 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepoLaunch: Automating Build&Test Pipeline of Code Repositories on ANY Language and ANY Platform
Mar 05, 2026Building software repositories typically requires significant manual effort. Recent advances in large language model (LLM) agents have accelerated automation in software engineering (SWE). We introduce RepoLaunch, the first agent capable of automatically resolving dependencies, compiling source code, and extracting test results for repositories across arbitrary programming languages and operating systems. To demonstrate its utility, we further propose a fully automated pipeline for SWE dataset creation, where task design is the only human intervention. RepoLaunch automates the remaining steps, enabling scalable benchmarking and training of coding agents and LLMs. Notably, several works on agentic benchmarking and training have recently adopted RepoLaunch for automated task generation.
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Jan 23, 2026LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
AlphaResearch: Accelerating New Algorithm Discovery with Language Models
Nov 11, 2025Large language models have made significant progress in complex but easy-to-verify problems, yet they still struggle with discovering the unknown. In this paper, we present \textbf{AlphaResearch}, an autonomous research agent designed to discover new algorithms on open-ended problems. To synergize the feasibility and innovation of the discovery process, we construct a novel dual research environment by combining the execution-based verify and simulated real-world peer review environment. AlphaResearch discovers new algorithm by iteratively running the following steps: (1) propose new ideas (2) verify the ideas in the dual research environment (3) optimize the research proposals for better performance. To promote a transparent evaluation process, we construct \textbf{AlphaResearchComp}, a new evaluation benchmark that includes an eight open-ended algorithmic problems competition, with each problem carefully curated and verified through executable pipelines, objective metrics, and reproducibility checks. AlphaResearch gets a 2/8 win rate in head-to-head comparison with human researchers, demonstrate the possibility of accelerating algorithm discovery with LLMs. Notably, the algorithm discovered by AlphaResearch on the \emph{``packing circles''} problem achieves the best-of-known performance, surpassing the results of human researchers and strong baselines from recent work (e.g., AlphaEvolve). Additionally, we conduct a comprehensive analysis of the remaining challenges of the 6/8 failure cases, providing valuable insights for future research.
SWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.
UFO2: The Desktop AgentOS
Apr 20, 2025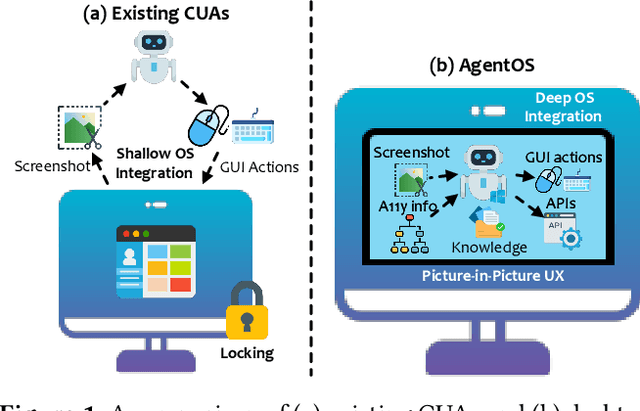
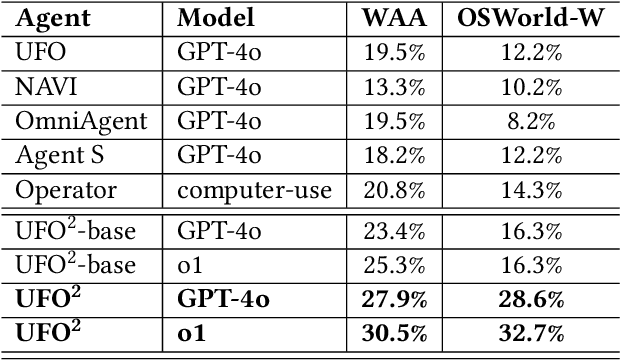
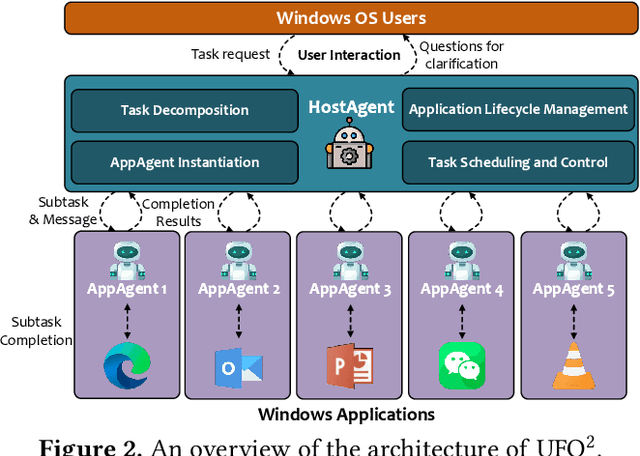
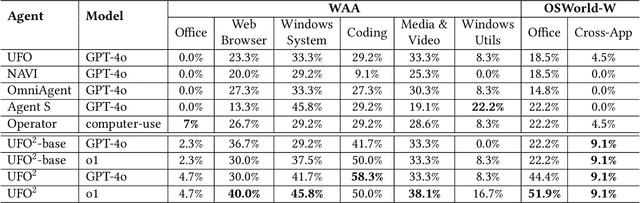
Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
API Agents vs. GUI Agents: Divergence and Convergence
Mar 14, 2025Large language models (LLMs) have evolved beyond simple text generation to power software agents that directly translate natural language commands into tangible actions. While API-based LLM agents initially rose to prominence for their robust automation capabilities and seamless integration with programmatic endpoints, recent progress in multimodal LLM research has enabled GUI-based LLM agents that interact with graphical user interfaces in a human-like manner. Although these two paradigms share the goal of enabling LLM-driven task automation, they diverge significantly in architectural complexity, development workflows, and user interaction models. This paper presents the first comprehensive comparative study of API-based and GUI-based LLM agents, systematically analyzing their divergence and potential convergence. We examine key dimensions and highlight scenarios in which hybrid approaches can harness their complementary strengths. By proposing clear decision criteria and illustrating practical use cases, we aim to guide practitioners and researchers in selecting, combining, or transitioning between these paradigms. Ultimately, we indicate that continuing innovations in LLM-based automation are poised to blur the lines between API- and GUI-driven agents, paving the way for more flexible, adaptive solutions in a wide range of real-world applications.
DI-BENCH: Benchmarking Large Language Models on Dependency Inference with Testable Repositories at Scale
Jan 23, 2025Large Language Models have advanced automated software development, however, it remains a challenge to correctly infer dependencies, namely, identifying the internal components and external packages required for a repository to successfully run. Existing studies highlight that dependency-related issues cause over 40\% of observed runtime errors on the generated repository. To address this, we introduce DI-BENCH, a large-scale benchmark and evaluation framework specifically designed to assess LLMs' capability on dependency inference. The benchmark features 581 repositories with testing environments across Python, C#, Rust, and JavaScript. Extensive experiments with textual and execution-based metrics reveal that the current best-performing model achieves only a 42.9% execution pass rate, indicating significant room for improvement. DI-BENCH establishes a new viewpoint for evaluating LLM performance on repositories, paving the way for more robust end-to-end software synthesis.
Large Action Models: From Inception to Implementation
Dec 13, 2024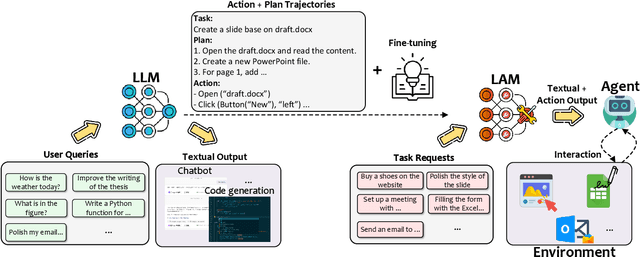

