 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMA: Complementary Masking and Hierarchical Dynamic Multi-Window Self-Attention in a Unified Pre-training Framework
Nov 08, 2025Masked Autoencoders (MAE) achieve self-supervised learning of image representations by randomly removing a portion of visual tokens and reconstructing the original image as a pretext task, thereby significantly enhancing pretraining efficiency and yielding excellent adaptability across downstream tasks. However, MAE and other MAE-style paradigms that adopt random masking generally require more pre-training epochs to maintain adaptability. Meanwhile, ViT in MAE suffers from inefficient parameter use due to fixed spatial resolution across layers. To overcome these limitations, we propose the Complementary Masked Autoencoders (CoMA), which employ a complementary masking strategy to ensure uniform sampling across all pixels, thereby improving effective learning of all features and enhancing the model's adaptability. Furthermore, we introduce DyViT, a hierarchical vision transformer that employs a Dynamic Multi-Window Self-Attention (DM-MSA), significantly reducing the parameters and FLOPs while improving fine-grained feature learning. Pre-trained on ImageNet-1K with CoMA, DyViT matches the downstream performance of MAE using only 12% of the pre-training epochs, demonstrating more effective learning. It also attains a 10% reduction in pre-training time per epoch, further underscoring its superior pre-training efficiency.
SPARK: Synergistic Policy And Reward Co-Evolving Framework
Sep 26, 2025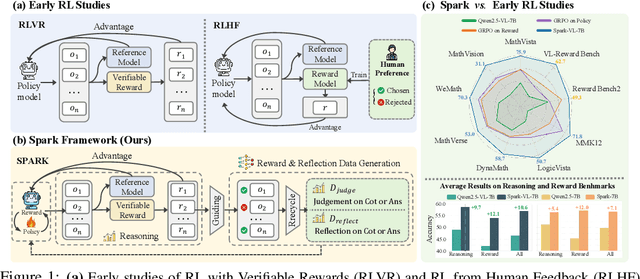
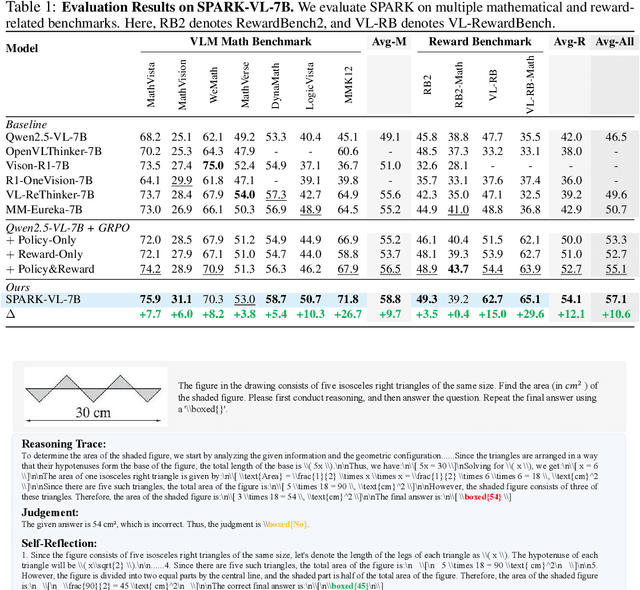
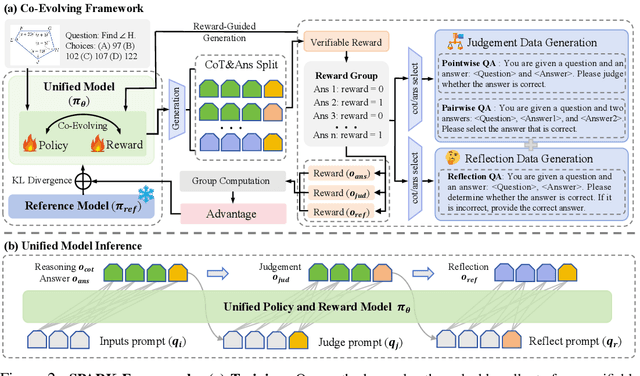
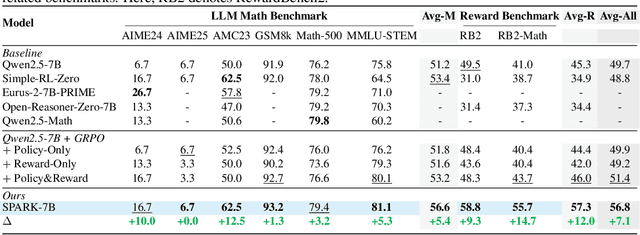
Recent Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) increasingly use Reinforcement Learning (RL) for post-pretraining, such as RL with Verifiable Rewards (RLVR) for objective tasks and RL from Human Feedback (RLHF) for subjective tasks. However, RLHF incurs high costs and potential reward-policy mismatch due to reliance on human preferences, while RLVR still wastes supervision by discarding rollouts and correctness signals after each update. To address these challenges, we introduce the Synergistic Policy And Reward Co-Evolving Framework (SPARK), an efficient, on-policy, and stable method that builds on RLVR. Instead of discarding rollouts and correctness data, SPARK recycles this valuable information to simultaneously train the model itself as a generative reward model. This auxiliary training uses a mix of objectives, such as pointwise reward score, pairwise comparison, and evaluation conditioned on further-reflection responses, to teach the model to evaluate and improve its own responses. Our process eliminates the need for a separate reward model and costly human preference data. SPARK creates a positive co-evolving feedback loop: improved reward accuracy yields better policy gradients, which in turn produce higher-quality rollouts that further refine the reward model. Our unified framework supports test-time scaling via self-reflection without external reward models and their associated costs. We show that SPARK achieves significant performance gains on multiple LLM and LVLM models and multiple reasoning, reward models, and general benchmarks. For example, SPARK-VL-7B achieves an average 9.7% gain on 7 reasoning benchmarks, 12.1% on 2 reward benchmarks, and 1.5% on 8 general benchmarks over the baselines, demonstrating robustness and broad generalization.
CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
Aug 27, 2025Autonomous agents for Graphical User Interfaces (GUIs) face significant challenges in specialized domains such as scientific computing, where both long-horizon planning and precise execution are required. Existing approaches suffer from a trade-off: generalist agents excel at planning but perform poorly in execution, while specialized agents demonstrate the opposite weakness. Recent compositional frameworks attempt to bridge this gap by combining a planner and an actor, but they are typically static and non-trainable, which prevents adaptation from experience. This is a critical limitation given the scarcity of high-quality data in scientific domains. To address these limitations, we introduce CODA, a novel and trainable compositional framework that integrates a generalist planner (Cerebrum) with a specialist executor (Cerebellum), trained via a dedicated two-stage pipeline. In the first stage, Specialization, we apply a decoupled GRPO approach to train an expert planner for each scientific application individually, bootstrapping from a small set of task trajectories. In the second stage, Generalization, we aggregate all successful trajectories from the specialized experts to build a consolidated dataset, which is then used for supervised fine-tuning of the final planner. This equips CODA with both robust execution and cross-domain generalization. Evaluated on four challenging applications from the ScienceBoard benchmark, CODA significantly outperforms baselines and establishes a new state of the art among open-source models.
SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience
Aug 06, 2025Repurposing large vision-language models (LVLMs) as computer use agents (CUAs) has led to substantial breakthroughs, primarily driven by human-labeled data. However, these models often struggle with novel and specialized software, particularly in scenarios lacking human annotations. To address this challenge, we propose SEAgent, an agentic self-evolving framework enabling CUAs to autonomously evolve through interactions with unfamiliar software. Specifically, SEAgent empowers computer-use agents to autonomously master novel software environments via experiential learning, where agents explore new software, learn through iterative trial-and-error, and progressively tackle auto-generated tasks organized from simple to complex. To achieve this goal, we design a World State Model for step-wise trajectory assessment, along with a Curriculum Generator that generates increasingly diverse and challenging tasks. The agent's policy is updated through experiential learning, comprised of adversarial imitation of failure actions and Group Relative Policy Optimization (GRPO) on successful ones. Furthermore, we introduce a specialist-to-generalist training strategy that integrates individual experiential insights from specialist agents, facilitating the development of a stronger generalist CUA capable of continuous autonomous evolution. This unified agent ultimately achieves performance surpassing ensembles of individual specialist agents on their specialized software. We validate the effectiveness of SEAgent across five novel software environments within OS-World. Our approach achieves a significant improvement of 23.2% in success rate, from 11.3% to 34.5%, over a competitive open-source CUA, i.e., UI-TARS.
