 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAG-PT: Emission-Aware Gaussians and Path Tracing for Indoor Scene Reconstruction and Editing
Jan 30, 2026Recent reconstruction methods based on radiance field such as NeRF and 3DGS reproduce indoor scenes with high visual fidelity, but break down under scene editing due to baked illumination and the lack of explicit light transport. In contrast, physically based inverse rendering relies on mesh representations and path tracing, which enforce correct light transport but place strong requirements on geometric fidelity, becoming a practical bottleneck for real indoor scenes. In this work, we propose Emission-Aware Gaussians and Path Tracing (EAG-PT), aiming for physically based light transport with a unified 2D Gaussian representation. Our design is based on three cores: (1) using 2D Gaussians as a unified scene representation and transport-friendly geometry proxy that avoids reconstructed mesh, (2) explicitly separating emissive and non-emissive components during reconstruction for further scene editing, and (3) decoupling reconstruction from final rendering by using efficient single-bounce optimization and high-quality multi-bounce path tracing after scene editing. Experiments on synthetic and real indoor scenes show that EAG-PT produces more natural and physically consistent renders after editing than radiant scene reconstructions, while preserving finer geometric detail and avoiding mesh-induced artifacts compared to mesh-based inverse path tracing. These results suggest promising directions for future use in interior design, XR content creation, and embodied AI.
Timely Machine: Awareness of Time Makes Test-Time Scaling Agentic
Jan 23, 2026As large language models (LLMs) increasingly tackle complex reasoning tasks, test-time scaling has become critical for enhancing capabilities. However, in agentic scenarios with frequent tool calls, the traditional generation-length-based definition breaks down: tool latency decouples inference time from generation length. We propose Timely Machine, redefining test-time as wall-clock time, where models dynamically adjust strategies based on time budgets. We introduce Timely-Eval, a benchmark spanning high-frequency tool calls, low-frequency tool calls, and time-constrained reasoning. By varying tool latency, we find smaller models excel with fast feedback through more interactions, while larger models dominate high-latency settings via superior interaction quality. Moreover, existing models fail to adapt reasoning to time budgets. We propose Timely-RL to address this gap. After cold-start supervised fine-tuning, we use reinforcement learning to enhance temporal planning. Timely-RL improves time budget awareness and consistently boosts performance across Timely-Eval. We hope our work offers a new perspective on test-time scaling for the agentic era.
Mixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go
Jan 23, 2026Large language models (LLMs) have demonstrated exceptional performance in reasoning tasks such as mathematics and coding, matching or surpassing human capabilities. However, these impressive reasoning abilities face significant challenges in specialized domains. Taking Go as an example, although AlphaGo has established the high performance ceiling of AI systems in Go, mainstream LLMs still struggle to reach even beginner-level proficiency, let alone perform natural language reasoning. This performance gap between general-purpose LLMs and domain experts is significantly limiting the application of LLMs on a wider range of domain-specific tasks. In this work, we aim to bridge the divide between LLMs' general reasoning capabilities and expert knowledge in domain-specific tasks. We perform mixed fine-tuning with structured Go expertise and general long Chain-of-Thought (CoT) reasoning data as a cold start, followed by reinforcement learning to integrate expert knowledge in Go with general reasoning capabilities. Through this methodology, we present \textbf{LoGos}, a powerful LLM that not only maintains outstanding general reasoning abilities, but also conducts Go gameplay in natural language, demonstrating effective strategic reasoning and accurate next-move prediction. LoGos achieves performance comparable to human professional players, substantially surpassing all existing LLMs. Through this work, we aim to contribute insights on applying general LLM reasoning capabilities to specialized domains. We will release the first large-scale Go dataset for LLM training, the first LLM Go evaluation benchmark, and the first general LLM that reaches human professional-level performance in Go at: https://github.com/Entarochuan/LoGos.
TL-GRPO: Turn-Level RL for Reasoning-Guided Iterative Optimization
Jan 23, 2026Large language models have demonstrated strong reasoning capabilities in complex tasks through tool integration, which is typically framed as a Markov Decision Process and optimized with trajectory-level RL algorithms such as GRPO. However, a common class of reasoning tasks, iterative optimization, presents distinct challenges: the agent interacts with the same underlying environment state across turns, and the value of a trajectory is determined by the best turn-level reward rather than cumulative returns. Existing GRPO-based methods cannot perform fine-grained, turn-level optimization in such settings, while black-box optimization methods discard prior knowledge and reasoning capabilities. To address this gap, we propose Turn-Level GRPO (TL-GRPO), a lightweight RL algorithm that performs turn-level group sampling for fine-grained optimization. We evaluate TL-GRPO on analog circuit sizing (ACS), a challenging scientific optimization task requiring multiple simulations and domain expertise. Results show that TL-GRPO outperforms standard GRPO and Bayesian optimization methods across various specifications. Furthermore, our 30B model trained with TL-GRPO achieves state-of-the-art performance on ACS tasks under same simulation budget, demonstrating both strong generalization and practical utility.
SenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Dec 22, 2025Deep representations across modalities are inherently intertwined. In this paper, we systematically analyze the spectral characteristics of various semantic and pixel encoders. Interestingly, our study uncovers a highly inspiring and rarely explored correspondence between an encoder's feature spectrum and its functional role: semantic encoders primarily capture low-frequency components that encode abstract meaning, whereas pixel encoders additionally retain high-frequency information that conveys fine-grained detail. This heuristic finding offers a unifying perspective that ties encoder behavior to its underlying spectral structure. We define it as the Prism Hypothesis, where each data modality can be viewed as a projection of the natural world onto a shared feature spectrum, just like the prism. Building on this insight, we propose Unified Autoencoding (UAE), a model that harmonizes semantic structure and pixel details via an innovative frequency-band modulator, enabling their seamless coexistence. Extensive experiments on ImageNet and MS-COCO benchmarks validate that our UAE effectively unifies semantic abstraction and pixel-level fidelity into a single latent space with state-of-the-art performance.
End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
Dec 17, 2025
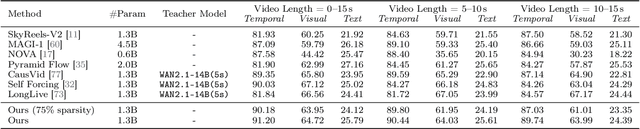
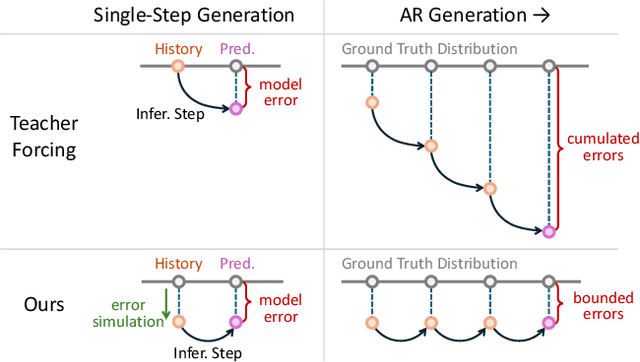

Autoregressive video diffusion models hold promise for world simulation but are vulnerable to exposure bias arising from the train-test mismatch. While recent works address this via post-training, they typically rely on a bidirectional teacher model or online discriminator. To achieve an end-to-end solution, we introduce Resampling Forcing, a teacher-free framework that enables training autoregressive video models from scratch and at scale. Central to our approach is a self-resampling scheme that simulates inference-time model errors on history frames during training. Conditioned on these degraded histories, a sparse causal mask enforces temporal causality while enabling parallel training with frame-level diffusion loss. To facilitate efficient long-horizon generation, we further introduce history routing, a parameter-free mechanism that dynamically retrieves the top-k most relevant history frames for each query. Experiments demonstrate that our approach achieves performance comparable to distillation-based baselines while exhibiting superior temporal consistency on longer videos owing to native-length training.
SS4D: Native 4D Generative Model via Structured Spacetime Latents
Dec 16, 2025
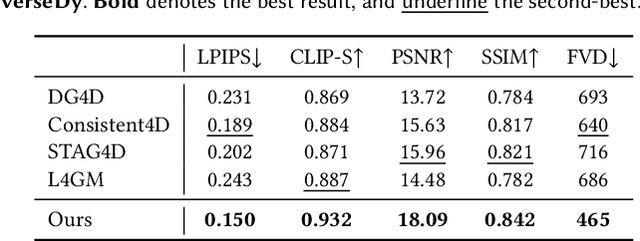
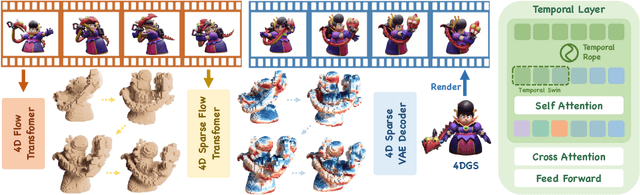
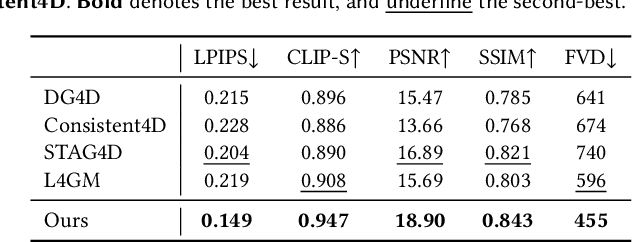
We present SS4D, a native 4D generative model that synthesizes dynamic 3D objects directly from monocular video. Unlike prior approaches that construct 4D representations by optimizing over 3D or video generative models, we train a generator directly on 4D data, achieving high fidelity, temporal coherence, and structural consistency. At the core of our method is a compressed set of structured spacetime latents. Specifically, (1) To address the scarcity of 4D training data, we build on a pre-trained single-image-to-3D model, preserving strong spatial consistency. (2) Temporal consistency is enforced by introducing dedicated temporal layers that reason across frames. (3) To support efficient training and inference over long video sequences, we compress the latent sequence along the temporal axis using factorized 4D convolutions and temporal downsampling blocks. In addition, we employ a carefully designed training strategy to enhance robustness against occlusion
