 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEETING DELEGATE: Benchmarking LLMs on Attending Meetings on Our Behalf
Feb 05, 2025In contemporary workplaces, meetings are essential for exchanging ideas and ensuring team alignment but often face challenges such as time consumption, scheduling conflicts, and inefficient participation. Recent advancements in Large Language Models (LLMs) have demonstrated their strong capabilities in natural language generation and reasoning, prompting the question: can LLMs effectively delegate participants in meetings? To explore this, we develop a prototype LLM-powered meeting delegate system and create a comprehensive benchmark using real meeting transcripts. Our evaluation reveals that GPT-4/4o maintain balanced performance between active and cautious engagement strategies. In contrast, Gemini 1.5 Pro tends to be more cautious, while Gemini 1.5 Flash and Llama3-8B/70B display more active tendencies. Overall, about 60\% of responses address at least one key point from the ground-truth. However, improvements are needed to reduce irrelevant or repetitive content and enhance tolerance for transcription errors commonly found in real-world settings. Additionally, we implement the system in practical settings and collect real-world feedback from demos. Our findings underscore the potential and challenges of utilizing LLMs as meeting delegates, offering valuable insights into their practical application for alleviating the burden of meetings.
Enabling Autonomic Microservice Management through Self-Learning Agents
Jan 31, 2025



The increasing complexity of modern software systems necessitates robust autonomic self-management capabilities. While Large Language Models (LLMs) demonstrate potential in this domain, they often face challenges in adapting their general knowledge to specific service contexts. To address this limitation, we propose ServiceOdyssey, a self-learning agent system that autonomously manages microservices without requiring prior knowledge of service-specific configurations. By leveraging curriculum learning principles and iterative exploration, ServiceOdyssey progressively develops a deep understanding of operational environments, reducing dependence on human input or static documentation. A prototype built with the Sock Shop microservice demonstrates the potential of this approach for autonomic microservice management.
Reason-before-Retrieve: One-Stage Reflective Chain-of-Thoughts for Training-Free Zero-Shot Composed Image Retrieval
Dec 15, 2024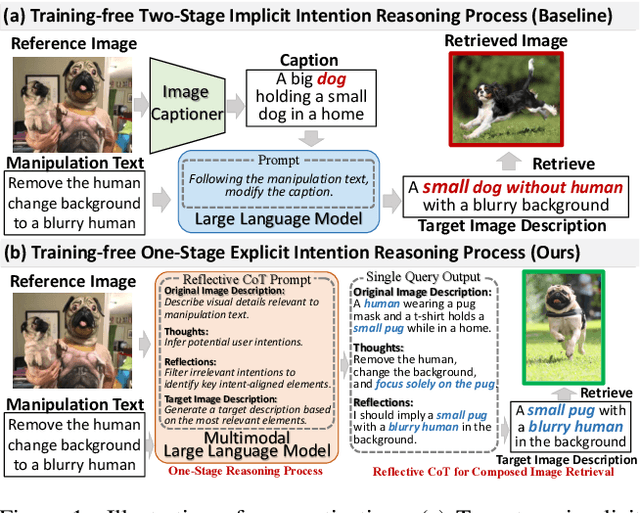
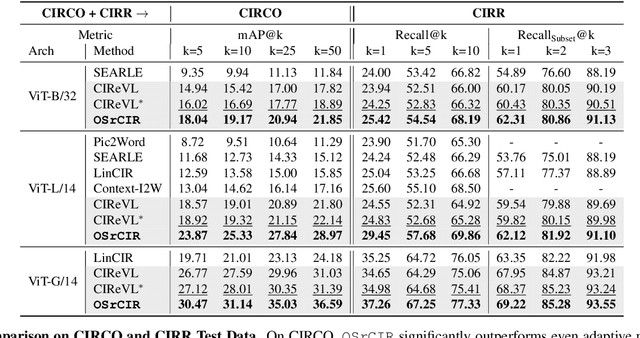
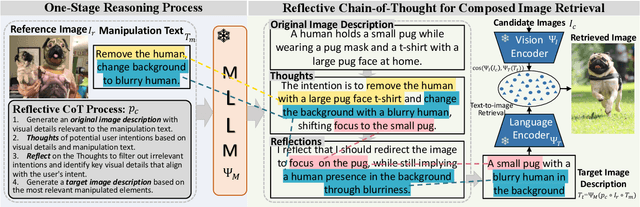
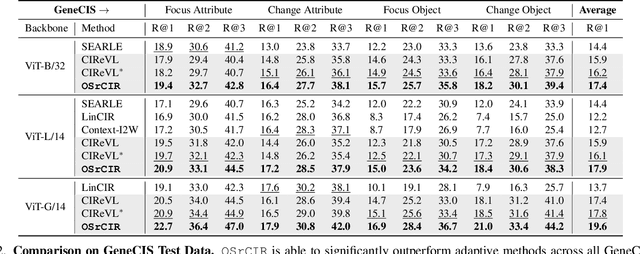
Composed Image Retrieval (CIR) aims to retrieve target images that closely resemble a reference image while integrating user-specified textual modifications, thereby capturing user intent more precisely. Existing training-free zero-shot CIR (ZS-CIR) methods often employ a two-stage process: they first generate a caption for the reference image and then use Large Language Models for reasoning to obtain a target description. However, these methods suffer from missing critical visual details and limited reasoning capabilities, leading to suboptimal retrieval performance. To address these challenges, we propose a novel, training-free one-stage method, One-Stage Reflective Chain-of-Thought Reasoning for