 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeSeeker: Tree-Structured Trial, Error, and Return in Deep Search
Jun 10, 2026Deep search requires agents to answer complex questions through multi-step web search, browsing, evidence comparison, and synthesis. A central challenge is deciding how to search when several directions look plausible but only some will later lead to reliable evidence. If an agent greedily follows the current best-looking direction, it may keep extending a weak continuation. If it explores without discipline, it may waste budget on disconnected trials. We propose TreeSeeker, an inference-time framework for controlled trial-and-error in deep search. TreeSeeker organizes search as branch-and-return search over tree-structured states, where each branch is a tentative direction for a sub-goal. At each round, TreeSearch reads all sub-goal trees, identifies active goals, and uses textual UCB signals of value, uncertainty, and risk to select among exploiting a promising branch, exploring an uncertain alternative, or pruning an unproductive continuation and returning to an earlier branch point. TreeMem supports this control loop by keeping evidence, uncertainty, conflicts, progress, and failure cues attached to the branches that produced them, so trial outcomes can guide later decisions. Experiments on XBench-DeepSearch, BrowseComp, and BrowseComp-ZH show that TreeSeeker consistently outperforms strong open-source baselines, suggesting that explicit branch-and-return control complements stronger reasoning and tool execution.
Beyond State Consistency: Behavior Consistency in Text-Based World Models
Apr 15, 2026World models have been emerging as critical components for assessing the consequences of actions generated by interactive agents in online planning and offline evaluation. In text-based environments, world models are typically evaluated and trained with single-step metrics such as Exact Match, aiming to improve the similarity between predicted and real-world states, but such metrics have been shown to be insufficient for capturing actual agent behavior. To address this issue, we introduce a new behavior-aligned training paradigm aimed at improving the functional consistency between the world model and the real environment. This paradigm focuses on optimizing a tractable step-level metric named Behavior Consistency Reward (BehR), which measures how much the likelihood of a logged next action changes between the real state and the world-model-predicted state under a frozen Reference Agent. Experiments on WebShop and TextWorld show that BehR-based training improves long-term alignment in several settings, with the clearest gains in WebShop and less movement in near-ceiling regimes, while preserving or improving single-step prediction quality in three of four settings. World models trained with BehR also achieve lower false positives in offline surrogate evaluation and show modest but encouraging gains in inference-time lookahead planning.
DUET: Joint Exploration of User Item Profiles in Recommendation System
Apr 15, 2026Traditional recommendation systems represent users and items as dense vectors and learn to align them in a shared latent space for relevance estimation. Recent LLM-based recommenders instead leverage natural-language representations that are easier to interpret and integrate with downstream reasoning modules. This paper studies how to construct effective textual profiles for users and items, and how to align them for recommendation. A central difficulty is that the best profile format is not known a priori: manually designed templates can be brittle and misaligned with task objectives. Moreover, generating user and item profiles independently may produce descriptions that are individually plausible yet semantically inconsistent for a specific user--item pair. We propose Duet, an interaction-aware profile generator that jointly produces user and item profiles conditioned on both user history and item evidence. Duet follows a three-stage procedure: it first turns raw histories and metadata into compact cues, then expands these cues into paired profile prompts and then generate profiles, and finally optimizes the generation policy with reinforcement learning using downstream recommendation performance as feedback. Experiments on three real-world datasets show that Duet consistently outperforms strong baselines, demonstrating the benefits of template-free profile exploration and joint user-item textual alignment.
A Tale of Two Graphs: Separating Knowledge Exploration from Outline Structure for Open-Ended Deep Research
Feb 14, 2026Open-Ended Deep Research (OEDR) pushes LLM agents beyond short-form QA toward long-horizon workflows that iteratively search, connect, and synthesize evidence into structured reports. However, existing OEDR agents largely follow either linear ``search-then-generate'' accumulation or outline-centric planning. The former suffers from lost-in-the-middle failures as evidence grows, while the latter relies on the LLM to implicitly infer knowledge gaps from the outline alone, providing weak supervision for identifying missing relations and triggering targeted exploration. We present DualGraph memory, an architecture that separates what the agent knows from how it writes. DualGraph maintains two co-evolving graphs: an Outline Graph (OG), and a Knowledge Graph (KG), a semantic memory that stores fine-grained knowledge units, including core entities, concepts, and their relations. By analyzing the KG topology together with structural signals from the OG, DualGraph generates targeted search queries, enabling more efficient and comprehensive iterative knowledge-driven exploration and refinement. Across DeepResearch Bench, DeepResearchGym, and DeepConsult, DualGraph consistently outperforms state-of-the-art baselines in report depth, breadth, and factual grounding; for example, it reaches a 53.08 RACE score on DeepResearch Bench with GPT-5. Moreover, ablation studies confirm the central role of the dual-graph design.
