 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMBFormer: An NDVI-Guided Global Memory Bank Transformer for Urban Green-Space Extraction from Ultra-High-Resolution Imagery
Jun 04, 2026Urban green-space extraction from ultra-high-resolution (UHR) imagery is commonly performed patch by patch, which limits semantic reuse among spatially separated but visually similar vegetation patterns. Directly injecting the Normalized Difference Vegetation Index (NDVI) into red-green-blue (RGB) backbones can also blur the roles of visual appearance learning and physical vegetation confidence. We propose GMBFormer, a SegFormer-based framework that replaces adjacency-driven feature propagation with selective, similarity-driven prototype retrieval. Only RGB channels enter the backbone and decoder, while NDVI is decoupled as a physics-informed gate that admits high-confidence vegetation descriptors into a compact global memory bank through momentum updates. During training and inference, the current patch queries stored prototypes through memory-mediated cross-attention, and the retrieved response is integrated with bounded overhead. Experiments use a self-constructed Chengdu UHR dataset with 7,700 labeled 512 x 512 patches and two reduced-label settings derived from the public International Society for Photogrammetry and Remote Sensing (ISPRS) Potsdam dataset. Under the same training and evaluation protocol, GMBFormer obtains mean intersection over union (mIoU)/mean Dice (mDice) scores of 89.25%/94.31%, 92.17%/95.92%, and 83.72%/90.86%, respectively, improving the controlled SegFormer-B4 baseline in each setting. Ablation studies indicate that decoupled NDVI admission, memory retrieval, capacity, and momentum jointly shape the final performance.
Multi-View Hierarchical Graph Neural Network for Sketch-Based 3D Shape Retrieval
Apr 20, 2026Sketch-based 3D shape retrieval (SBSR) aims to retrieve 3D shapes that are consistent with the category of the input hand-drawn sketch. The core challenge of this task lies in two aspects: existing methods typically employ simplified aggregation strategies for independently encoded 3D multi-view features, which ignore the geometric relationships between views and multi-level details, resulting in weak 3D representation. Simultaneously, traditional SBSR methods are constrained by visible category limitations, leading to poor performance in zero-shot scenarios. To address these challenges, we propose Multi-View Hierarchical Graph Neural Network (MV-HGNN), a novel framework for SBSR. Specifically, we construct a view-level graph and capture adjacent geometric dependencies and cross-view message passing via local graph convolution and global attention. A view selector is further introduced to perform hierarchical graph coarsening, enabling a progressively larger receptive field for graph convolution and mitigating the interference of redundant views, which leads to more discriminate discriminative hierarchical 3D representation. To enable category agnostic alignment and mitigate overfitting to seen classes, we leverage CLIP text embeddings as semantic prototypes and project both sketch and 3D features into a shared semantic space. We use a two-stage training strategy for category-level retrieval and a one-stage strategy for zero-shot retrieval under the same model architecture. Under both category-level and zero-shot settings, extensive experiments on two public benchmarks demonstrate that MV-HGNN outperforms state-of-the-art methods.
Transferable FB-GNN-MBE Framework for Potential Energy Surfaces: Data-Adaptive Transfer Learning in Deep Learned Many-Body Expansion Theory
Apr 10, 2026Mechanistic understanding and rational design of complex chemical systems depend on fast and accurate predictions of electronic structures beyond individual building blocks. However, if the system exceeds hundreds of atoms, first-principles quantum mechanical (QM) modeling becomes impractical. In this study, we developed FB-GNN-MBE by integrating a fragment-based graph neural network (FB-GNN) into the many-body expansion (MBE) theory and demonstrated its capacity to reproduce first-principles potential energy surfaces (PES) for hierarchically structured systems with manageable accuracy, complexity, and interpretability. Specifically, we divided the entire system into basic building blocks (fragments), evaluated their one-fragment energies using a QM model, and addressed many-fragment interactions using the structure-property relationships trained by FB-GNNs. Our investigation shows that FB-GNN-MBE achieves chemical accuracy in predicting two-body (2B) and three-body (3B) energies across water, phenol, and mixture benchmarks, as well as the one-dimensional dissociation curves of water and phenol dimers. To transfer the success of FB-GNN-MBE across various systems with minimal computational costs and data demands, we developed and validated a teacher-student learning protocol. A heavy-weight FB-GNN trained on a mixed-density water cluster ensemble (teacher) distills its learned knowledge and passes it to a light-weight GNN (student), which is later fine-tuned on a uniform-density (H2O)21 cluster ensemble. This transfer learning strategy resulted in efficient and accurate prediction of 2B and 3B energies for variously sized water clusters without retraining. Our transferable FB-GNN-MBE framework outperformed conventional non-FB-GNN-based models and showed high practicality for large-scale molecular simulations.