Visual Agentic Reinforcement Fine-Tuning
May 20, 2025A key trend in Large Reasoning Models (e.g., OpenAI's o3) is the native agentic ability to use external tools such as web browsers for searching and writing/executing code for image manipulation to think with images. In the open-source research community, while significant progress has been made in language-only agentic abilities such as function calling and tool integration, the development of multi-modal agentic capabilities that involve truly thinking with images, and their corresponding benchmarks, are still less explored. This work highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) for enabling flexible and adaptive reasoning abilities for Large Vision-Language Models (LVLMs). With Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images through cropping, rotation, and other image processing techniques. We also present a Multi-modal Agentic Tool Bench (MAT) with two settings (MAT-Search and MAT-Coding) designed to evaluate LVLMs' agentic search and coding abilities. Our experimental results demonstrate that Visual-ARFT outperforms its baseline by +18.6% F1 / +13.0% EM on MAT-Coding and +10.3% F1 / +8.7% EM on MAT-Search, ultimately surpassing GPT-4o. Visual-ARFT also achieves +29.3 F1% / +25.9% EM gains on existing multi-hop QA benchmarks such as 2Wiki and HotpotQA, demonstrating strong generalization capabilities. Our findings suggest that Visual-ARFT offers a promising path toward building robust and generalizable multimodal agents.
Dance of Fireworks: An Interactive Broadcast Gymnastics Training System Based on Pose Estimation
May 05, 2025This study introduces Dance of Fireworks, an interactive system designed to combat sedentary health risks by enhancing engagement in radio calisthenics. Leveraging mobile device cameras and lightweight pose estimation (PoseNet/TensorFlow Lite), the system extracts body keypoints, computes joint angles, and compares them with standardized motions to deliver real-time corrective feedback. To incentivize participation, it dynamically maps users' movements (such as joint angles and velocity) to customizable fireworks animations, rewarding improved accuracy with richer visual effects. Experiments involving 136 participants demonstrated a significant reduction in average joint angle errors from 21.3 degrees to 9.8 degrees (p < 0.01) over four sessions, with 93.4 percent of users affirming its exercise-promoting efficacy and 85.4 percent praising its entertainment value. The system operates without predefined motion templates or specialised hardware, enabling seamless integration into office environments. Future enhancements will focus on improving pose recognition accuracy, reducing latency, and adding features such as multiplayer interaction and music synchronisation. This work presents a cost-effective, engaging solution to promote physical activity in sedentary populations.
