 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolved Reward Learning for LLMs
Paper and Code
Nov 01, 2024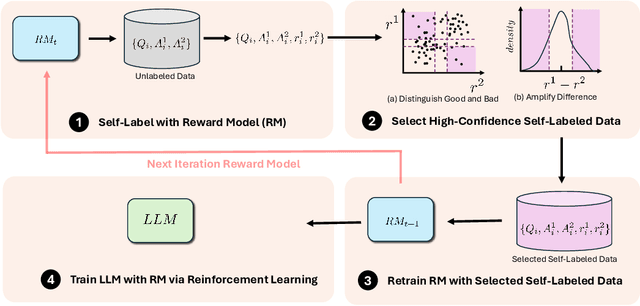
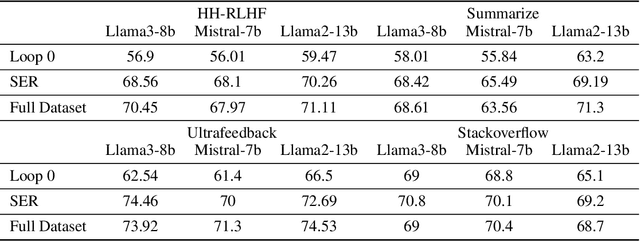
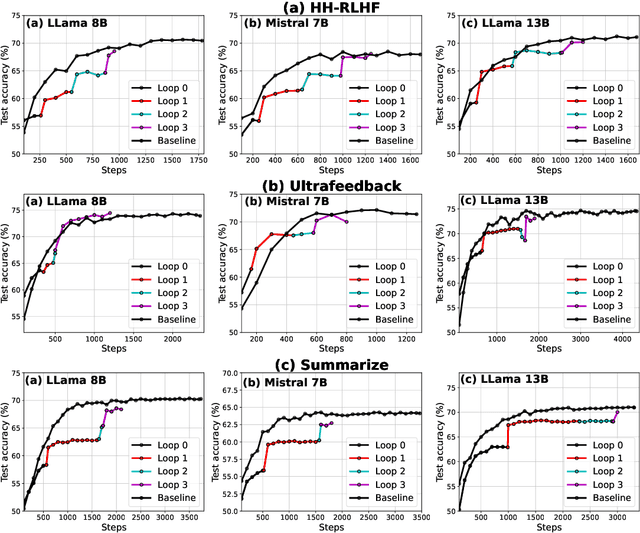
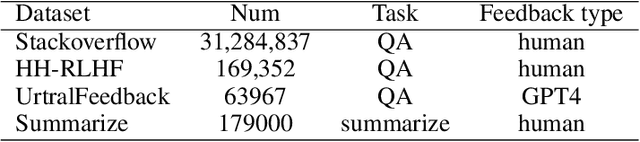
Reinforcement Learning from Human Feedback (RLHF) is a crucial technique for aligning language models with human preferences, playing a pivotal role in the success of conversational models like GPT-4, ChatGPT, and Llama 2. A core challenge in employing RLHF lies in training a reliable reward model (RM), which relies on high-quality labels typically provided by human experts or advanced AI system. These methods can be costly and may introduce biases that affect the language model's responses. As language models improve, human input may become less effective in further enhancing their performance. In this paper, we propose Self-Evolved Reward Learning (SER), a novel approach where the RM generates additional training data to iteratively improve itself. We conducted extensive experiments on multiple datasets such as HH-RLHF and UltraFeedback, using models like Mistral and Llama 3, and compare SER against various baselines. Our results demonstrate that even with limited human-annotated data, learning from self-feedback can robustly enhance RM performance, thereby boosting the capabilities of large language models (LLMs).