 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
Enabling Autonomic Microservice Management through Self-Learning Agents
Jan 31, 2025



The increasing complexity of modern software systems necessitates robust autonomic self-management capabilities. While Large Language Models (LLMs) demonstrate potential in this domain, they often face challenges in adapting their general knowledge to specific service contexts. To address this limitation, we propose ServiceOdyssey, a self-learning agent system that autonomously manages microservices without requiring prior knowledge of service-specific configurations. By leveraging curriculum learning principles and iterative exploration, ServiceOdyssey progressively develops a deep understanding of operational environments, reducing dependence on human input or static documentation. A prototype built with the Sock Shop microservice demonstrates the potential of this approach for autonomic microservice management.
Skeleton-Guided-Translation: A Benchmarking Framework for Code Repository Translation with Fine-Grained Quality Evaluation
Jan 27, 2025



The advancement of large language models has intensified the need to modernize enterprise applications and migrate legacy systems to secure, versatile languages. However, existing code translation benchmarks primarily focus on individual functions, overlooking the complexities involved in translating entire repositories, such as maintaining inter-module coherence and managing dependencies. While some recent repository-level translation benchmarks attempt to address these challenges, they still face limitations, including poor maintainability and overly coarse evaluation granularity, which make them less developer-friendly. We introduce Skeleton-Guided-Translation, a framework for repository-level Java to C# code translation with fine-grained quality evaluation. It uses a two-step process: first translating the repository's structural "skeletons", then translating the full repository guided by these skeletons. Building on this, we present TRANSREPO-BENCH, a benchmark of high quality open-source Java repositories and their corresponding C# skeletons, including matching unit tests and build configurations. Our unit tests are fixed and can be applied across multiple or incremental translations without manual adjustments, enhancing automation and scalability in evaluations. Additionally, we develop fine-grained evaluation metrics that assess translation quality at the individual test case level, addressing traditional binary metrics' inability to distinguish when build failures cause all tests to fail. Evaluations using TRANSREPO-BENCH highlight key challenges and advance more accurate repository level code translation.
DI-BENCH: Benchmarking Large Language Models on Dependency Inference with Testable Repositories at Scale
Jan 23, 2025Large Language Models have advanced automated software development, however, it remains a challenge to correctly infer dependencies, namely, identifying the internal components and external packages required for a repository to successfully run. Existing studies highlight that dependency-related issues cause over 40\% of observed runtime errors on the generated repository. To address this, we introduce DI-BENCH, a large-scale benchmark and evaluation framework specifically designed to assess LLMs' capability on dependency inference. The benchmark features 581 repositories with testing environments across Python, C#, Rust, and JavaScript. Extensive experiments with textual and execution-based metrics reveal that the current best-performing model achieves only a 42.9% execution pass rate, indicating significant room for improvement. DI-BENCH establishes a new viewpoint for evaluating LLM performance on repositories, paving the way for more robust end-to-end software synthesis.
Xpert: Empowering Incident Management with Query Recommendations via Large Language Models
Dec 19, 2023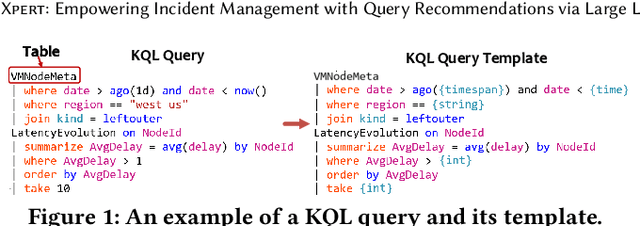