ZS-CIR (OSrCIR), which employs Multimodal Large Language Models to retain essential visual information in a single-stage reasoning process, eliminating the information loss seen in two-stage methods. Our Reflective Chain-of-Thought framework further improves interpretative accuracy by aligning manipulation intent with contextual cues from reference images. OSrCIR achieves performance gains of 1.80% to 6.44% over existing training-free methods across multiple tasks, setting new state-of-the-art results in ZS-CIR and enhancing its utility in vision-language applications. Our code will be available at https://github.com/Pter61/osrcir2024/.
Sharingan: Extract User Action Sequence from Desktop Recordings
Nov 13, 2024Video recordings of user activities, particularly desktop recordings, offer a rich source of data for understanding user behaviors and automating processes. However, despite advancements in Vision-Language Models (VLMs) and their increasing use in video analysis, extracting user actions from desktop recordings remains an underexplored area. This paper addresses this gap by proposing two novel VLM-based methods for user action extraction: the Direct Frame-Based Approach (DF), which inputs sampled frames directly into VLMs, and the Differential Frame-Based Approach (DiffF), which incorporates explicit frame differences detected via computer vision techniques. We evaluate these methods using a basic self-curated dataset and an advanced benchmark adapted from prior work. Our results show that the DF approach achieves an accuracy of 70% to 80% in identifying user actions, with the extracted action sequences being re-playable though Robotic Process Automation. We find that while VLMs show potential, incorporating explicit UI changes can degrade performance, making the DF approach more reliable. This work represents the first application of VLMs for extracting user action sequences from desktop recordings, contributing new methods, benchmarks, and insights for future research.
Navigating the Unknown: A Chat-Based Collaborative Interface for Personalized Exploratory Tasks
Oct 31, 2024



The rise of large language models (LLMs) has revolutionized user interactions with knowledge-based systems, enabling chatbots to synthesize vast amounts of information and assist with complex, exploratory tasks. However, LLM-based chatbots often struggle to provide personalized support, particularly when users start with vague queries or lack sufficient contextual information. This paper introduces the Collaborative Assistant for Personalized Exploration (CARE), a system designed to enhance personalization in exploratory tasks by combining a multi-agent LLM framework with a structured user interface. CARE's interface consists of a Chat Panel, Solution Panel, and Needs Panel, enabling iterative query refinement and dynamic solution generation. The multi-agent framework collaborates to identify both explicit and implicit user needs, delivering tailored, actionable solutions. In a within-subject user study with 22 participants, CARE was consistently preferred over a baseline LLM chatbot, with users praising its ability to reduce cognitive load, inspire creativity, and provide more tailored solutions. Our findings highlight CARE's potential to transform LLM-based systems from passive information retrievers to proactive partners in personalized problem-solving and exploration.