LLM-MLFFN: Multi-Level Autonomous Driving Behavior Feature Fusion via Large Language Model
Mar 03, 2026Accurate classification of autonomous vehicle (AV) driving behaviors is critical for safety validation, performance diagnosis, and traffic integration analysis. However, existing approaches primarily rely on numerical time-series modeling and often lack semantic abstraction, limiting interpretability and robustness in complex traffic environments. This paper presents LLM-MLFFN, a novel large language model (LLM)-enhanced multi-level feature fusion network designed to address the complexities of multi-dimensional driving data. The proposed LLM-MLFFN framework integrates priors from largescale pre-trained models and employs a multi-level approach to enhance classification accuracy. LLM-MLFFN comprises three core components: (1) a multi-level feature extraction module that extracts statistical, behavioral, and dynamic features to capture the quantitative aspects of driving behaviors; (2) a semantic description module that leverages LLMs to transform raw data into high-level semantic features; and (3) a dual-channel multi-level feature fusion network that combines numerical and semantic features using weighted attention mechanisms to improve robustness and prediction accuracy. Evaluation on the Waymo open trajectory dataset demonstrates the superior performance of the proposed LLM-MLFFN, achieving a classification accuracy of over 94%, surpassing existing machine learning models. Ablation studies further validate the critical contributions of multi-level fusion, feature extraction strategies, and LLM-derived semantic reasoning. These results suggest that integrating structured feature modeling with language-driven semantic abstraction provides a principled and interpretable pathway for robust autonomous driving behavior classification.
SheetMind: An End-to-End LLM-Powered Multi-Agent Framework for Spreadsheet Automation
Jun 14, 2025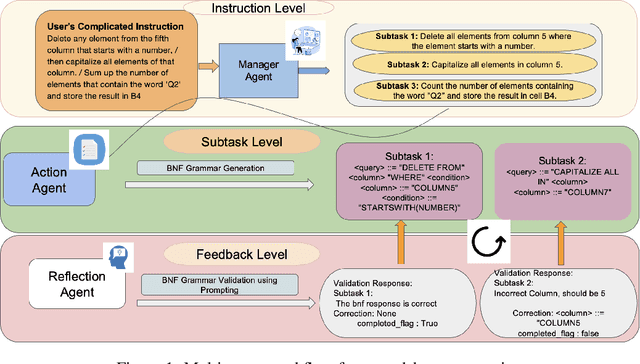
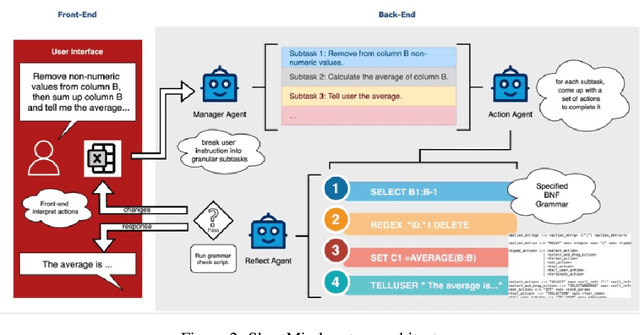
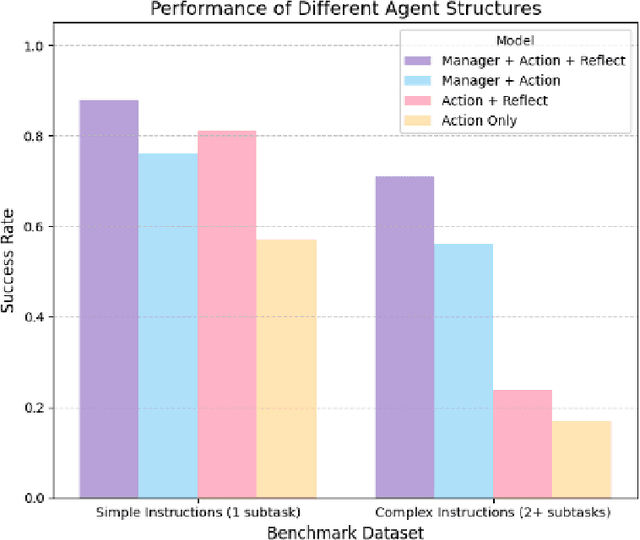
We present SheetMind, a modular multi-agent framework powered by large language models (LLMs) for spreadsheet automation via natural language instructions. The system comprises three specialized agents: a Manager Agent that decomposes complex user instructions into subtasks; an Action Agent that translates these into structured commands using a Backus Naur Form (BNF) grammar; and a Reflection Agent that validates alignment between generated actions and the user's original intent. Integrated into Google Sheets via a Workspace extension, SheetMind supports real-time interaction without requiring scripting or formula knowledge. Experiments on benchmark datasets demonstrate an 80 percent success rate on single step tasks and approximately 70 percent on multi step instructions, outperforming ablated and baseline variants. Our results highlight the effectiveness of multi agent decomposition and grammar based execution for bridging natural language and spreadsheet functionalities.