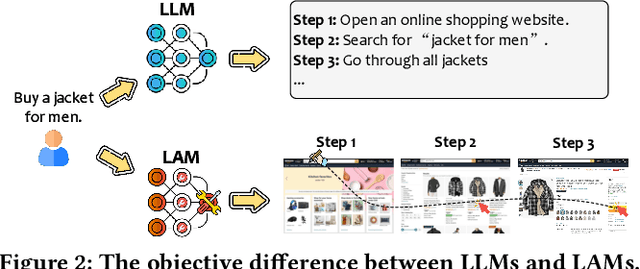

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions. This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments. Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence. In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment. We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation. This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications. The code for the data collection process utilized in this paper is publicly available at: https://github.com/microsoft/UFO/tree/main/dataflow, and comprehensive documentation can be found at https://microsoft.github.io/UFO/dataflow/overview/.
Large Language Model-Brained GUI Agents: A Survey
Dec 03, 2024



GUIs have long been central to human-computer interaction, providing an intuitive and visually-driven way to access and interact with digital systems. The advent of LLMs, particularly multimodal models, has ushered in a new era of GUI automation. They have demonstrated exceptional capabilities in natural language understanding, code generation, and visual processing. This has paved the way for a new generation of LLM-brained GUI agents capable of interpreting complex GUI elements and autonomously executing actions based on natural language instructions. These agents represent a paradigm shift, enabling users to perform intricate, multi-step tasks through simple conversational commands. Their applications span across web navigation, mobile app interactions, and desktop automation, offering a transformative user experience that revolutionizes how individuals interact with software. This emerging field is rapidly advancing, with significant progress in both research and industry. To provide a structured understanding of this trend, this paper presents a comprehensive survey of LLM-brained GUI agents, exploring their historical evolution, core components, and advanced techniques. We address research questions such as existing GUI agent frameworks, the collection and utilization of data for training specialized GUI agents, the development of large action models tailored for GUI tasks, and the evaluation metrics and benchmarks necessary to assess their effectiveness. Additionally, we examine emerging applications powered by these agents. Through a detailed analysis, this survey identifies key research gaps and outlines a roadmap for future advancements in the field. By consolidating foundational knowledge and state-of-the-art developments, this work aims to guide both researchers and practitioners in overcoming challenges and unlocking the full potential of LLM-brained GUI agents.
UFO: A UI-Focused Agent for Windows OS Interaction
Feb 23, 2024



We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on https://github.com/microsoft/UFO.