Closing the Loop: Universal Repository Representation with RPG-Encoder
Feb 03, 2026Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art localization performance on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% in localization accuracy on SWE-bench Live Lite. These results highlight our superior fine-grained precision in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
RePrompt: Reasoning-Augmented Reprompting for Text-to-Image Generation via Reinforcement Learning
May 23, 2025Despite recent progress in text-to-image (T2I) generation, existing models often struggle to faithfully capture user intentions from short and under-specified prompts. While prior work has attempted to enhance prompts using large language models (LLMs), these methods frequently generate stylistic or unrealistic content due to insufficient grounding in visual semantics and real-world composition. Inspired by recent advances in reasoning for language model, we propose RePrompt, a novel reprompting framework that introduces explicit reasoning into the prompt enhancement process via reinforcement learning. Instead of relying on handcrafted rules or stylistic rewrites, our method trains a language model to generate structured, self-reflective prompts by optimizing for image-level outcomes. The tailored reward models assesse the generated images in terms of human preference, semantic alignment, and visual composition, providing indirect supervision to refine prompt generation. Our approach enables end-to-end training without human-annotated data. Experiments on GenEval and T2I-Compbench show that RePrompt significantly boosts spatial layout fidelity and compositional generalization across diverse T2I backbones, establishing new state-of-the-art results.
UFO2: The Desktop AgentOS
Apr 20, 2025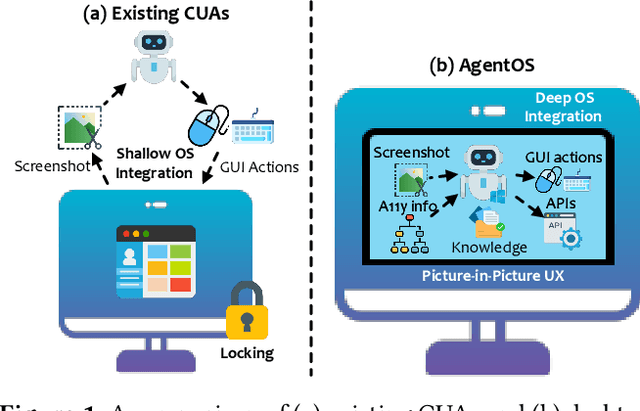
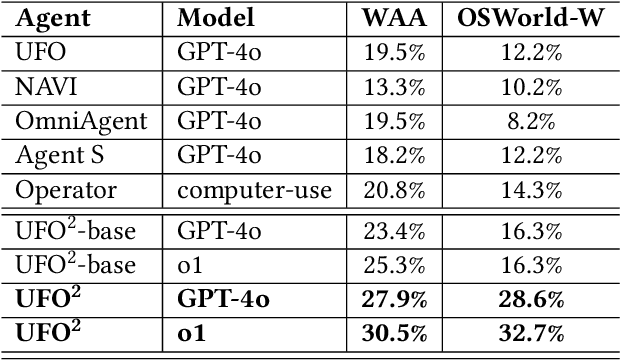
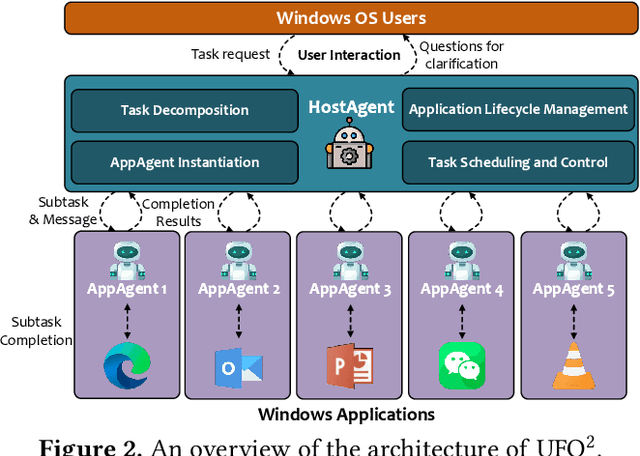
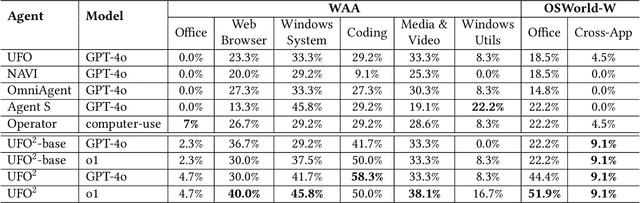
Recent Computer-Using Agents (CUAs), powered by multimodal large language models (LLMs), offer a promising direction for automating complex desktop workflows through natural language. However, most existing CUAs remain conceptual prototypes, hindered by shallow OS integration, fragile screenshot-based interaction, and disruptive execution. We present UFO2, a multiagent AgentOS for Windows desktops that elevates CUAs into practical, system-level automation. UFO2 features a centralized HostAgent for task decomposition and coordination, alongside