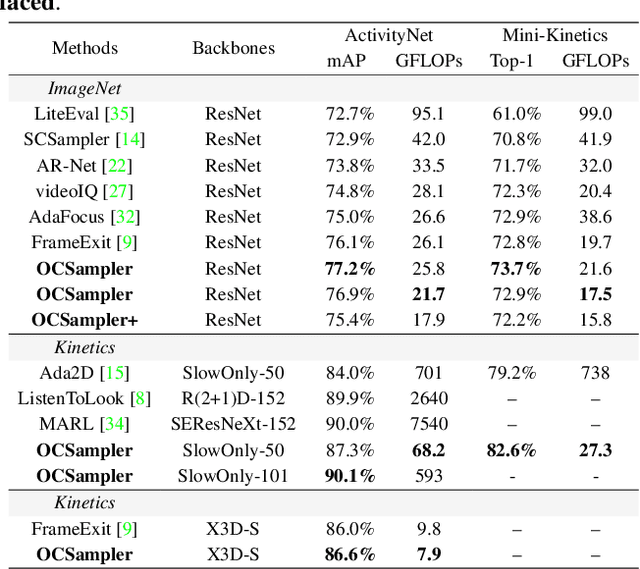
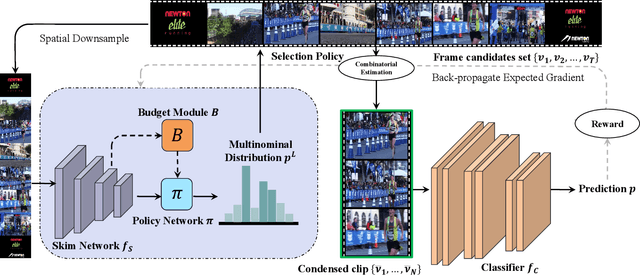
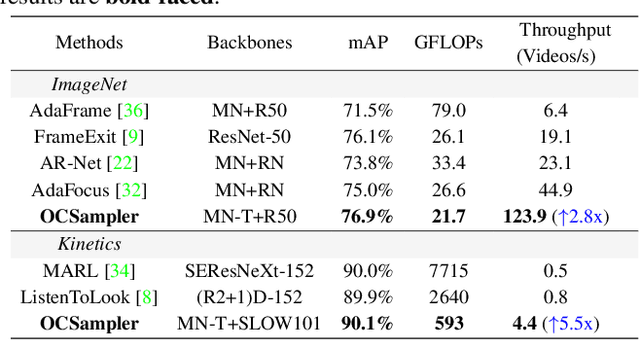
In this paper, we propose a framework named OCSampler to explore a compact yet effective video representation with one short clip for efficient video recognition. Recent works prefer to formulate frame sampling as a sequential decision task by selecting frames one by one according to their importance, while we present a new paradigm of learning instance-specific video condensation policies to select informative frames for representing the entire video only in a single step. Our basic motivation is that the efficient video recognition task lies in processing a whole sequence at once rather than picking up frames sequentially. Accordingly, these policies are derived from a light-weighted skim network together with a simple yet effective policy network within one step. Moreover, we extend the proposed method with a frame number budget, enabling the framework to produce correct predictions in high confidence with as few frames as possible. Experiments on four benchmarks, i.e., ActivityNet, Mini-Kinetics, FCVID, Mini-Sports1M, demonstrate the effectiveness of our OCSampler over previous methods in terms of accuracy, theoretical computational expense, actual inference speed. We also evaluate its generalization power across different classifiers, sampled frames, and search spaces. Especially, we achieve 76.9% mAP and 21.7 GFLOPs on ActivityNet with an impressive throughput: 123.9 Videos/s on a single TITAN Xp GPU.