* ToG(Siggraph Asia 2025)
TalkVerse: Democratizing Minute-Long Audio-Driven Video Generation
Dec 16, 2025We introduce TalkVerse, a large-scale, open corpus for single-person, audio-driven talking video generation designed to enable fair, reproducible comparison across methods. While current state-of-the-art systems rely on closed data or compute-heavy models, TalkVerse offers 2.3 million high-resolution (720p/1080p) audio-video synchronized clips totaling 6.3k hours. These are curated from over 60k hours of video via a transparent pipeline that includes scene-cut detection, aesthetic assessment, strict audio-visual synchronization checks, and comprehensive annotations including 2D skeletons and structured visual/audio-style captions. Leveraging TalkVerse, we present a reproducible 5B DiT baseline built on Wan2.2-5B. By utilizing a video VAE with a high downsampling ratio and a sliding window mechanism with motion-frame context, our model achieves minute-long generation with low drift. It delivers comparable lip-sync and visual quality to the 14B Wan-S2V model but with 10$\times$ lower inference cost. To enhance storytelling in long videos, we integrate an MLLM director to rewrite prompts based on audio and visual cues. Furthermore, our model supports zero-shot video dubbing via controlled latent noise injection. We open-source the dataset, training recipes, and 5B checkpoints to lower barriers for research in audio-driven human video generation. Project Page: https://zhenzhiwang.github.io/talkverse/
OpenDataArena: A Fair and Open Arena for Benchmarking Post-Training Dataset Value
Dec 16, 2025
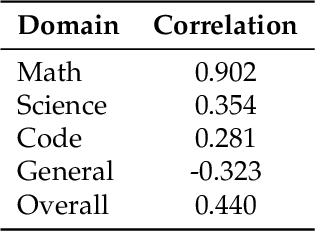
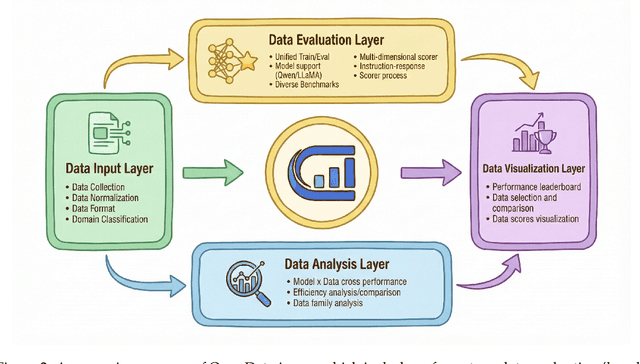

The rapid evolution of Large Language Models (LLMs) is predicated on the quality and diversity of post-training datasets. However, a critical dichotomy persists: while models are rigorously benchmarked, the data fueling them remains a black box--characterized by opaque composition, uncertain provenance, and a lack of systematic evaluation. This opacity hinders reproducibility and obscures the causal link between data characteristics and model behaviors. To bridge this gap, we introduce OpenDataArena (ODA), a holistic and open platform designed to benchmark the intrinsic value of post-training data. ODA establishes a comprehensive ecosystem comprising four key pillars: (i) a unified training-evaluation pipeline that ensures fair, open comparisons across diverse models (e.g., Llama, Qwen) and domains; (ii) a multi-dimensional scoring framework that profiles data quality along tens of distinct axes; (iii) an interactive data lineage explorer to visualize dataset genealogy and dissect component sources; and (iv) a fully open-source toolkit for training, evaluation, and scoring to foster data research. Extensive experiments on ODA--covering over 120 training datasets across multiple domains on 22 benchmarks, validated by more than 600 training runs and 40 million processed data points--reveal non-trivial insights. Our analysis uncovers the inherent trade-offs between data complexity and task performance, identifies redundancy in popular benchmarks through lineage tracing, and maps the genealogical relationships across datasets. We release all results, tools, and configurations to democratize access to high-quality data evaluation. Rather than merely expanding a leaderboard, ODA envisions a shift from trial-and-error data curation to a principled science of Data-Centric AI, paving the way for rigorous studies on data mixing laws and the strategic composition of foundation models.