a collection of application-specialized AppAgent equipped with native APIs, domain-specific knowledge, and a unified GUI--API action layer. This architecture enables robust task execution while preserving modularity and extensibility. A hybrid control detection pipeline fuses Windows UI Automation (UIA) with vision-based parsing to support diverse interface styles. Runtime efficiency is further enhanced through speculative multi-action planning, reducing per-step LLM overhead. Finally, a Picture-in-Picture (PiP) interface enables automation within an isolated virtual desktop, allowing agents and users to operate concurrently without interference. We evaluate UFO2 across over 20 real-world Windows applications, demonstrating substantial improvements in robustness and execution accuracy over prior CUAs. Our results show that deep OS integration unlocks a scalable path toward reliable, user-aligned desktop automation.
VEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model
Feb 26, 2025
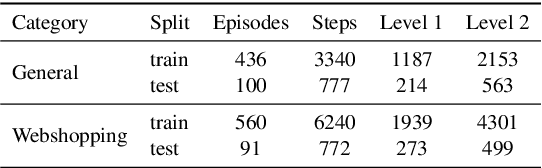
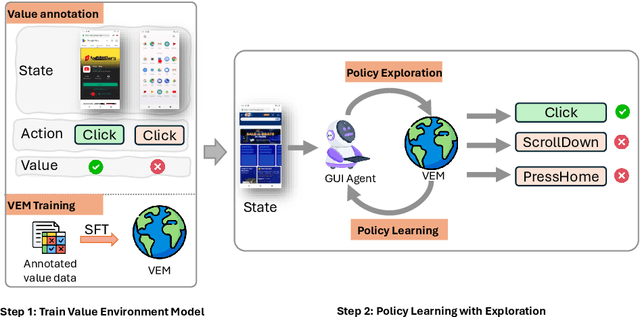

Training Vision-Language Models (VLMs) for Graphical User Interfaces (GUI) agents via Reinforcement Learning (RL) faces critical challenges: environment-based RL requires costly interactions, while environment-free methods struggle with distribution shift and reward generalization. We propose an environment-free RL framework that decouples value estimation from policy optimization by leveraging a pretrained Value Environment Model (VEM). VEM predicts state-action values directly from offline data, distilling human-like priors about GUI interaction outcomes without requiring next-state prediction or environmental feedback. This avoids compounding errors and enhances resilience to UI changes by focusing on semantic reasoning (e.g., Does this action advance the user's goal?). The framework operates in two stages: (1) pretraining VEM to estimate long-term action utilities and (2) guiding policy exploration with frozen VEM signals, enabling layout-agnostic GUI automation. Evaluated on Android-in-the-Wild benchmarks, VEM achieves state-of-the-art performance in both offline and online settings, outperforming environment-free baselines significantly and matching environment-based approaches without interaction costs. Importantly, VEM demonstrates that semantic-aware value estimation can achieve comparable performance with online-trained methods.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.