Integrating Natural Language Processing and Exercise Monitoring for Early Diagnosis of Metabolic Syndrome: A Deep Learning Approach
May 13, 2025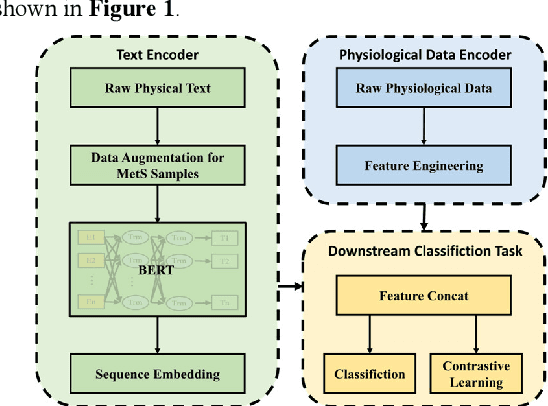
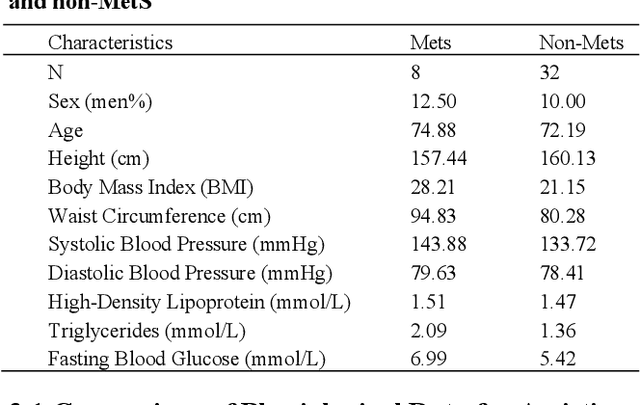
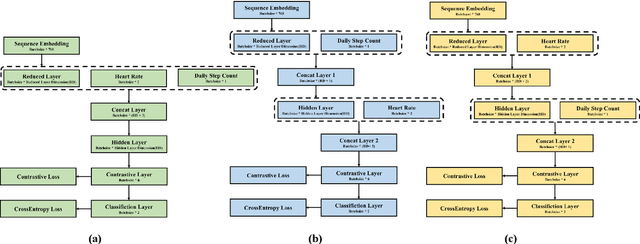
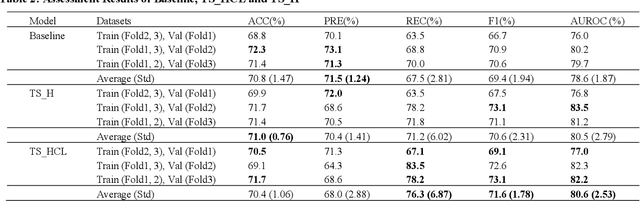
Metabolic syndrome (MetS) is a medication condition characterized by abdominal obesity, insulin resistance, hypertension and hyperlipidemia. It increases the risk of majority of chronic diseases, including type 2 diabetes mellitus, and affects about one quarter of the global population. Therefore, early detection and timely intervention for MetS are crucial. Standard diagnosis for MetS components requires blood tests conducted within medical institutions. However, it is frequently underestimated, leading to unmet need for care for MetS population. This study aims to use the least physiological data and free texts about exercises related activities, which are obtained easily in daily life, to diagnosis MetS. We collected the data from 40 volunteers in a nursing home and used data augmentation to reduce the imbalance. We propose a deep learning framework for classifying MetS that integrates natural language processing (NLP) and exercise monitoring. The results showed that the best model reported a high positive result (AUROC=0.806 and REC=76.3%) through 3-fold cross-validation. Feature importance analysis revealed that text and minimum heart rate on a daily basis contribute the most in the classification of MetS. This study demonstrates the potential application of data that are easily measurable in daily life for the early diagnosis of MetS, which could contribute to reducing the cost of screening and management for MetS population.