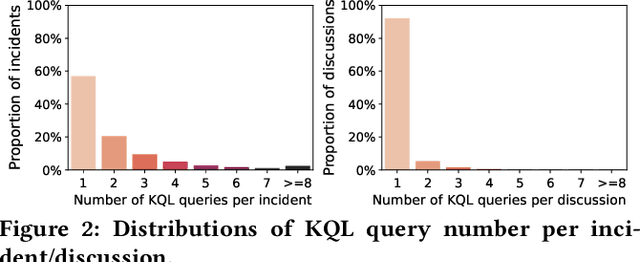

Large-scale cloud systems play a pivotal role in modern IT infrastructure. However, incidents occurring within these systems can lead to service disruptions and adversely affect user experience. To swiftly resolve such incidents, on-call engineers depend on crafting domain-specific language (DSL) queries to analyze telemetry data. However, writing these queries can be challenging and time-consuming. This paper presents a thorough empirical study on the utilization of queries of KQL, a DSL employed for incident management in a large-scale cloud management system at Microsoft. The findings obtained underscore the importance and viability of KQL queries recommendation to enhance incident management. Building upon these valuable insights, we introduce Xpert, an end-to-end machine learning framework that automates KQL recommendation process. By leveraging historical incident data and large language models, Xpert generates customized KQL queries tailored to new incidents. Furthermore, Xpert incorporates a novel performance metric called Xcore, enabling a thorough evaluation of query quality from three comprehensive perspectives. We conduct extensive evaluations of Xpert, demonstrating its effectiveness in offline settings. Notably, we deploy Xpert in the real production environment of a large-scale incident management system in Microsoft, validating its efficiency in supporting incident management. To the best of our knowledge, this paper represents the first empirical study of its kind, and Xpert stands as a pioneering DSL query recommendation framework designed for incident management.
Breaking hypothesis testing for failure rates
Jan 13, 2020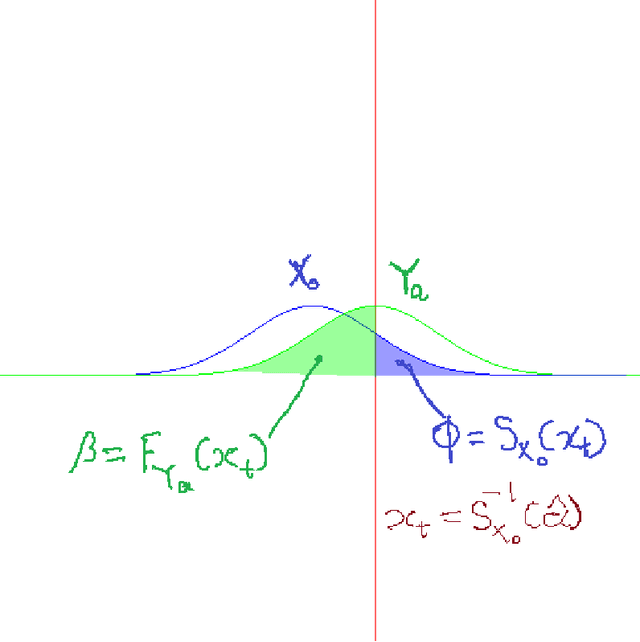
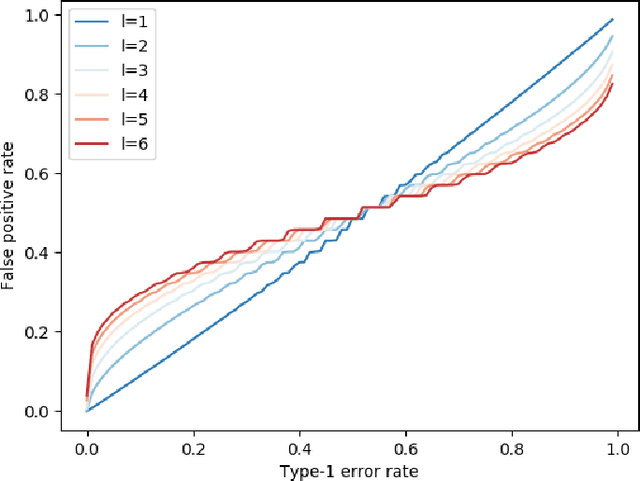
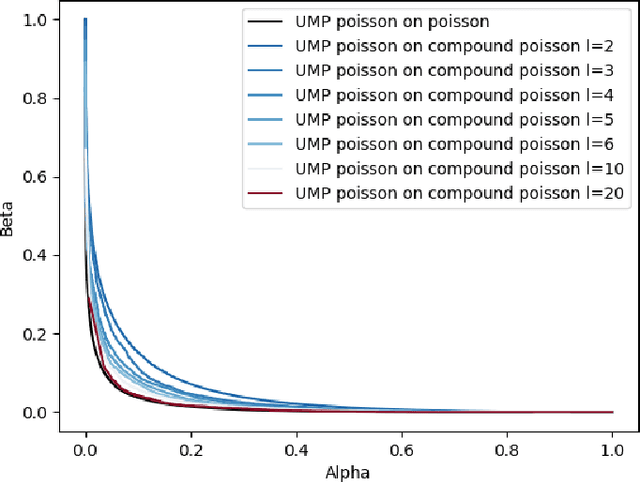
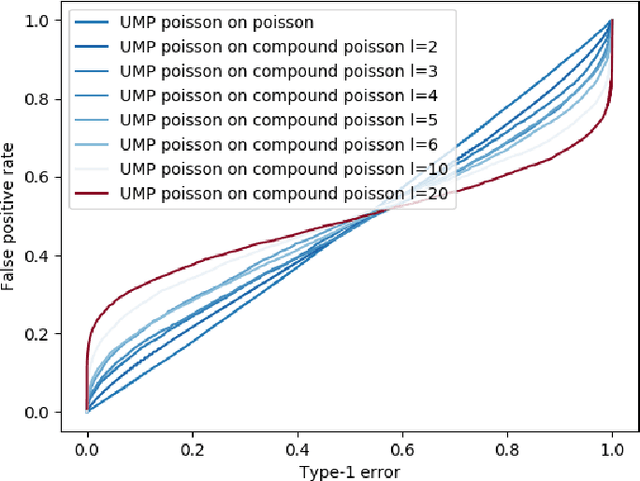
We describe the utility of point processes and failure rates and the most common point process for modeling failure rates, the Poisson point process. Next, we describe the uniformly most powerful test for comparing the rates of two Poisson point processes for a one-sided test (henceforth referred to as the "rate test"). A common argument against using this test is that real world data rarely follows the Poisson point process. We thus investigate what happens when the distributional assumptions of tests like these are violated and the test still applied. We find a non-pathological example (using the rate test on a Compound Poisson distribution with Binomial compounding) where violating the distributional assumptions of the rate test make it perform better (lower error rates). We also find that if we replace the distribution of the test statistic under the null hypothesis with any other arbitrary distribution, the performance of the test (described in terms of the false negative rate to false positive rate trade-off) remains exactly the same. Next, we compare the performance of the rate test to a version of the Wald test customized to the Negative Binomial point process and find it to perform very similarly while being much more general and versatile. Finally, we discuss the applications to Microsoft Azure. The code for all experiments performed is open source and linked in the introduction.