AD-GPT: Large Language Models in Alzheimer's Disease
Apr 03, 2025Large language models (LLMs) have emerged as powerful tools for medical information retrieval, yet their accuracy and depth remain limited in specialized domains such as Alzheimer's disease (AD), a growing global health challenge. To address this gap, we introduce AD-GPT, a domain-specific generative pre-trained transformer designed to enhance the retrieval and analysis of AD-related genetic and neurobiological information. AD-GPT integrates diverse biomedical data sources, including potential AD-associated genes, molecular genetic information, and key gene variants linked to brain regions. We develop a stacked LLM architecture combining Llama3 and BERT, optimized for four critical tasks in AD research: (1) genetic information retrieval, (2) gene-brain region relationship assessment, (3) gene-AD relationship analysis, and (4) brain region-AD relationship mapping. Comparative evaluations against state-of-the-art LLMs demonstrate AD-GPT's superior precision and reliability across these tasks, underscoring its potential as a robust and specialized AI tool for advancing AD research and biomarker discovery.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Visual-RFT: Visual Reinforcement Fine-Tuning
Mar 03, 2025Reinforcement Fine-Tuning (RFT) in Large Reasoning Models like OpenAI o1 learns from feedback on its answers, which is especially useful in applications when fine-tuning data is scarce. Recent open-source work like DeepSeek-R1 demonstrates that reinforcement learning with verifiable reward is one key direction in reproducing o1. While the R1-style model has demonstrated success in language models, its application in multi-modal domains remains under-explored. This work introduces Visual Reinforcement Fine-Tuning (Visual-RFT), which further extends the application areas of RFT on visual tasks. Specifically, Visual-RFT first uses Large Vision-Language Models (LVLMs) to generate multiple responses containing reasoning tokens and final answers for each input, and then uses our proposed visual perception verifiable reward functions to update the model via the policy optimization algorithm such as Group Relative Policy Optimization (GRPO). We design different verifiable reward functions for different perception tasks, such as the Intersection over Union (IoU) reward for object detection. Experimental results on fine-grained image classification, few-shot object detection, reasoning grounding, as well as open-vocabulary object detection benchmarks show the competitive performance and advanced generalization ability of Visual-RFT compared with Supervised Fine-tuning (SFT). For example, Visual-RFT improves accuracy by $24.3\%$ over the baseline in one-shot fine-grained image classification with around 100 samples. In few-shot object detection, Visual-RFT also exceeds the baseline by $21.9$ on COCO's two-shot setting and $15.4$ on LVIS. Our Visual-RFT represents a paradigm shift in fine-tuning LVLMs, offering a data-efficient, reward-driven approach that enhances reasoning and adaptability for domain-specific tasks.
InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
Jan 21, 2025
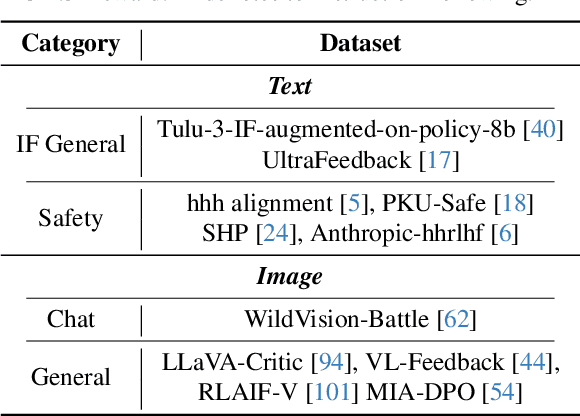


Despite the promising performance of Large Vision Language Models (LVLMs) in visual understanding, they occasionally generate incorrect outputs. While reward models (RMs) with reinforcement learning or test-time scaling offer the potential for improving generation quality, a critical gap remains: publicly available multi-modal RMs for LVLMs are scarce, and the implementation details of proprietary models are often unclear. We bridge this gap with InternLM-XComposer2.5-Reward (IXC-2.5-Reward), a simple yet effective multi-modal reward model that aligns LVLMs with human preferences. To ensure the robustness and versatility of IXC-2.5-Reward, we set up a high-quality multi-modal preference corpus spanning text, image, and video inputs across diverse domains, such as instruction following, general understanding, text-rich documents, mathematical reasoning, and video understanding. IXC-2.5-Reward achieves excellent results on the latest multi-modal reward model benchmark and shows competitive performance on text-only reward model benchmarks. We further demonstrate three key applications of IXC-2.5-Reward: (1) Providing a supervisory signal for RL training. We integrate IXC-2.5-Reward with Proximal Policy Optimization (PPO) yields IXC-2.5-Chat, which shows consistent improvements in instruction following and multi-modal open-ended dialogue; (2) Selecting the best response from candidate responses for test-time scaling; and (3) Filtering outlier or noisy samples from existing image and video instruction tuning training data. To ensure reproducibility and facilitate further research, we have open-sourced all model weights and training recipes at https://github.com/InternLM/InternLM-XComposer