AI Delegates with a Dual Focus: Ensuring Privacy and Strategic Self-Disclosure
Sep 26, 2024



Large language model (LLM)-based AI delegates are increasingly utilized to act on behalf of users, assisting them with a wide range of tasks through conversational interfaces. Despite their advantages, concerns arise regarding the potential risk of privacy leaks, particularly in scenarios involving social interactions. While existing research has focused on protecting privacy by limiting the access of AI delegates to sensitive user information, many social scenarios require disclosing private details to achieve desired outcomes, necessitating a balance between privacy protection and disclosure. To address this challenge, we conduct a pilot study to investigate user preferences for AI delegates across various social relations and task scenarios, and then propose a novel AI delegate system that enables privacy-conscious self-disclosure. Our user study demonstrates that the proposed AI delegate strategically protects privacy, pioneering its use in diverse and dynamic social interactions.
The Vision of Autonomic Computing: Can LLMs Make It a Reality?
Jul 19, 2024



The Vision of Autonomic Computing (ACV), proposed over two decades ago, envisions computing systems that self-manage akin to biological organisms, adapting seamlessly to changing environments. Despite decades of research, achieving ACV remains challenging due to the dynamic and complex nature of modern computing systems. Recent advancements in Large Language Models (LLMs) offer promising solutions to these challenges by leveraging their extensive knowledge, language understanding, and task automation capabilities. This paper explores the feasibility of realizing ACV through an LLM-based multi-agent framework for microservice management. We introduce a five-level taxonomy for autonomous service maintenance and present an online evaluation benchmark based on the Sock Shop microservice demo project to assess our framework's performance. Our findings demonstrate significant progress towards achieving Level 3 autonomy, highlighting the effectiveness of LLMs in detecting and resolving issues within microservice architectures. This study contributes to advancing autonomic computing by pioneering the integration of LLMs into microservice management frameworks, paving the way for more adaptive and self-managing computing systems. The code will be made available at https://aka.ms/ACV-LLM.
AutoRAG-HP: Automatic Online Hyper-Parameter Tuning for Retrieval-Augmented Generation
Jun 27, 2024



Recent advancements in Large Language Models have transformed ML/AI development, necessitating a reevaluation of AutoML principles for the Retrieval-Augmented Generation (RAG) systems. To address the challenges of hyper-parameter optimization and online adaptation in RAG, we propose the AutoRAG-HP framework, which formulates the hyper-parameter tuning as an online multi-armed bandit (MAB) problem and introduces a novel two-level Hierarchical MAB (Hier-MAB) method for efficient exploration of large search spaces. We conduct extensive experiments on tuning hyper-parameters, such as top-k retrieved documents, prompt compression ratio, and embedding methods, using the ALCE-ASQA and Natural Questions datasets. Our evaluation from jointly optimization all three hyper-parameters demonstrate that MAB-based online learning methods can achieve Recall@5 $\approx 0.8$ for scenarios with prominent gradients in search space, using only $\sim20\%$ of the LLM API calls required by the Grid Search approach. Additionally, the proposed Hier-MAB approach outperforms other baselines in more challenging optimization scenarios. The code will be made available at https://aka.ms/autorag.
Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments
Mar 13, 2024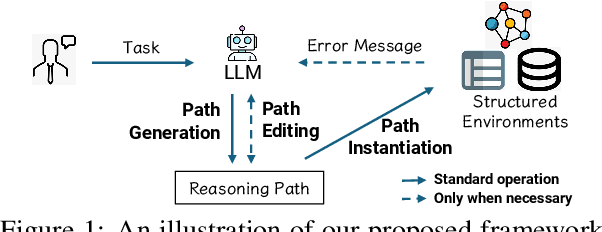
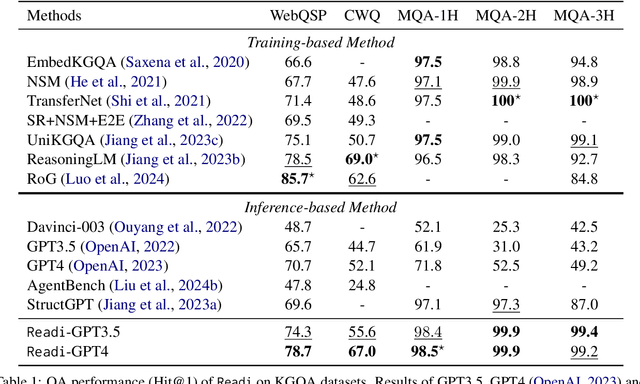
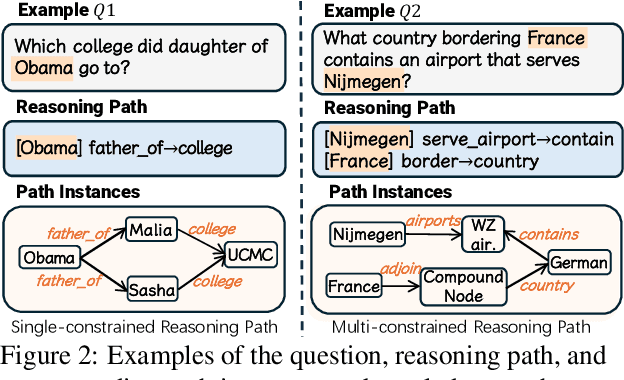
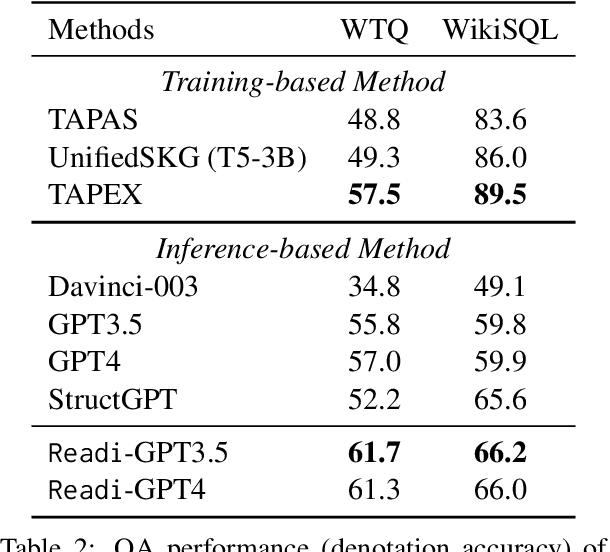
Large Language Models (LLMs) have shown potential in reasoning over structured environments, e.g., knowledge graph and table. Such tasks typically require multi-hop reasoning, i.e., match natural language utterance with instances in the environment. Previous methods leverage LLMs to incrementally build a reasoning path, where the LLMs either invoke tools or pick up schemas by step-by-step interacting with the environment. We propose Reasoning-Path-Editing (Readi), a novel framework where LLMs can efficiently and faithfully reason over structured environments. In Readi, LLMs initially generate a reasoning path given a query, and edit the path only when necessary. We instantiate the path on structured environments and provide feedback to edit the path if anything goes wrong. Experimental results on three KGQA datasets and two TableQA datasets show the effectiveness of Readi, significantly surpassing all LLM-based methods (by 9.1% on WebQSP, 12.4% on MQA-3H and 10.9% on WTQ), comparable with state-of-the-art fine-tuned methods (67% on CWQ and 74.7% on WebQSP) and substantially boosting the vanilla LLMs (by 14.9% on CWQ). Our code will be available upon publication.