Dance of Fireworks: An Interactive Broadcast Gymnastics Training System Based on Pose Estimation
May 05, 2025This study introduces Dance of Fireworks, an interactive system designed to combat sedentary health risks by enhancing engagement in radio calisthenics. Leveraging mobile device cameras and lightweight pose estimation (PoseNet/TensorFlow Lite), the system extracts body keypoints, computes joint angles, and compares them with standardized motions to deliver real-time corrective feedback. To incentivize participation, it dynamically maps users' movements (such as joint angles and velocity) to customizable fireworks animations, rewarding improved accuracy with richer visual effects. Experiments involving 136 participants demonstrated a significant reduction in average joint angle errors from 21.3 degrees to 9.8 degrees (p < 0.01) over four sessions, with 93.4 percent of users affirming its exercise-promoting efficacy and 85.4 percent praising its entertainment value. The system operates without predefined motion templates or specialised hardware, enabling seamless integration into office environments. Future enhancements will focus on improving pose recognition accuracy, reducing latency, and adding features such as multiplayer interaction and music synchronisation. This work presents a cost-effective, engaging solution to promote physical activity in sedentary populations.
Constraint Learning for Parametric Point Cloud
Nov 12, 2024



Parametric point clouds are sampled from CAD shapes, have become increasingly prevalent in industrial manufacturing. However, most existing point cloud learning methods focus on the geometric features, such as local and global features or developing efficient convolution operations, overlooking the important attribute of constraints inherent in CAD shapes, which limits these methods' ability to fully comprehend CAD shapes. To address this issue, we analyzed the effect of constraints, and proposed its deep learning-friendly representation, after that, the Constraint Feature Learning Network (CstNet) is developed to extract and leverage constraints. Our CstNet includes two stages. The Stage 1 extracts constraints from B-Rep data or point cloud. The Stage 2 leverages coordinates and constraints to enhance the comprehend of CAD shapes. Additionally, we built up the Parametric 20,000 Multi-modal Dataset for the scarcity of labeled B-Rep datasets. Experiments demonstrate that our CstNet achieved state-of-the-art performance on both public and proposed CAD shapes datasets. To the best of our knowledge, CstNet is the first constraint-based learning method tailored for CAD shapes analysis.
AI Delegates with a Dual Focus: Ensuring Privacy and Strategic Self-Disclosure
Sep 26, 2024



Large language model (LLM)-based AI delegates are increasingly utilized to act on behalf of users, assisting them with a wide range of tasks through conversational interfaces. Despite their advantages, concerns arise regarding the potential risk of privacy leaks, particularly in scenarios involving social interactions. While existing research has focused on protecting privacy by limiting the access of AI delegates to sensitive user information, many social scenarios require disclosing private details to achieve desired outcomes, necessitating a balance between privacy protection and disclosure. To address this challenge, we conduct a pilot study to investigate user preferences for AI delegates across various social relations and task scenarios, and then propose a novel AI delegate system that enables privacy-conscious self-disclosure. Our user study demonstrates that the proposed AI delegate strategically protects privacy, pioneering its use in diverse and dynamic social interactions.
Training-Free Point Cloud Recognition Based on Geometric and Semantic Information Fusion
Sep 11, 2024



The trend of employing training-free methods for point cloud recognition is becoming increasingly popular due to its significant reduction in computational resources and time costs. However, existing approaches are limited as they typically extract either geometric or semantic features. To address this limitation, we are the first to propose a novel training-free method that integrates both geometric and semantic features. For the geometric branch, we adopt a non-parametric strategy to extract geometric features. In the semantic branch, we leverage a model aligned with text features to obtain semantic features. Additionally, we introduce the GFE module to complement the geometric information of point clouds and the MFF module to improve performance in few-shot settings. Experimental results demonstrate that our method outperforms existing state-of-the-art training-free approaches on mainstream benchmark datasets, including ModelNet and ScanObiectNN.