 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025



Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
UFO2: The Desktop AgentOS
Apr 20, 2025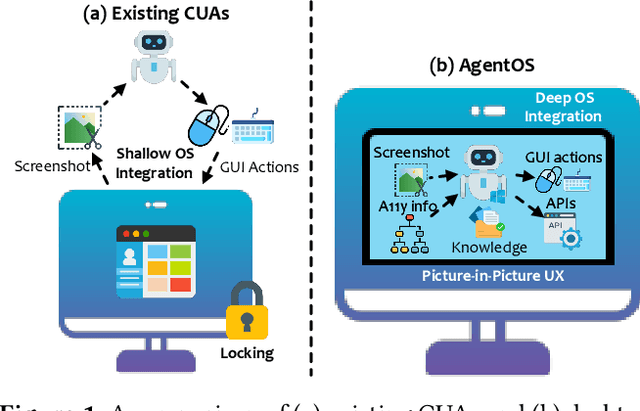
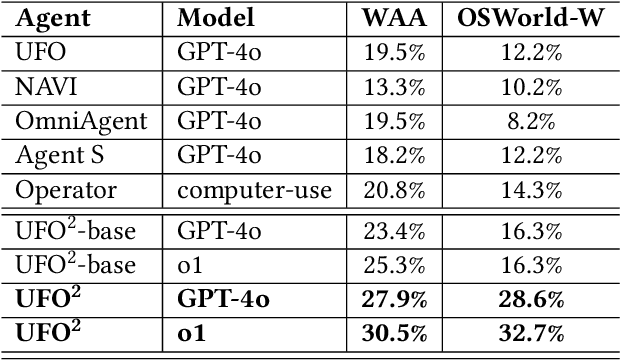
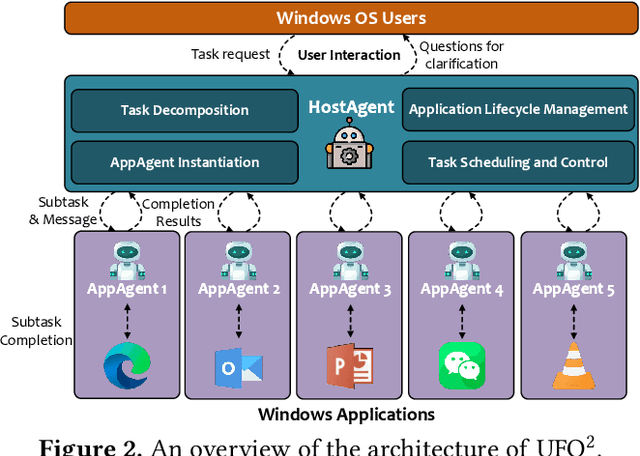
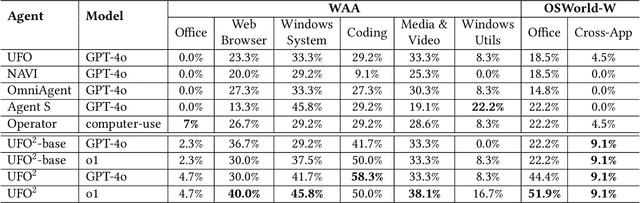
Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
Large Action Models: From Inception to Implementation
Dec 13, 2024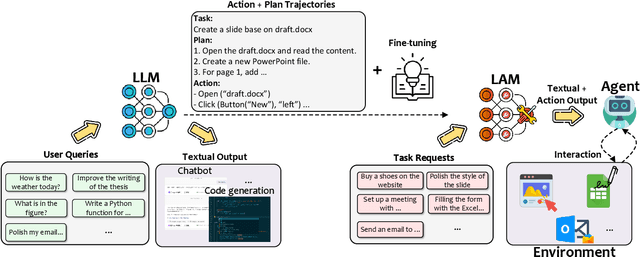

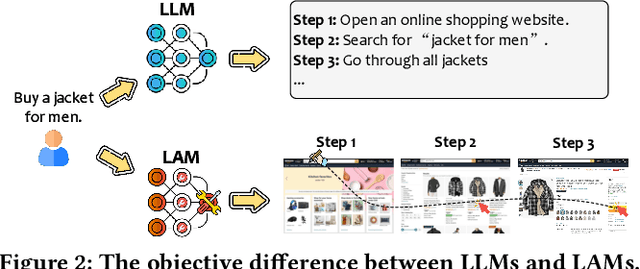

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions. This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments. Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence. In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment. We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation. This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications. The code for the data collection process utilized in this paper is publicly available at: https://github.com/microsoft/UFO/tree/main/dataflow, and comprehensive documentation can be found at https://microsoft.github.io/UFO/dataflow/overview/.
Large Language Model-Brained GUI Agents: A Survey
Dec 03, 2024



GUIs have long been central to human-computer interaction, providing an intuitive and visually-driven way to access and interact with digital systems. The advent of LLMs, particularly multimodal models, has ushered in a new era of GUI automation. They have demonstrated exceptional capabilities in natural language understanding, code generation, and visual processing. This has paved the way for a new generation of LLM-brained GUI agents capable of interpreting complex GUI elements and autonomously executing actions based on natural language instructions. These agents represent a paradigm shift, enabling users to perform intricate, multi-step tasks through simple conversational commands. Their applications span across web navigation, mobile app interactions, and desktop automation, offering a transformative user experience that revolutionizes how individuals interact with software. This emerging field is rapidly advancing, with significant progress in both research and industry. To provide a structured understanding of this trend, this paper presents a comprehensive survey of LLM-brained GUI agents, exploring their historical evolution, core components, and advanced techniques. We address research questions such as existing GUI agent frameworks, the collection and utilization of data for training specialized GUI agents, the development of large action models tailored for GUI tasks, and the evaluation metrics and benchmarks necessary to assess their effectiveness. Additionally, we examine emerging applications powered by these agents. Through a detailed analysis, this survey identifies key research gaps and outlines a roadmap for future advancements in the field. By consolidating foundational knowledge and state-of-the-art developments, this work aims to guide both researchers and practitioners in overcoming challenges and unlocking the full potential of LLM-brained GUI agents.
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
May 24, 2024Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
PathMLP: Smooth Path Towards High-order Homophily
Jun 23, 2023



Real-world graphs exhibit increasing heterophily, where nodes no longer tend to be connected to nodes with the same label, challenging the homophily assumption of classical graph neural networks (GNNs) and impeding their performance. Intriguingly, we observe that certain high-order information on heterophilous data exhibits high homophily, which motivates us to involve high-order information in node representation learning. However, common practices in GNNs to acquire high-order information mainly through increasing model depth and altering message-passing mechanisms, which, albeit effective to a certain extent, suffer from three shortcomings: 1) over-smoothing due to excessive model depth and propagation times; 2) high-order information is not fully utilized; 3) low computational efficiency. In this regard, we design a similarity-based path sampling strategy to capture smooth paths containing high-order homophily. Then we propose a lightweight model based on multi-layer perceptrons (MLP), named PathMLP, which can encode messages carried by paths via simple transformation and concatenation operations, and effectively learn node representations in heterophilous graphs through adaptive path aggregation. Extensive experiments demonstrate that our method outperforms baselines on 16 out of 20 datasets, underlining its effectiveness and superiority in alleviating the heterophily problem. In addition, our method is immune to over-smoothing and has high computational efficiency.