TaskWeaver: A Code-First Agent Framework
Dec 01, 2023
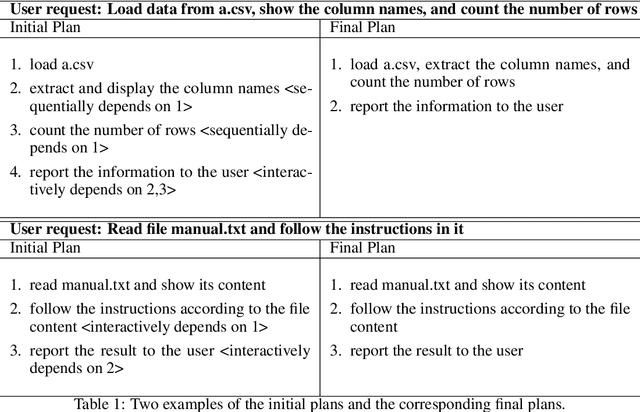
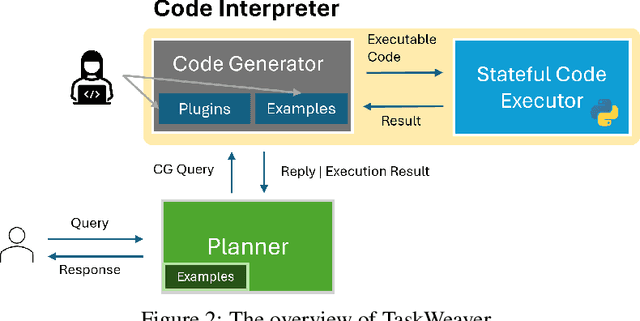
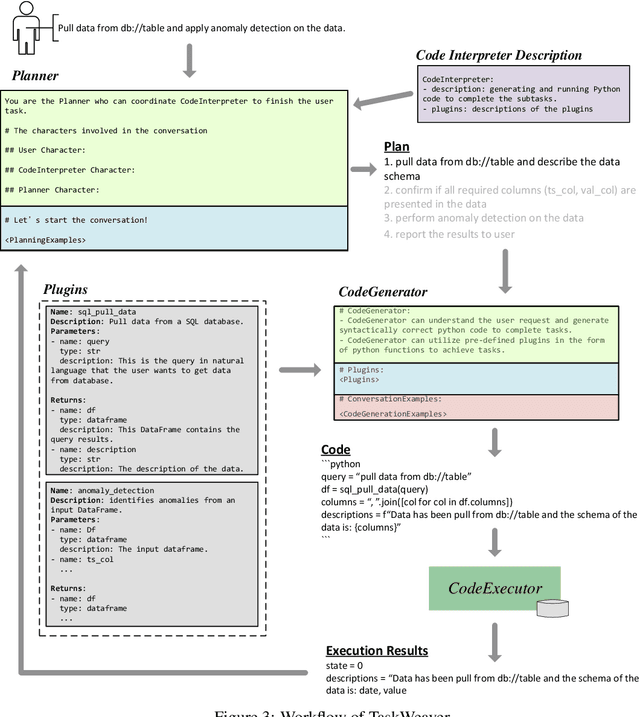
Large Language Models (LLMs) have shown impressive abilities in natural language understanding and generation, leading to their use in applications such as chatbots and virtual assistants. However, existing LLM frameworks face limitations in handling domain-specific data analytics tasks with rich data structures. Moreover, they struggle with flexibility to meet diverse user requirements. To address these issues, TaskWeaver is proposed as a code-first framework for building LLM-powered autonomous agents. It converts user requests into executable code and treats user-defined plugins as callable functions. TaskWeaver provides support for rich data structures, flexible plugin usage, and dynamic plugin selection, and leverages LLM coding capabilities for complex logic. It also incorporates domain-specific knowledge through examples and ensures the secure execution of generated code. TaskWeaver offers a powerful and flexible framework for creating intelligent conversational agents that can handle complex tasks and adapt to domain-specific scenarios. The code is open-sourced at https://github.com/microsoft/TaskWeaver/.